




RISC-VはSIMD演算ではなくベクトル演算
違いはレジスター長が固定かどうか
では、RISC-Vをどうやって実装したか、というのが今回の話だ。もともとRISC-VではRVV(ベクトル拡張)についてずっと議論が進んでいた。議論が進んでいたというか、いろいろ揉めていたというのかは微妙なところであるが、2019年6月にはv0.7.1がリリースされており、ところがv1.0で仕様が固定(Frozen)されたのは2021年9月、というあたりからけっこう議論が錯綜したのがわかる。
この仕様策定までの期間がどうしても長くなるのがRISC-Vみたいな仕様をオープンな場で議論する方式の欠点ではあるのだが、それはともかく。
RISC-Vの場合、SIMDではなくベクトルとされている。最大の違いはレジスター長が決め打ちでないことだ。例えばx86系で言えば、1つの演算で処理できる最大のサイズはMMX/3DNowが64bit、SSEが128bit、AVX2が256bit、AVX512が512bitと決められている。要するに1回の命令で処理できるSIMDレジスターは1つであり、1024bit分のデータを処理したければMMX/3DNowで16回、SSEで8回、AVX2で4回、AVX512でも2回命令を発行する必要がある。
これに対してベクトルの方は、1つの命令で処理できるデータ量が固定長ではない。したがってEsperantoのET-Minionのように、それこそ最大で512回の演算を処理できるようなものも登場してくる。ET-MinionはRVVとは異なる独自実装であるが、RVVも基本的なアイディアは同じであり、実際のベクトルレジスターよりも長いデータを取り扱える。ArmのSVE(Scalable Vector Extention)や、最近登場したSVE2も考え方はよく似ている。
RVVそのものは、SIMD演算と同じく大量の数値演算に向けた拡張であって、必ずしもAI/機械学習向けではない。

これまでRISC-VにはSIMD/Vector系のデータ処理に向けた命令が存在しなかったので、その意味では最初のターゲットは「汎用」に向けられている
むしろ直接的なターゲットはArmということもあり、Armの64bit SIMD命令であるNEONを利用したアプリケーションを、簡単にRVVに移行できることをアピールしていたりする。

ちなみにこのトランスレーターはSiFiveが提供するもので、RISC-Vである
さて本題のAI向けの話だ。SiFiveはAI/機械学習向けにSiFive Intelligenceと呼ばれるソフトウェアとハードウェア(IP)のパッケージを提供している。
これまでは、例えば畳み込みを高速に処理するアクセラレーターだったり、もっとプリミティブに乗加算を高速に行なうハードウェアを入れたり、といった形でAIに対応と称することが多いが、同社はもう一歩先の、例えばTransformer(2017年に発表された多層ニューラルネットワークのモデルで主に自然言語処理に利用されている)や、いわゆるRecommendationなどに利用されるモデルは通常の畳み込みニューラルネットワークよりももっと複雑であり、こうしたモデルをより高速に実行できるように工夫しているのが特徴だ。
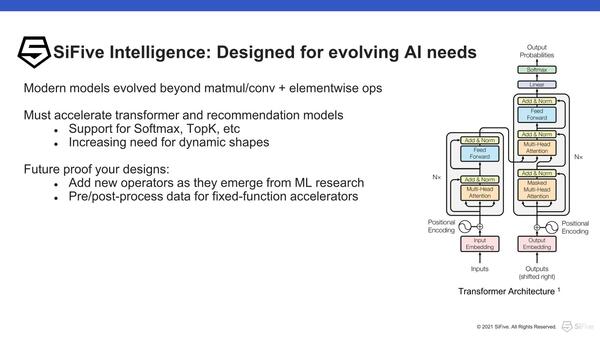
右の図はTransformerモデルのアーキテクチャー。2017年にGoogleのAshish Vaswani氏らによって発表された“Attention Is All You Need”という論文の中で示されているものである
もちろんこれはRVVの範疇ではカバーできないので、SiFiveはカスタム命令拡張(RISC-Vでは独自に命令を拡張することを許しており、SiFiveもこれを利用した形)を使って独自のAI処理命令を追加して、こうした複雑なモデルへの対応を行なっている。こうしたモデルでも、従来の乗加算や畳み込みの作業がなくなったわけではないので、こうしたものはRVVを利用して処理する格好だ。
冒頭に書いたX280は、このSiFive Intelligenceを最初に実装したプロセッサーIPである。ベースとなるのは同社のU74という、インオーダー構成ながら2命令の同時実行が可能なパイプライン8段のプロセッサーで、SiFiveによればCortex-A55と同等以上の性能を持つとするプロセッサーである。x86で言うなら、Atom系列に相当すると考えればいい。
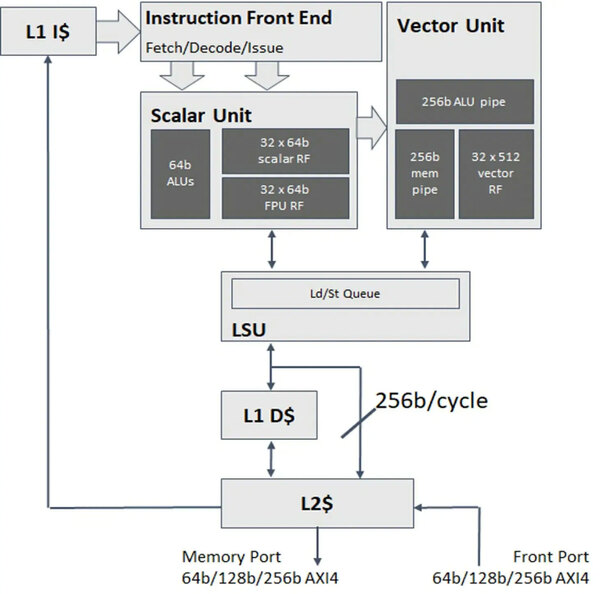
Instruction Front EndとScalar UnitがU74のものである
このU74コアに、256bit幅のベクトル演算ユニット(ただしベクトルレジスターは512bit幅)を組み合わせる形でRVVを搭載している。これにあわせ、ベクトル利用時は1次データキャッシュをバイパスして2次キャッシュに対して直接256bit/サイクルでのアクセスが可能な仕組みを追加したのがX280というわけだ。
またRVVはFP32/FP64以外にBF16/FP16やINT 8/16/32/64のデータ型をサポートしており、AIなどで多用されるINT 8/BF16/FP16を利用しての高速化が可能という形になっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ












とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












