




NVIDIAのV100に比肩する性能
Prodigyのパイプライン構造が下の画像である。もちろん分岐予測は必要(でないと動的な判断を入れた瞬間にパイプラインが全フラッシュされる可能性がある)ではあるが、いわゆるフロントエンドはおそろしく簡素である。Schedulerが入るのは、通常のALU以外にベクトルALUが入るためであろう。
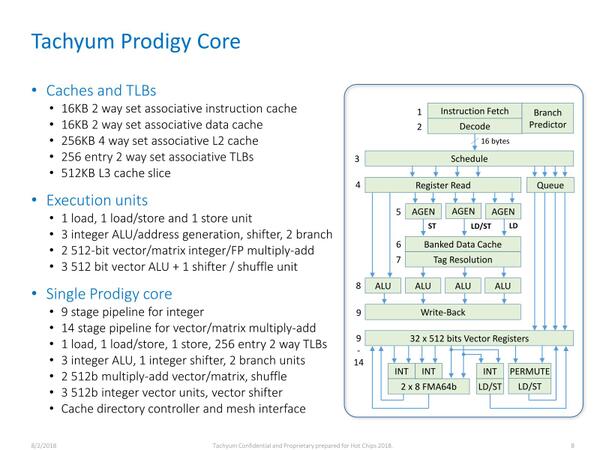
AI向け処理に関しては、むしろメインと分離されたベクトルユニットの方が活用されると思われる。後述するが、FP8をすでにサポートしており、なかなか先見の明がある気がする。INT4が未サポートなのは残念である。とはいえ、2018年の時点でここまで見通すのは難しいだろう
In-Orderで9段というのは結構長めであるが、そもそもVLIWの時点で1段あたりの処理量はかなり少ない。それでも9段にした理由は以下の2つが考えられる。
- 1段あたりの処理を最小にすることで、動作周波数の引き上げを狙った
- キャッシュからのロードに時間がかかることを考慮して、ALUを動かすまでのサイクル数を長めに取った
Tachyumはもう少しProdigyの詳細を公開してくれている。まず命令フェッチ段は下の画像の通り。
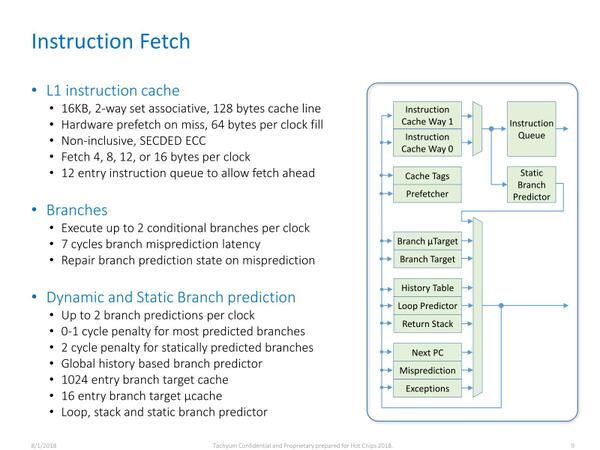
Cache Lineが128Bytesというのは、この手のプロセッサーとしてはかなり長い気がするが、16Bytes Bundleで8 Bundle分と考えればこんなものかもしれない
分岐予測はVLIWとしてはかなり充実している気はするが、昨今のOut-of-Orderを実装したCPU(それこそAlder LakeやZen 3など)に比べればかなりシンプルではある。むしろペナルティーの少なさが特徴的で、分岐ミスのペナルティーが7サイクルというのはIn-Orderならではだろう。といっても、9サイクルのパイプラインで7サイクルなので、ほぼパイプライン・フラッシュに近いという言い方もできる。
ALU側のパイプラインは下の画像の通り。投機的なデータロード/ストアは、実際にそれが必要になるまでホールドされるのは、In-Order型のパイプラインとしては当然ではある。

ベクトル命令は完全にALUパイプラインと分離されているのも、実装を考えれば妥当である
プロセッサーの構造を複雑にして、エリアサイズ増大など複雑なメカニズムを搭載するのではなく、素直にIn-Order型の処理で済ませるような実装になっているのは、むしろ自然だとは思う。もともとIPCを無理に引き上げるよりも、多数のコアを同時に走らせることで効率よく処理する構成なので、このあたりはトレードオフとして妥当な実装に見える。
キャッシュは、L1(16KB)+L2(512KB)がコアごとにあり、L3が共有32MBとなっている。L3がExclusive Cache(排他的キャッシュ)なのは、Prodigyの使い方ではコア間にまたがって共有するようなデータがあまり多くないことを考えれば妥当に思える。
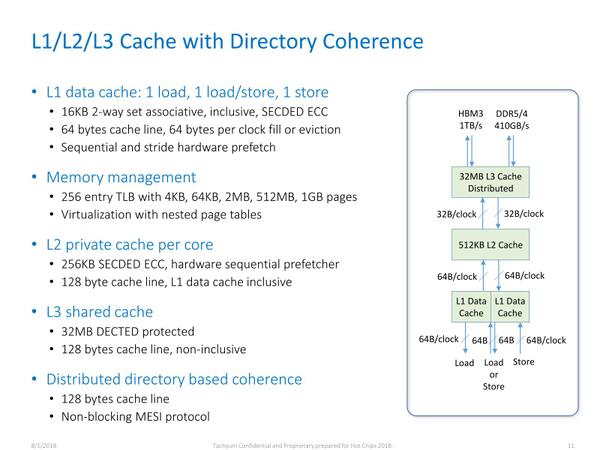
キャッシュの概要。左側の説明ではL2が256KBになっているが、これは512KBが正確の模様
64コアで32MBなのでコアあたり512KBという計算で、これをInclusive Cache(包括的キャッシュ)にしたら全然意味がなくなってしまう。その意味でもL3が排他的になっているのは必然だったともいえる。
演算性能のメインとなるのがベクトルユニットである。512bit幅のユニットで、MACなら2演算/サイクル、単純な算術演算なら3演算/サイクルが可能、というのはこの手のものとしてはかなり高性能(AVX512並)である。

ベクトルユニットの概要。今ひとつ、右上の128TFlopsの根拠がわからない(4bitデータ型のサポートはProdigyにはないはずなのだが)
FP64でMAC演算すると、1サイクルあたり8×2×2=16Flopsとなる。4GHz駆動ならばコアあたり128GFlops、これが64コアなので8TFlopsという計算になる。
オークリッジ国立研究所に納入されたFrontierで動くAMD Instinct MI250Xが1枚あたり45TFlops、つまりダイ1つあたり22.5TFlopsなことを考えればやや見劣りするという言い方もできるが、2018年時点で言えばNVIDIAのVoltaベースのV100がやはりFP64で7.8TFlopsだったことを考えれば、V100に比肩する性能を叩き出す計算になる。
これを支えるインターコネクトの構成が下の画像だ。メモリーコントローラーは全部で8chあり、そこからメッシュの形ですべてのコアに対して1clock/hopでアクセスが可能になっている。

性能と消費電力、コストを考えるとHBM3を載せるのは非現実的だとは思う。DDR5では1本のDIMMで2ch動作することはこの構造に盛り込まれていないようだ。2018年の時点でそこまで予見するのは不可能だっただろう
ここで見るとHBM3に関してはあまり考えていないというか、DDR4/5のキャッシュみたいな使い方になっている。実際DRAM cacheないしMemory Regionの2つというあたりは、少なくともアプリケーションからこれを細かく制御する使い方は考えていないようだ。
可能性としては、広帯域が必要となるアプリケーションと、通常帯域で足りるアプリケーションを分けて、別のメモリーアドレスに割り振るといった使い方も可能だとは思うが、どこまで現実的かを考えると難しい気もする。
最後が肝となるソフトウェアである。一応GCCやLLVM、Linux/FreeBSD、ドライバーなどはすべてTachyumが移植を行ない、一方QEMUなどに関してはエミュレーション動作でカバーすることになっている。とはいえこの時点ではまだコンパイラの出来などを議論するには時期尚早といった感じではある。

FreeBSDの移植、というあたりがいかにもである。個人的にはProdigyの上でOSが稼働する必要はあるのか疑問ではあるのだが、AIアクセラレーターではなくユニバーサルプロセッサーを称する以上、OSやミドルウェアを動かす必要があると考えたのだろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















