




3次元アクセスが可能なプロセッサー
肝心のプロセッサーのアーキテクチャーであるが、確かにSIMDともVILWとも言えなくもないが、そうした分類の外にある独特な構成である。
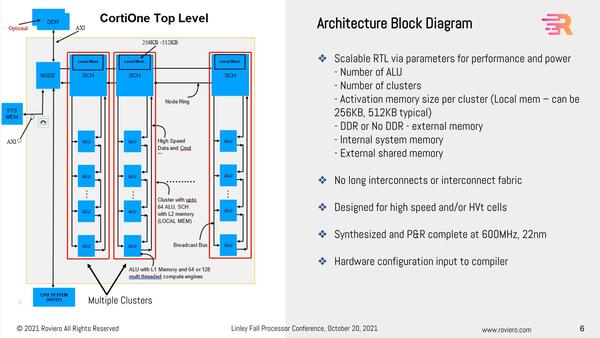
プロセッサーのアーキテクチャー。おもしろいのはこのIPがLow Powerではなく、High Speed/High Vt Cellを使ってデザインされていることだ
まずALUが縦に、それもディジーチェーン式につながっているのが特徴である。赤い枠で囲われた単位がクラスターと呼ばれ、そのクラスターには最大64個のALUが搭載できる(ここはユーザーが自由にカスタムできる)し、そのALUにはBroadcast Busの形でスケジューラーから接続されているわけで、その意味ではSIMDである。
つまりスケジューラーがある命令を発行すると、それがBroadcast Bus経由ですべてのALUに伝達され、一斉に処理を行なうことになるからだ。64個のALUなら64-wide SIMDと言えなくもないのだが、大きく異なるのはデータはディジーチェーン式になっていることだ。
つまりALU1の結果がALU2に入り、その結果がALU3に入り……と続くわけで、一連の処理が一通り終わるまでN(N=ALUの数)サイクルかかることになる。しかもディジーチェーンなので、最初の1つのデータ処理が終わるときには、続くN-1個のデータが処理中ということになる。この仕組みは、汎用のSIMDというよりは限りなくDSPなどに近い。
また後で出てくるが、上の画像にあるようにシステム全体では複数のクラスターがある(その数も自由に変更できる)。この複数のクラスターは、それぞれ別の命令を実行できる。この観点で言えばVLIWに近い。あえて言うならVLIW DSPとでもいうべきなのだろうか?
この構成でもう1つ特徴的なのは、“No long interconnects or interconnect fabric”である。つまり複数のクラスターで連携させて処理する仕組みは取らないことだ。あくまで1つの処理は1つのクラスター内で完結させるという原則を貫いている。だからこそ少ないローカルメモリーでも足りる、ということなのだろうが。
ところで先に3D data structure addresingという話をしたが、なにを意味しているのか? というのが下の画像だ。

ここで横軸(例えば2×2×1024で言えば1024の部分)は、それぞれの層のネットワークの数である。最初はRGBなので×3だが、ネットワークの数としては1つである。それが次の層では40個に、その次が80個に、以下300/800/1024個に増えていくわけだ
一般論としてニューラルネットワークでは最初のうちこそデータ量が多くなるが、そこから急速に畳み込みでデータが集約されていく結果として、ネットワークの層あたりのデータは減るが、その代わり畳み込みの処理がだんだん深くなっていく。
上の画像の例で言えば、最初の層は128×128×3だが、最後の層は2×2×1024という格好になる。従来のやり方は、これを1次元アドレスに展開して処理するのだが、すると必ずしもデータが連続アクセスできないという問題がある。
これを解決するために、メモリーの2次元アクセス機能を搭載するものもあるが、最初の層では2次元アクセスが有効だが、最後の層ではあまり意味がないのは理解できるかと思う。そこでこれを3次元アクセスできるようにしたというアイディアは素晴らしい。
ただその実装を見ると、“Runtime Instruction Fork”なる聞いたこともない概念が登場しており、本当に3Dのアドレッシングが可能なのではなく、1Dないし2Dのアドレッシングモードを持つ命令を複数個自動生成して実行することで、見かけ上メモリーの3Dアクセスを行なうというあまり例のない実装になっている。

“fork”というあたり、CISC→RISCの内部変換や、古のCrusoeのCode Morphingなどともまた異なる実装に見えるのだが、果たしてどういう意味なのか?
もっともこれ“fork”という言葉の使い方の意味が不明確なのであって、例えば
C=A+B
という命令を
Load A
Load B
Add A+B
Store C
という具合に単純に分解してるだけ、という可能性もある。現状特許出願中ということもあってか、もう少し時間が経たないとこのあたりの詳細は公開されそうにない。ただこれがどの程度効果的なのかは今ひとつはっきりしないが、伝統的なVLIW/SIMDではこうしたデータの扱いが得意ではなく、効率が悪化するのはその通りだ。
ところでクラスターはどう使うのか? だが、Rovieroの説明では、ネットワークの層単位でクラスターに割り振る場合と、1つのネットワーク層を複数のクラスターで分割処理する場合の両方がサポートされる。このコントロールは全部コンパイラで行なえるようになっているという。

クラスターは、ネットワークの層単位で割り振る場合と、1つのネットワーク層を複数のクラスターで分割処理する場合の両方をサポートする。問題はこれをコンパイラがうまく割り振りできるかどうか、ではないかと思う
こういう構造なので、長いインターコネクトは存在せず、クラスター同士をつなぐノードリングが唯一「相対的に長いかな」という程度。ただこちらもリングバス構成なので、(実際の配置配線の際のレイアウト次第ではあるが)あまり長い配線にはならないだろう。その意味では、FPGAなどに実装する際にも効率の良い配置配線が可能になりそうだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























