




MAC数の0.0468倍がフレームレートになる性能
クロックは22nmで600MHz、14nmで2GHz超
気になるのは性能であるが、FPGA上で62.5MHzで動かした構成を400MHz相当に正規化したものだが、例えばResNet-50だと256MACで19fps、1024MACで58fps、9216MACで440fpsといったところである。

問題はむしろ「なぜ400MHzで動かさないのか?」である。講演ではこれに関する説明は特になかった
ややわかり難いのでグラフにしてみたが、綺麗にMAC数に比例する。近似値で言えば、例えばResNet-50の場合はMAC数の0.0468倍がフレームレートになっているので、60fpsが欲しければ1282MACほど用意すればいい計算になる。ちなみにレイテンシーの方も、ほぼMAC数に逆比例する形で減少しており、このあたりはアプリケーションで必要とする処理性能に合わせて調整がしやすい格好だ。
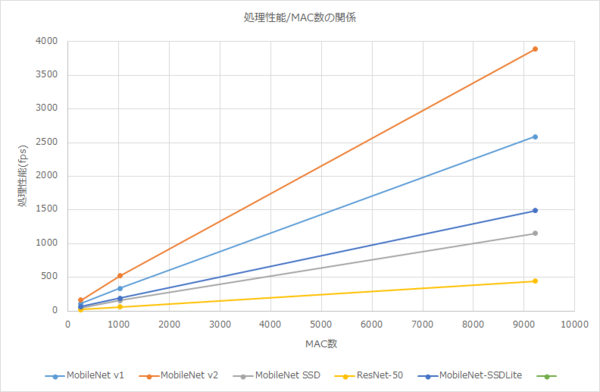
FPGA上で62.5MHzで動かした構成を400MHz相当に正規化したグラフ
実機のデモとしては、引き続き62.5MHz動作のままで10個のFPGAを接続してのデモも行なわれている。この構成では合計で10万2400MACの計算になっており、結構な性能であるのは間違いない。もちろんCloud AIクラスに比べるとだいぶ落ちるが、Edge AIやEndpoint AI向けではピーク性能よりも性能と消費電力、あるいは回路規模とのトレードオフになるわけで、そのあたりのバランスの良さを狙ったものと考えればいいだろう。

気になるのはFPGAになにを使っているかである。評価ボードから見ると、Virtex-7クラスに見えるのだが……
22nm(おそらくはTSMCの22ULP)だと600MHz駆動で100mm2とやや大きめだが、14nm(SamsungかGlobalfoundries)に移行すると40mm2で、2GHz動作を超えるという。この構成では、もう上の画像にある評価システムの性能を超える計算になるわけで、FinFETプロセスを使うケースなら十分Endpoint向けに組み込める計算になる。
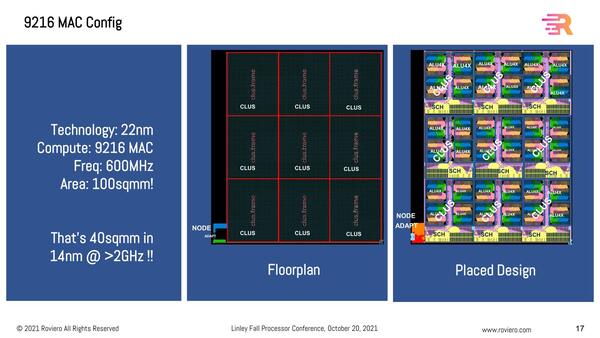
ただTSMC 22ULPから例えばSamsungの14LPPに移行しても、エリアサイズはここまで劇的に減らない気がするのだが、説明では9216MACの場合だとしていた
RovieroはすでにIPとコンパイラに加え、OpenCV経由での画像分類/物体認識/超解像/セグメンテーション、それと画像処理(ノイズ削減、圧縮、タグ付けなど)に向けたサンプルアプリケーションも容易しており、同日出荷可能としている。
ターゲットとしてはまずは監視カメラとかスマートカメラの類であろう。なんというかかなりトリッキーなアーキテクチャーのプロセッサーで、それもあってエリアサイズが大きめなのが気になるところ。あとはコンパイラの品質がどの程度か? というのも懸念事項の1つだろうか。おもしろい実装だとは思うのだが、無事にビジネスにつながるといいのだが。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












