
レジスターを増やしてスケジューラーの待機時間を減らす
次がバックエンド。こちらは構造的には大きな違いはないが、以下が異なる。
- 整数レジスターは160→192に、浮動小数点レジスターは256→320にそれぞれ増量
- ROB(Re-Order Buffer)は256→320に増量
- FPUはAVX512FとVNNIをサポート
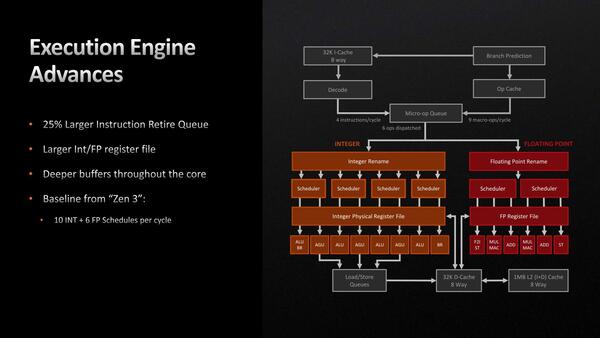
基本的にInteger側にはほとんど変更はない。大きな変更があったのはFloating Point側である
レジスターの増量は、In-Flight(命令を実行可能状態にして、実行ユニットが空くのを待つ状態:実行中の命令もここには含まれる)できる命令数を増やすことが可能になる。レジスターが一杯だと、In-Flight状態として登録できないからだ。
スケジューラーのエントリー数そのものは増えていないが、レジスターを増やしたということは、これまではレジスター数がネックになってスケジューラーがフルに活用できていなかったということと思われる。
ROBの増量もこれと同じである。ROBは命令を実行し終わった後で、その後処理を完了するまで保持をするためのものである。アウト・オブ・オーダーの場合、必ずしも命令の実行順序はプログラムの実行順序とは限らず、しかもある処理結果を別の命令で利用したりする。
あと、結果をメモリーに書き出したりする場合もあるので、それを書き出し終わる(書き出しには時間がかかる)までは命令完了とならない。そこで実行はしたけど完了していない命令を保持するのがROBである。これがあふれると、それ以上命令を実行できなくなるのでパイプラインが一時的に停まることになる。ROBを増やすことで、こうした状況に陥る確率を減らせるわけだ。
それと大きな違いはFPUの構成である。初代Zenの世代でFPUが非対称構成になっており、本来4つのFPUを全部連動させれば256bitのSIMD演算が可能(初代はSSEのみの対応で、256bit幅のAVXは未対応だった)はずながら、FP3がFP1と異なる構成になっている関係で連動できない、という妙な設計思想だった。

Bfloat16のサポート(AVX512_BF16)も追加されている。とはいえ、VNNIもそうだが、このあたりはRyzen向けというよりはEPYC向けということになる
以前この件でAMDのどなたか(誰に聞いたのかは忘れてしまった)に質問したのだが「いやリソースを最適化した結果こうなった」という、あまり明確でない返事が戻ってきた記憶がある。その後、Zen 2でFPUの幅は倍増し、AVXに対応したが、相変わらず非対称構成は変わらずであり、これはZen 3にも引き継がれた。
まだ筆者はZen 4のFPUの構成を確認できてはいないのだが、2組4つのFPUが連動して動作するようになったことでAVX512F(F:Fundamental AVX512の基本的な命令セット)をサポートできるようになったということから考えると、やっとFP1とFP3が対称構成となったのではないかと考えられる。
加えてこのFPUではVNNIのサポートも追加された。VNNIはCascade Lake世代のXeonで搭載されたAVX512の拡張命令で、元はIntel DL Boost(Intel Deep Learning Boost)という名前で説明されていた。実をいうとVNNIは、当初AVX512の拡張として提供され始めたが、これをAVX2にバックポートしたAVX2 VNNIという命令セットも存在している。
VNNIは要するに畳み込み演算を高速に行なうもので、例えば積和演算はAVX512Fならば、
VPMADDUBSW(Multiply and Add Packed Signed and Unsigned Bytes)
VPMADDWD(Multiply and Add Packed Integers)
VPADDD(Add Packed Integers)
この3つの命令を順番に実行することで実現できるが、これをVPDPBUSD(Multiply and Add Unsigned and Signed Bytes) という1つの命令で代替できる。単純に命令数で数えても3分の1になるわけで、これによってAI処理に付き物の畳み込み演算を高速化できる、というものだ。
これを利用することでAI/機械学習処理をAVX512ベースで高速に処理できるという謳い文句であるが、正直言うとインテルがAlder LakeでAVX512そのもののサポートを外しており、AVX2 VNNIのみなので、サーバー向けはともかくコンシューマー向けにAVX512-VNNIを利用したAIアプリケーションがどの程度出てくるのか? はちょっと不明確である。
もちろんZen 4コアはRyzen 7000シリーズだけでなくGenoaベースのEPYCでも利用されるから、こちらで活用の余地はあるとは思うのだが、コンシューマー向けとしてはあまり期待しない方が良いかもしれない。
ただ、Skylake以降の世代で、AVX-512の動作にはペナルティーがあった(AVX512の連続動作をかける場合、最大動作周波数をやや下げる必要がある)のに対し、はっきりと“No frequency impact”と断じているあたりは、絶対性能よりも性能/消費電力比を取った構成と考えられる。
※お詫びと訂正:記事初出時、Alder Lakeに関する記載で一部誤りがありました。記事を訂正してお詫びします。(2022年10月8日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













