




新年早々の1月6日、DEC→AMD→SiByte→P.A.Semi→Apple→AMD→Intelと放浪の旅(?)を繰り返していたJim Keller氏がPresident兼CTOとしてTenstorrentに入社したことが報じられた。
CTOになったとはいえ、そもそもの入社は2020年12月で、まだ入社して1ヵ月になるかならないかという期間なので、今の時点でTenstorrentのテクノロジーになにかしらの影響を与えているかと言えばほぼ0だとは思うが、それはともかくとしてKeller氏を引き寄せるようなおもしろいモノがTenstorrentにはあった、ということの傍証ではあるかと思う。

TenstorrentのAIプロセッサー「Grayskull」
推論と学習、両方のAIプロセッサーを開発する
Tenstorrent
Tenstorrentは2016年3月にカナダのトロントで創業したメーカーである。創業者はLjubisa Bajic氏(CEO)、Milos Trajkovic氏(Director Hardware Engineering)とIvan Hamer氏の3人である。実はこの3人、いずれもAMD(Bajic氏はDirector, IC Design/Architect、Trajkovic氏はFirmware Design Engineering Manager、Hamer氏はConsulting Software/Embedded Engineer)を同時期に辞職して創業した形である。
創業はそんなわけでトロントであるが、現在はテキサス州オースチンにもオフィスを持っており、両方合わせておおむね70人(2020年8月現在:2020年4月には50名超だった)の人員を抱えている。
そのTenstorrentであるが、Inference(推論)とTraining(学習)の両方を視野に置いている。そしてすでにJawbridgeとGrayskullという2種類のチップを製造しており(これはどちらもInference向け)、続くTraining向けのWormholeもすでにテープアウトが完了したことを発表している。
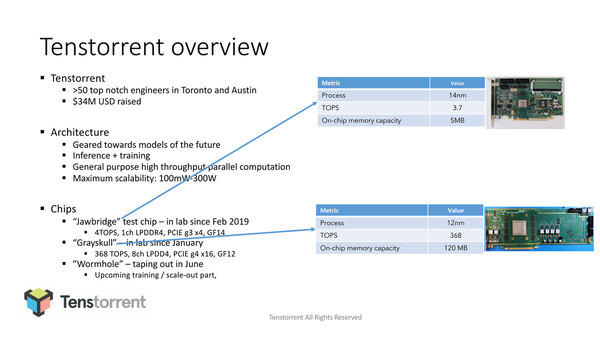
コード名の由来は1982年にMattel社が発売した“Masters of the Universe”シリーズのコミック&アクションフィギュアから始まるシリーズのようだ。舞台となる惑星EterniaにはCastle Grayskullなる要塞があり、その要塞の入口の名前がJawbridgeである。で、主人公のHe-ManとShe-Raの母親は元宇宙飛行士で、Wormholeを通ってEterniaに落ちてきたという設定になっている
チップの話はあとでするとして、“Geared towards models of the future”という言葉に、なんというか意気込みというか黒雲というか、なんとも言えないものを感じる。
まずはそのなんとも言えない方の話を先に紹介しよう。2020年8月のHotChips 32において、Tenstorrentは“Compute substrate for Software 2.0”と題した講演を行なった(*1)。Software 2.0と聞くと連載595回のDataflowを思い出すのだが、TenstorrentはDynamic ExecutionこそがSoftware 2.0であると力説する。
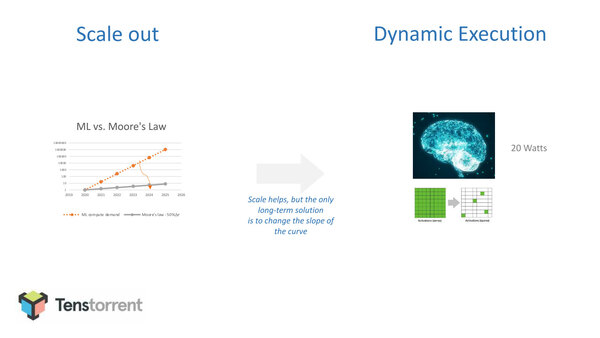
ムーアの法則と機械学習の要求するプロセッサー性能の乖離が激しいことへの解の1つはスケールアウトだが、長期的には役に立っても短期的な解決にならず、これをDynamic Executionが救うという趣旨。ちなみに20Wというのは人間の脳の消費エネルギー(の電力換算)である
まずスケールアウトについては、すでに広範に使われているが、最初こそデータの並列性だけでいけるものの、すぐにモデルの並列性も必要になるとする。
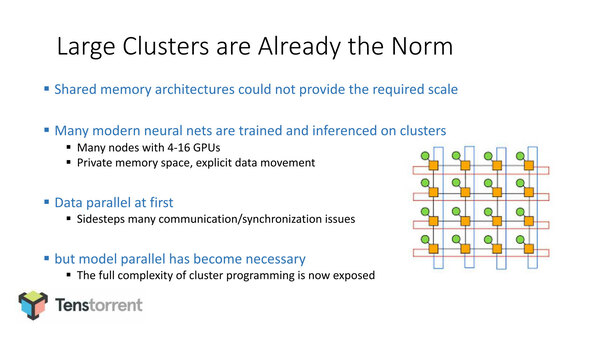
データの並列性だけでは極端にスケールアウトが進むと遊ぶノードが多数でてしまうことになる。またデータの並列性では、常にノード間の同期といった問題が出てくることになる
そもそも現在のスケールアウトの使われ方だと、Computation(計算)をするチップは山ほどあるのに、それをコントロールしてるのはPytouchを動かしてる1台のノートなんてこともしばしばあるわけで、はたしてこうした使い方だけが未来か? と言われると確かにもう少し考えたくなる。
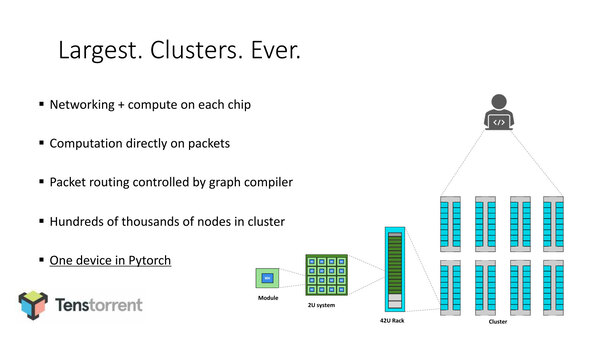
現在のスケールアウトの使われ方。1台のマシンから多数のノードを搭載したクラスターを集中的に扱えるという意味では優れたソリューションではある
またメモリーアクセスを考えた時、行列に対して行単位のアクセスは連続しているからシーケンシャルアクセスが効くが、行列を転置するとランダムアクセスになってしまう。悪いことに、同じ行列を転置してまた戻して、という操作が入ると同じメモリー領域にシーケンシャルアクセスとランダムアクセスが集中することになりかねず、これが大きく性能を落とす要因になる。
これを嫌ってある程度プロセッサーにPrivate Memoryを持たすのが最近の流行ではある
これをうまくさばくためには、メモリーアクセスのループを上手くハンドリングする必要がある。ならばPrivate Memoryを持たしてSharedをやめれば、というとこちらはこちらでノード間にまたがる場合にいろいろ問題が出てくることになる。これを解決するのがDynamic Executionである、というのが同社の説明である。
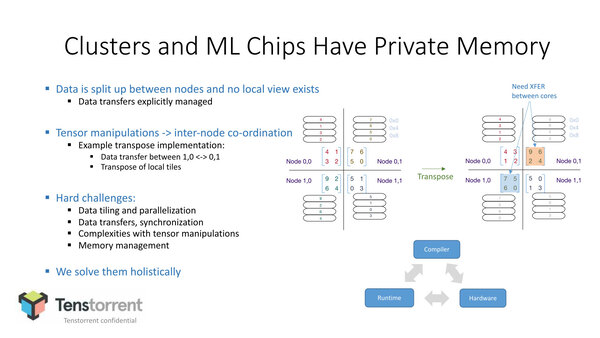
Private Memoryのマシンで、各ノード間にまたがるデータなどがなければこれでいいのだろうが、あいにくInferenceにしてもTrainingにしても、実際にはノード間でまたがるケースが非常に多い。これをどう解決するかはいろいろな方法が考案・実装されているが、今のところ決定打はない
(*1) なぜか分類がDay 2の"FPGAs and Reconfigurable Architectures"になっているのが謎。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















