




タイル同士を2次元のメッシュネットワークに接続し
複数のタイルを並行して稼働させる
実際IPUの初期バージョンは50M個のWeightを扱えるようになっているが、最大で250M個まで扱いを増やせる。前掲の画像でもMatrix Multiplying Memoryが複数バンクあるように描かれているが、このバンクを増やせばいいからだ。実際M1108では最大113M個のWeightを格納可能としている。

Matrix Multiplying Tileは全部で108個なので、1Tileあたり1M個ちょいのWeightを格納できることになる
もちろんこの方式の場合、Matrix Multiplying Memoryでは畳み込み演算「しか」できない計算になるので、アクティベーションなどのために別の処理が必要だが、それはStreaming ALUという専用エンジンが用意され、他に制御用にRISC-VコアがそれぞれのMatrix Multiplying Tileにひとつづつ格納されている。
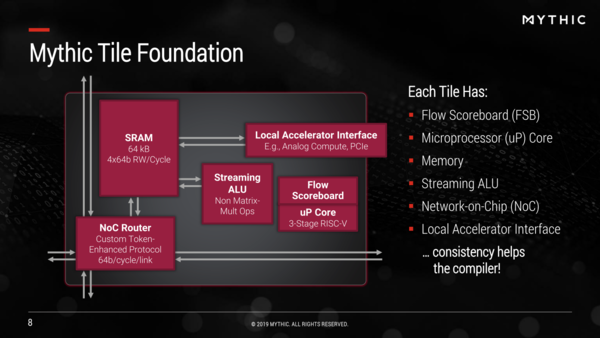
WeightそのものはすでにMatrix Multiplying Memory(ここでの表現ではLocal Accelerator Interfaceの先に存在する)に格納されているので、稼働中のネットワークは純粋にデータだけをやり取りすればいい。それもあって64bit/cycle/link程度のリンクになっている
このタイル同士は2次元のメッシュネットワークに接続されており近傍タイルと通信ができるのだが、どのタイルにどんな処理を割り当て、というのはグラフベースで解析(この解析ツール自体はもちろんMythicから提供される)することで、複数のタイルを並行して稼働させることでボトルネックを大幅に減らすことが可能になる。
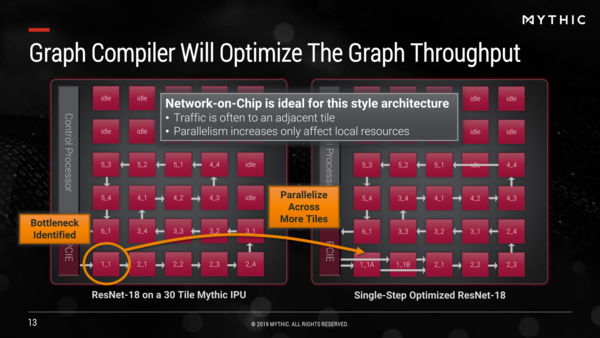
ResNet-18だと30タイル程度で処理できる。ResNet-50でもおそらく70タイル弱。AlexNetあたりまでは現在の108タイルでぎりぎりカバーできると思われる
さて先ほどの話になるが、個々のタイルは完全に独立(非同期)で動作しており、例えば先の画像で言えば、Tile 2_1の処理が終わったらその結果がリンク経由でTile 2_2に渡され、Tile 2_2はそのデータが来たことを受けて処理をスタートする。
これは完全にDataflow Architectureであり、また重みの記憶素子(フラッシュメモリー)がそのまま演算する形になるため、In-Memory Computingという条件を満たしている。そしてオームの法則(乗算)とキルヒホッフの法則(加算)を利用したAnalog Computingというわけだ。
そして、推論のデータそのものは移動が必要だが、重みに関しては一度ロードしたらその後ロードの必要がないため、重みの移動そのものに要する電力は0である。
おまけに演算そのものの消費電力が極めて少ない(加算はともかく乗算はそれなりに電力を喰うが、これが事実上0に近い)から、きわめて省電力である。それでいて、最大でメモリーセルの数だけ同時に演算ができるから、メモリーセルの数に比例して演算性能が上がることになる。省電力と高性能をうまく両立できたわけだ。
実際の性能で言えば、そのM1108ベースのアクセラレーターはEETimesの記事によればResNet-50(224×224pixel、batch size=1)で870fps、Yolo v3(608×608pixel、batch size=1)で60fpsを実現できたとしている。まだ今後のビジネスがどうなっていくのかを語るには時期尚早ではあるのだが、なかなかおもしろそうな製品と言えよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























