
マイクロソフトがMilan-Xのベンチマーク結果を公開
さて、これに絡んでもう少し性能の話をしたい。AMDのイベントに合わせ、マイクロソフトはAzureCompute Blogでこんな記事を掲載した。すでにマイクロソフトもこのMilan-Xを受け取っており、それどころかこのMilan-Xを利用するAzureのインスタンスをプレビュー扱いで利用可能としている。
それだけでなく、実際にそのMilan-Xをベースにしたインスタンスと、すでに提供中のMilanベースのインスタンスとの間で性能を比較している。ちなみにこのMilan-X、製品名称はEPYC 7V73Xと説明されているが、64コア製品という以外の詳細スペックは公開されていない(いずれAMDから説明があると思われるが)。
まず下の画像がNUMAノード同士での通信のレイテンシーを測定したMicro Benchmarkである。おそらく同一ダイ上であってもNUMAのレイテンシーは半分に、ダイを挟む場合でも42%のレイテンシー削減とされる。
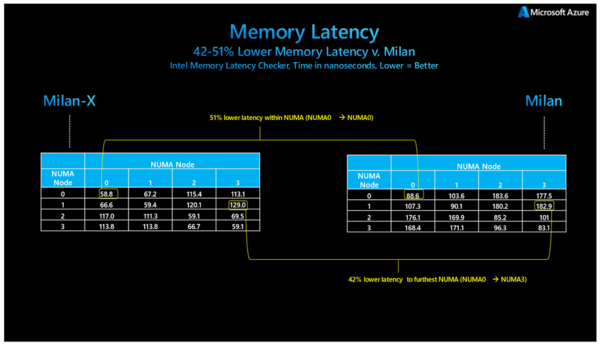
どういうNUMAノードの切り方をしているのかがわからないが、どうもNUMA 0/1と2/3はそれぞれ同一のダイ上にあり、ただしNUMA 0/1と2/3は別々のダイになっている感じだ。おそらくはIntel Memory Latency Checkerが自動認識しているものと思われる
要するに、通信量が多くてMilanのL3キャッシュだけではあふれる(=メモリーアクセスも発生する)ような場合でも、Milan-XならL3増量によりメモリー利用量が減り、結果としてレイテンシーが削減できるということだろう。
下の画像はMilan-XでStreamベンチマークを実施した場合の結果である。

実効帯域が1.8倍に増えた計算になり、2 Socketのノードではおおむね630GB/秒の帯域が利用できるという試算もなされている
ちなみに実行コマンドは以下のとおり。
./stream_instrumented 400000000 0 $(seq 0 4 29) $(seq 30 4 59) $(seq 60 4 89) $(seq 90 4 119)
バッファサイズとして約400MB(正確に言えば381.47MB)を指定しており、これは従来なら1つのダイに収まるL3の容量をはるかに超えている。
したがって、本来であればDDR4-3200 DIMM 8ch分の帯域である200GB/秒に収束するはずなのだが、Milan-XではStreamのTriadで358GB/秒と、ほぼ1.8倍の帯域に達しているのはL3容量が大幅に増えた効果とされている。
ここからは実アプリケーションの結果だ。まずANSYS Fluent 2021 R1という流体解析のツールを、VM1個で実施した場合の性能で、HBv3(Milan)とHBv3(Milan-X)を比較すると、5割前後の性能向上になる。
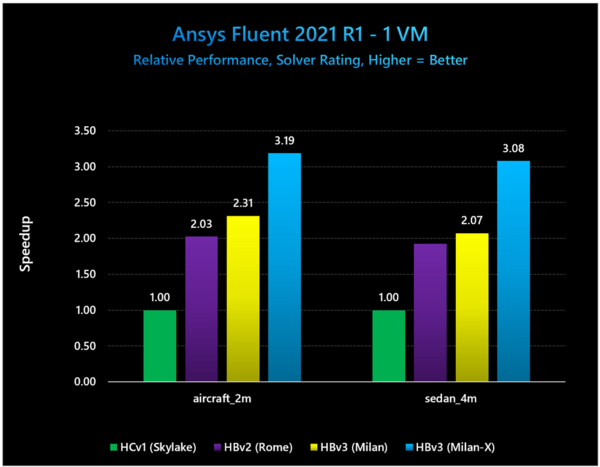
2M個の要素を持つ飛行機、それと4M個の要素を持つ自動車(セダン)での解析速度を、SkylakeベースのHCv1を基準として示したもの。ちなみにsedan_4mのHBv2は1.92倍ほどになる
ではもっと要素数が増えた場合は? というのが下の画像で、しかも同時に動かすVMの数を1から16まで順次増やしていくと、8VMあたりが最高性能になり、16VMではむしろ性能差が縮まる結果になった。
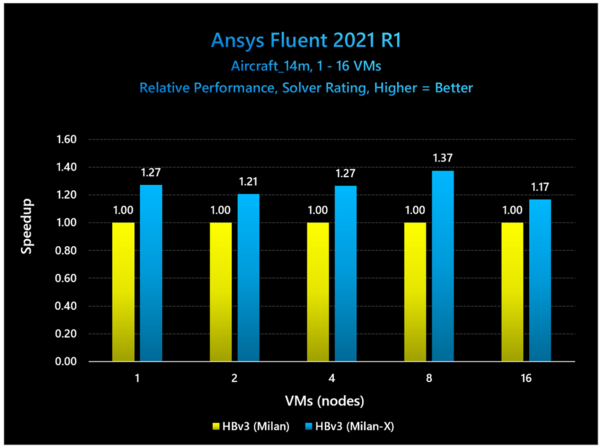
これはMilan vs Milan-Xでの比較。要素数が14M個に増えるので、利用するメモリー量も当然増える
さらに要素数とVMを増やすとどうなるか? というのが下の画像だ。おもしろいのは、VMの数が少ないと性能差はそれほど大きくない。差が大きくなるのは32~64VMあたりだが、128VMになるとまた差が縮まる方向にある。
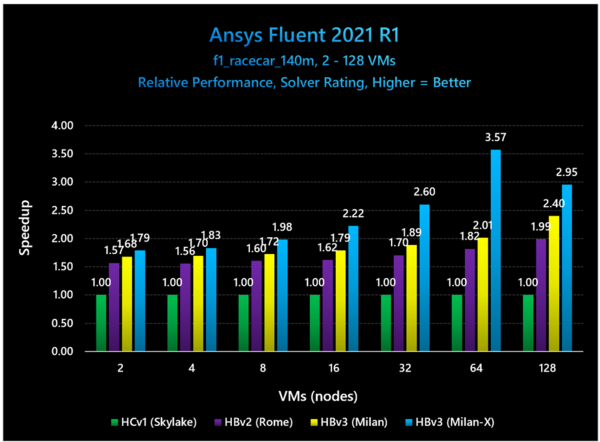
F1のレーシングカーのモデリングでの例。要素数は140M個
このグラフがわかりづらいのは、トータルの処理性能ではなく、それぞれのVM数における性能差になっていることだ。つまり絶対的な性能で言えば、2VMよりも4VM、8VMとVMの数を増やした方が性能が上がる。ただその上がり方が、Milan-Xが一番高いという話である。
最後は、さらに要素数の多いケースである。こちらではMilanとMilan-Xでの性能差はそれほど大きくないが、それでも128VMでは15%ほどの改善がみられる。
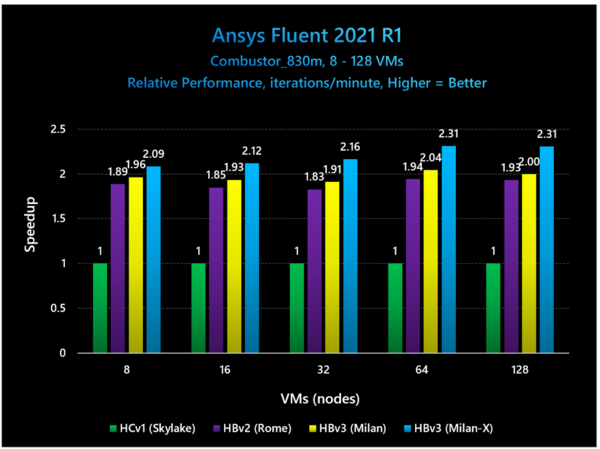
こちらはガスタービンの燃焼器(Combuster)での例。要素数は830M個に達する
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













