




PowerViaが解決すべき問題点
こうしてみるとPowerViaは確かに優れているのだが、その一方で以下のような問題もある。
そもそも電源ラインに関しては、ベースとなるSiliconを貫通する形で電極を形成する必要がある。また厚みも当然薄くしないといけない。
結果、作り方がまったく変わることになる。従来はシリコンウェハー(デバイスウェハー)の上にまずフロントエンドの回路を構築し、その上に配線層を構築する形だったが、PowerViaではまずシリコンウェハー(キャリアウェハー)の上に信号配線層を積層、ついでフロントエンドを積層し、最後に電源配線層を積層することになり、これまでとは異なった製造方法が必要になる。
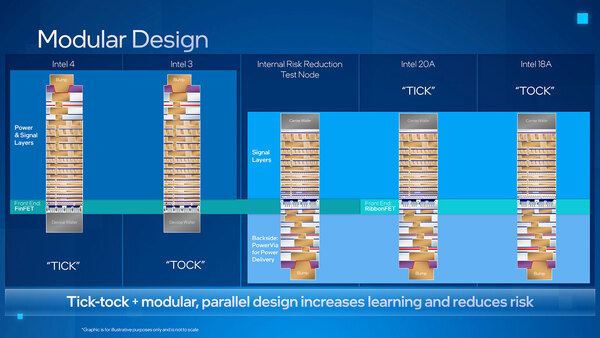
PowerViaの構造
従来は、外部への信号はパッケージの一番上(上の画像の左側で言えば、一番上の“Bump”という箇所)を経由して接続されていた。Flip Chip Packageというのは、つまり上の画像の構成を上下逆にしてパッケージに載せるという格好であった。ところがPowerViaの場合、ダイの上下両方にBumpが来ることになる。
上の画像の右側で一番上(Carrier Wafer)にはBumpが形成されていないが、もし外部の信号を底面(電源部のBump)に引き回すとしたら、つまり信号配線層から電源配線層まで貫通する配線が別途必要になる。これをどう解決するつもりなのか、まだ見えない。
従来は、一番発熱が多いフロントエンドの真裏にシリコンウェハー(デバイスウェハー)があり、デバイスウェハーを経由して放熱が容易だった(だからこそ、ダイを削って放熱を改善するという恐ろしい技が可能だった)。
ところが今回フロントエンドはダイのちょうど中央に位置することになり、放熱の効率が悪化する可能性がある。普通に考えれば電源配線のメタル層を使って放熱することになると思うが、だとすると上の画像の底面のBumpとヒートスプレッダが(薄い絶縁材を挟んで)接触する位の配慮が必要になるが、それが可能かどうかわからない。
このあたりの問題点をIntel 20Aが量産に入るまでにどう解決するつもりなのか、楽しみである。
Intel 4とIntel 20Aはインテル社内専用のプロセス
さてそれはそれとして、プロセスの割り当てがおもしろい。現在の予定では、Intel 4はMeteor Lakeとネットワーク向け製品に、Intel 3は将来のXeonにそれぞれ利用するとし、Intel 20AはMeteor Lakeのみ。Intel 18AではLunar LakeやGranite Lake(あえるいはその次)を量産するというロードマップが立てられている。

2023年後半ということで言えば、時期的にはEmerald Rapidsになりそうな感じではあるが、量産開始≠出荷開始という現状を考えると、Emerald RapidsはTSMCで、次のGranite Rapidsという可能性もある

なんとなく今からIntel 20Aが可哀想な子扱いになっている気が……
どうもIntel 4、それとIntel 20Aは「実験的ノード」という扱いに近いようで、そもそもファウンダリー・サービスのメニューに入っていない。ではそのファウンダリー・サービスのロードマップは? というのが下の画像だ。

ここにTower Semiconductorの話まで入っていろいろごちゃごちゃになっている
のっけからIntel 16という初耳のプロセスが登場しているが、これは14nm(14nm+なのか14nm++なのか14nm+++なのかは不明)をベースにした車載向けのプロセスである。いわば既存プロセスの再利用という扱いだ。これに加え、Intel 3が2023年後半に、Intel 18Aが2024年後半に予定されている。つまりIntel 4とIntel 20Aはインテル社内専用のプロセスとなるわけだ。
ただそのわりには採用製品がそれほど多くない(少なくともXeonとIntel Arcの採用が現時点で明言されていない)というのは、この2つのプロセスはある程度困難なことが予想されており、ここでトラブルの洗い出しを済ませたうえで改良されたIntel 3/Intel 18AをXeonやファウンダリー・サービスで提供するのかもしれない。
意外に(というのも失礼だが)堅実な策を取ったという気もするのだが、かつての14nm(初代)や10nm(初代)のように、修正に1年以上かかったりしないと良いのだが、と思わざるを得ない。
※お詫びと訂正:写真に対する説明に誤記がありました。記事を訂正してお詫びします。(2022年6月4日)
IDM 2.0は新世代のプロセスが出ても
引き続き旧世代のプロセスを生産していく仕組み
ところでGelsinger CEOは就任直後からIDM 2.0を標榜したわりには、なにが2.0なのかがさっぱりわからなかったのだが、今回もう少し明確な定義が出てきた。
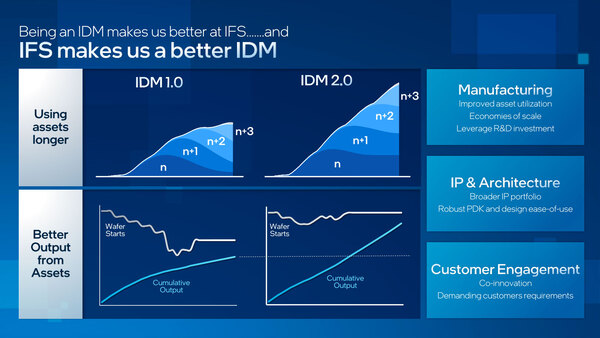
IDM 2.0のターゲットになるのは、当然ファウンダリー・サービスで提供される、つまりIntel 16やIntel 3/18Aで、今のIntel 7やIntel 4/20Aなどは対象外と考えられる
従来では、例えば22nmプロセスが利用可能になった時点で32nmプロセスを使ったCPU製造はフェードアウトしていった。もちろんその後はチップセットの製造に使われたが、出荷量そのものは減っており、ついで14nmプロセスが実用になった時点でチップセットも22nmに移行し、32nmを使う製品はごくわずかになった。
そんな感じで、せいぜいが最新プロセス+2世代程度しか利用されないのがこれまでのインテルのやり方、言い換えればIDM 1.0だった。もちろん一部組み込み向けなどで長期供給に向けて完全にラインを撤廃はしないものの、そうした古いプロセスに関しては一ヵ所に集約し、残りのファブは最新プロセスに転換するという形でファブの再利用を行なっていたわけだ。
ところがIDM 2.0では、今後新世代のプロセスが出ても、引き続き旧世代のプロセスが継続して生産されることになる。ファウンダリー・サービスの顧客は必ずしも最新プロセスが必要とは限らないので、そうした顧客を多く獲得することで、長期にわたって古いプロセスを提供し続けるという戦略だ。
一般論として、ファブは運用を開始して3年~長くても5年程度で設備投資を償却し終わる。すると、後は製造に利用する資材の原価だけで製造できるので、財務上も非常に美味しいことになる(もっともこれも10年や20年を超えると、今度は製造設備がぼちぼち壊れ始めるので、永遠に続くわけではない)。なので、いかにそうしたプロセスを魅力的にして、顧客に長く使ってもらえるかがIDM 2.0の鍵になる。このあたりの損得勘定は、製品ラインナップの話とも絡んでくるので、次回もう少し説明しよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















