




RISC-Vコアが外部メモリーを参照せずに処理できる範囲に
ネットワークの大きさに留める
では低消費電力をどうやって実現したのかを説明しよう。GAP8のベースになるのは、2013年にスタートしたPLUPプロジェクトだ。これはRISC-Vベースのオープンソースなハードウェアを構築するというもので、IoTからHPCまでさまざまな用途に向けたRISC-Vコアとその周辺回路、さらにはソフトウェアまで手がけるものである。

PULP(Parallel Ultra Low Power)プロジェクtpは、チューリッヒ工科大のIIS(Integrated Systems Laboratory)とボローニャ大のEEES(Energy-efficient Embedded Systems)グループが共同で始めたものである
このPULPプロジェクトで提供されるCV32E40P(かつてはRIS5Yと呼ばれていた)コアを9つ統合したものである。
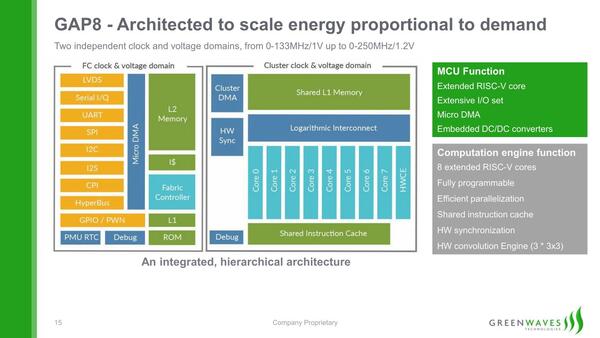
うち8コアが、実際に推論を処理するクラスター部で、残り1コアはSoC全体を制御している(この画像には明示されていない)
もう少し詳細な構造図が下の画像だ。個々のコアはいずれもRV32ICM(整数演算、縮小命令、乗徐算)をサポートした32bit RISC-Vコアである。CV32E40Pはパイプライン段数4段のインオーダーの構成で、効率はともかくとして絶対性能はそれほど高くない。
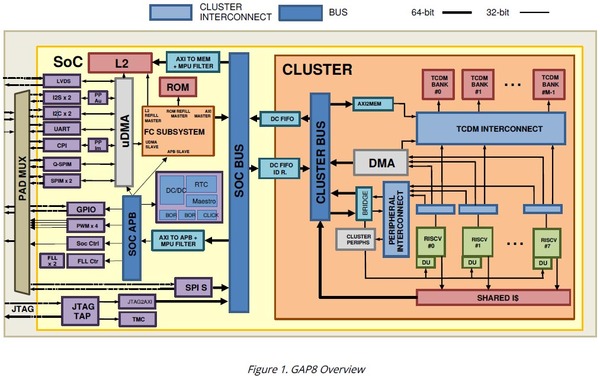
左のSoC部は、いわゆる典型的なMCUのもの。FC Subsystemの中に9個目のRISC-Vコアが搭載されているようだ
画像はGAP8のHardware Reference Manualより抜粋
もちろん上の画像にもあるように、FC(Fabric Controller)側に512KBの2次キャッシュが搭載され、またクラスターの側には16KBのTCDM(Tightly-Coupled Data Memory)がファブリック経由で複数個搭載されている。
クラスター側のコアはTCDMで処理をして、このバックアップとしてFC側の2次キャッシュが利用される格好だ。命令キャッシュとしてはFC側に1KB、クラスター側に4KBが用意されている。
アプリケーションプロセッサーだとしたらこれはかなり少ない方だが、32bitのMCUコアであればこれで十分であろう。ちなみに、SoCの外にHyperBusと呼ばれるI/Fを利用して、SRAMないしフラッシュメモリーを外部に搭載することもできる。
ただこれだけ見ても、なぜこれでAIの推論が高効率に行なえるのかさっぱりわからないだろう。この鍵を握るのが、GreenwavesのGAPflowというソフトウェアである。GAPflowは大きく2つのツールからなる。
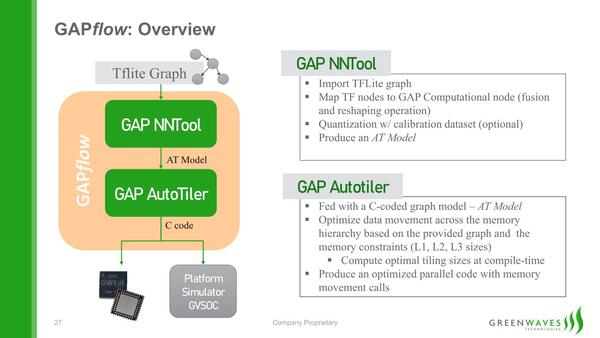
GAPflowにある2つのツール。肝になるのはAutoTilerで、ここがネットワークをGAP8の8つのタイルにうまく収まるように分割することになる
最初のGAP NNToolは純粋にTensorFlow Liteのグラフを読み込み、これを続くGAP AutoTiler(AT)用に独自フォーマットに変換する。この際に量子化(Quantization)を可能なら事前に行なうことで処理負荷を減らす形だ。これそのものは珍しくない。
続くGAP AutoTilerがグラフを分割し、8つのタイル(=8つのRISC-Vコア)が外部メモリーを参照せずに処理できるようなサイズに落とし込むことで、個々のタイルはTCDMだけを参照しながら処理するようになる。
当然外部メモリーの参照が必要なければ処理は高効率に行なえるし、そもそもTensorFlow Liteを利用している時点で巨大なネットワークを動かすことはあり得ないので、メモリーが足りなくなるようなケースもない、というわけだ。
おそらく巨大なネットワークを動かそうとすると、AutoTileをかけた時点でエラーが出て、もっと小さなネットワークにするように勧告されることになるだろう。
その意味ではあくまでエンドポイントAI向けのプロセッサーコアに最適化されていると言えなくもないが、無理に巨大なネットワークを動作させるためにアクセラレーターや外部エンジンなどを突っ込み、複雑な構成になって消費電力やダイサイズが肥大化し、最終的なコストを引き上げてしまうより、RISC-Vコア+HWCE(Hardware Convolution Engine)で収まる範囲にネットワークの大きさを留めさせることで、低コストでエンドポイントAIが実行できるようにするという同社の設計方針は、わりと考えさせるものがある。
Greenwavesはこれに続き、オーディオインターフェースを搭載したGAP9をすでに発表済みである。
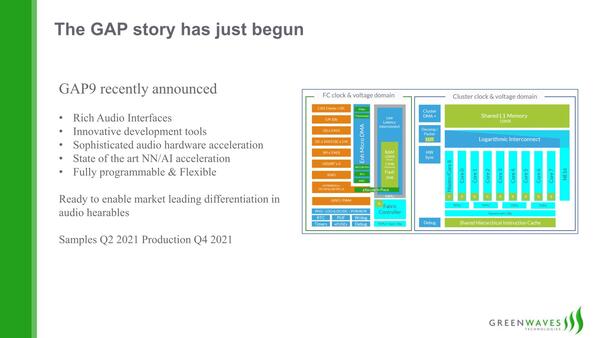
基本的な構成は同じであるが、オーディオを扱う場合、精度の関係でINT8のままだとうまくいかない関係で、おそらくFP16あたりをサポートするものと思われる
この画像では2021年に量産とされているが、現時点ではまだチップが完成していないようだ。ただすでに設計そのものは終わっているようで、GAP9 StoreではeFused(1回書き込みのみのFPGAのようなデバイス)を利用した評価キットが、契約ユーザー向けに出荷可能になっている。
うまくターゲットを絞れば、複雑なメカニズムや突拍子もないアーキテクチャーを使わなくてもAIプロセッサーは実現できる、という良い例かもしれない。
2022年11月9日追記
Greenwaves Technologies社よりGAP9の現状についての連絡をいただいた。それによれば2022年3月からチップを実装した評価用キットを顧客に提供中で、すでに量産ウェハーも上がってきており、これを利用したGAP9のWL-CSPチップの出荷も開始しているとのこと。すでに量産シリコンの品質検証も完了し、2023年第1四半期から出荷予定とのことである。以上、お詫びして訂正する。
※編注:次回の連載記事は、都合により14日23時に掲載予定です。通常より約半日掲載が遅くなりますことをご了承下さい。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























