

「敵対機械学習」(AML)という用語は、人工知能(AI)モデルと機能を標的とする敵対的攻撃の研究と設計に関する研究分野を表します。シンプルな定義ではありますが、最も知識のあるセキュリティ実務家も関心を寄せています。この脅威の増加に対する読者の理解を高めるために、「モデルハッキング」という用語を生み出しました。このブログでは、この非常に重要なトピックを解読し、自動運転の重要な脅威に対するマカフィーのAdvanced Analytic Team(AAT)とAdvanced Threat Research(ATR)の共同の取り組みによる調査結果など、現実世界への影響の例を紹介します。
1.はじめに(基礎)
AIはほとんどの市場で機械学習(ML)、ディープラーニング(DL)、および実際のAIを含むと解釈されており、ここではAIのこの一般的な用語を使用することにします。AI内で、モデル(ビジネス結果を可能にする洞察を提供する数学的アルゴリズム)は、作成された実際のモデルの知識がなくても攻撃される可能性があります。機能は、必要な出力を定義するモデルの特性です。機能は、使用されている機能を知らなくても攻撃される可能性があります。これまで説明してきたことは、AMLの「ブラックボックス」攻撃(モデルと機能に関する情報がない状況)または「モデルハッキング」として知られています。これらの脆弱性が監視され、最終的に保護および修正されない限り、モデルおよび/または機能は既知または未知であり、セキュリティを意識せずに誤検出または除外を増加させることができます。
AIのフィードバック学習ループでは、新しい脅威を理解し、モデルを最新の状態に保つために、モデルの反復トレーニングが行われます(図1を参照)。モデルハッキングを使用すると、攻撃者はトレーニングセットを汚染できます。ただし、テストセットがハッキングされて、偽陰性が増加し、モデルの意図を回避し、モデルの決定を誤分類する可能性もあります。単に動揺させることによって-いくつかの機能(画像のピクセルなど)の大きさをゼロから1/1にゼロに変更するか、いくつかの機能を削除する-攻撃者は、壊滅的な影響でセキュリティ操作に大混乱をもたらすことができます。ハッカーは、邪悪な結果で報われるまで目立たないように「ping」を続けます。最初に使用したのと同じモデルで攻撃する必要さえありません。
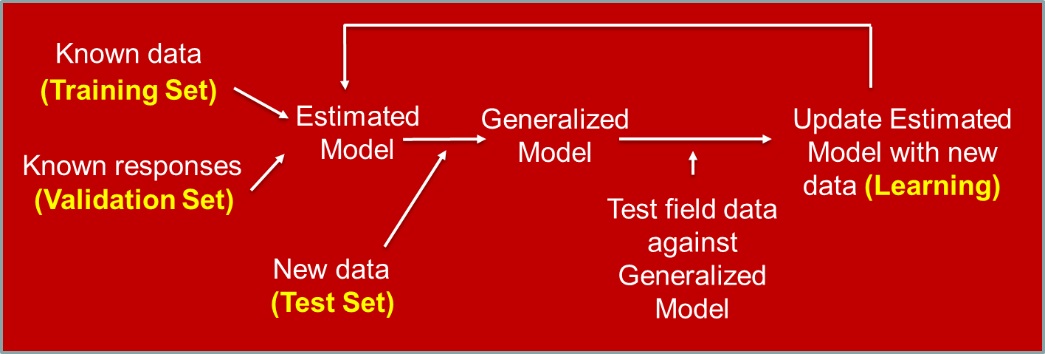
図1. AI学習の継続的なフィードバックループ
2.画像およびマルウェアのデジタル攻撃
ハッカーの目標は、ターゲット(特定の機能と特定のエラークラス)または非ターゲット(無差別分類子と複数の特定のエラークラス)、デジタル(画像、音声など)、または物理的なもの(速度制限標識など)です。
図2は、デジタルで標的にされたイワトビペンギンを示しています。
ホワイトボックス回避の例(私たちはモデルと機能を知っていました)になりますが、いくつかのピクセルの変更により貧弱なペンギンはフライパンまたはデスクトップコンピューターとして分類されるようになりました。
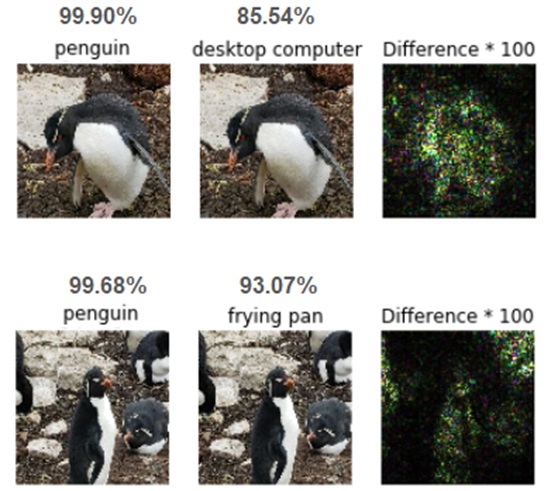
図2.ホワイトボックス、標的型、デジタル攻撃の回避例。ピクセルの摂動に続いて、ペンギンがデスクトップコンピューター(85.54%)またはフライパン(93.07%)として検出された
現在のモデルハッキングの研究のほとんどは画像認識に焦点を当てていますが、私たちはマルウェアの検出と静的分析のための回避攻撃と緩和方法を調査しています。AndroidマルウェアデータセットであるDREBIN[1]を利用し、Grosse, et al., 2016[2]の結果を複製しました。FakeInstallerを強調した625個のマルウェアサンプル、120kの良性サンプル、および5.5Kマルウェアを利用して、約1.5Kの機能を持つ4層の深層ニューラルネットワークを開発しました(図3を参照)。ただし、10個未満の機能を変更するだけの回避攻撃の後、マルウェアはほぼ100%ニューラルネットを回避しました。 もちろん、これは私たち全員にとっての懸念事項です。

図3.マルウェアデータセットとサンプルサイズのメトリック
CleverHans[3]オープンソースライブラリのJacobian Saliency Map Approach(JSMA)アルゴリズムを使用して、敵対的な例を作成する摂動を生成しました。 敵対的な例は、攻撃者が意図的にモデルに間違いを引き起こすように設計した機会学習モデルへの入力です[4]。JSMAアルゴリズムに必要なのは、変更する必要がある機能の最小数のみです。図4は、元のマルウェアサンプル(91%の信頼度でマルウェアとして検出された)を示しています。ホワイトボックス攻撃で2つのAPI呼び出しを追加しただけで、敵対的な例が100%の信頼度で良性として検出されるようになりました。明らかに、それは壊滅的です。
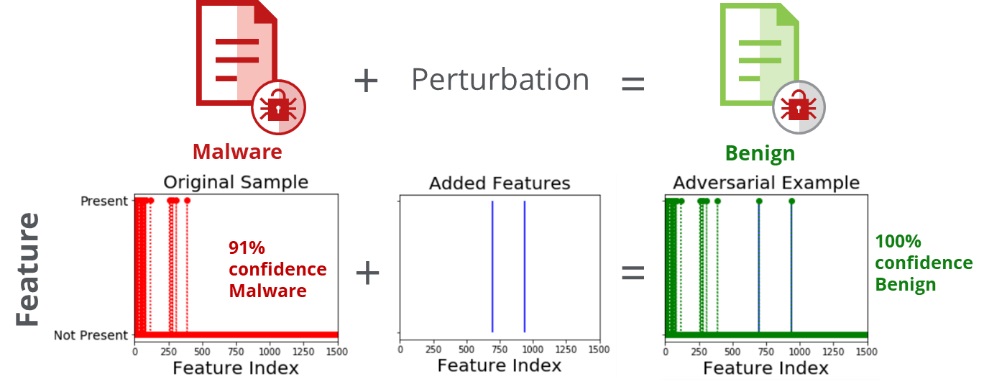
図4.機能空間でマルウェアに加えられた摂動により、100%の信頼度で良性の検出が行われた
2016年、Papernotは、マルウェアの検出に使用される正確なモデルを攻撃者が知る必要がないことを実証しました。 図5にこの転送可能性の理論を示し、攻撃者はK-Nearest Neighbor(KNN)アルゴリズムのソース(または代替)モデルを構築し、サポートベクターマシン(SVM)アルゴリズムを標的とした敵対的な例を作成しました。 その結果、82.16%の成功率が得られ、最終的に、あるモデルを別のモデルに置き換えて転送できることにより、ブラックボックス攻撃が可能になるだけでなく、非常に成功することが証明されました。
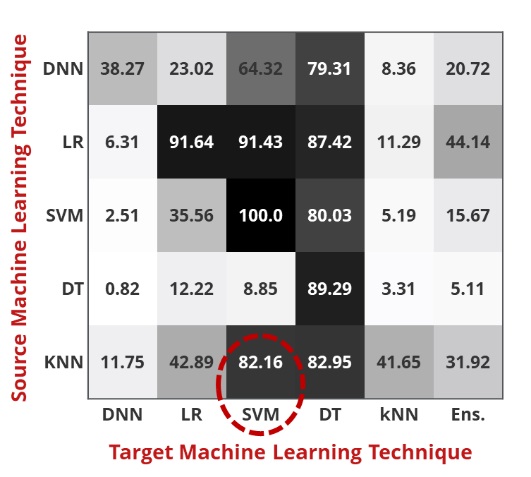
図5.別のモデル(サポートベクターマシンまたはSVM)を攻撃するために1つのモデル(K最近傍またはKNN)から作成された敵対的な例のPapernotの5つの成功した転送可能性
ブラックボックス攻撃では、AndroidのDREBINマルウェアデータセットがマルウェアとして92%検出されました。 ただし、代替モデルを使用し、攻撃者の例を被害者(つまり、ソース)システムに転送することで、マルウェアの検出をほぼゼロに減らすことができました。 別の壊滅的な例です。
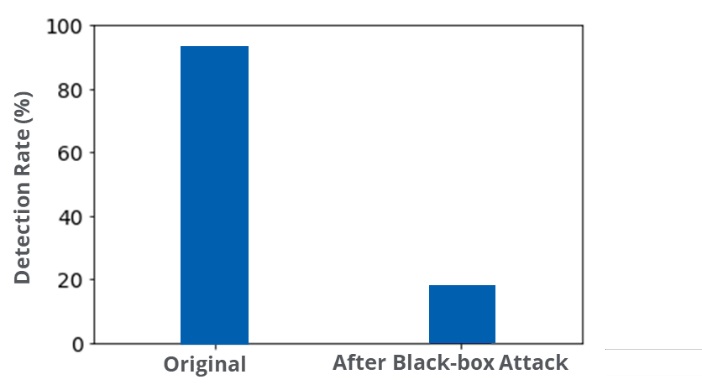
図6. DREBINマルウェアのブラックボックス攻撃のデモ
3.交通標識の物理的な攻撃
マルウェアは、サイバー犯罪者が被害者を攻撃するために展開する最も一般的なアーティファクトを表しますが、同等以上の脅威をもたらす他の多くの標的が存在します。過去18か月にわたって、私たちは、ますます業界の研究トレンドになっている交通標識に対するデジタルおよび物理攻撃を調査してきました。
この分野の研究は数年前に遡り、それ以来多くの出版物で複製され、強化されてきました。私たちはまず、このトピックに関するオリジナルの論文の1つを再現するために着手し、RGB(Red Green Blue)Webカメラを使用してLISA[6]の交通標識データセットから一時停止標識を分類する、非常に堅牢な分類システムを構築しました。
このモデルは非常に優れた性能を発揮し、照明、視野角、標識の障害を処理しました。数か月の間に、私たちはモデルハッキングコードを開発し、デジタル領域と物理領域の両方で、標的に対する攻撃と標的にならない攻撃の両方を引き起こしました。
この成功に続き、現代の車両が、車両のヘッドアップディスプレイ(HUD)への入力としてだけでなく、場合によっては車両の実際の運転方針への入力として、カメラベースの速度制限標識検出を行うことを認識し、攻撃ベクトルを速度制限標識に拡張しました。最終的に、速度制限標識のわずかな変更により、攻撃者が車両の自動運転機能に影響を与え、アダプティブクルーズコントロールの速度を制御できることがわかりました。この調査の詳細については、トピックに関するブログ投稿を参照してください。
4.モデルハッキングの検出と保護
Goodニュースとしては、従来のソフトウェアの脆弱性と同様に、モデルハッキングを防御できることであり、業界はこのまれな機会を利用して、脅威が攻撃者に真の価値をもたらす前に対処しています。モデルハッキングの検出と保護は、毎週公開される多くの記事で発展を続けています。
検出方法には、すべてのソフトウェアパッチがインストールされていることの確認、False PositiveおよびFalse Negativeのドリフトの厳密な監視、しきい値の変更が必要な原因と結果の確認、頻繁な再トレーニング、およびフィールドでの減衰の監査(モデルの信頼性)が含まれます。
説明可能なAI(「XAI」)は、「このNNが決定を下した理由」にこたえるために、研究分野で検討されていますが、優先される機能の小さな変更に適用して、潜在的なモデルハッキングを評価することも可能です。さらに、マシンが自律的に動作しておらず、ループ内の人間から監視されるようにするために、人とマシンの連携(Human Machine Teaming)が重要です。現在、マシンはコンテキストを理解していません。しかし、人間は、考えられるすべての根本的な原因と、メトリックのほとんど感知できないシフトの緩和を考慮することができます。
一般的に採用されている保護方法には、特徴の絞り込みと削減、蒸留、ノイズの追加、多重分類システム、否定的影響の拒否(RONI)、および組み合わせソリューションを含む他の多くの分析ソリューションが含まれます。それぞれの方法には長所と短所があり、読者は適切な方法を選択するために特定のエコシステムとセキュリティメトリックを検討することが推奨されます。
5.モデルハッキングの脅威と進行中の研究
モデルハッキングの報告はまだ報告されていませんが、2014年の50件未満の文献記事しか見られなかったのが2020年は1500件以上の記事が見られるように過去数年間で研究が増加していることは注目に値します。なお洗練されたハッカーがこの文献を読んでいないと想定することは難しいでしょう。またおそらくサイバーセキュリティで初めて、多くの研究者がこれらのユニークな脆弱性に対する攻撃、検出、および保護を積極的に開発したことも注目に値します。
私たちは、モデルハッキング攻撃のナレッジをさらに強化し、検出と保護が組み込まれたソリューションの実装を確実にします。私たちの研究は、マルウェア検出、顔認識、画像ライブラリのGANS(Generative Adversarial Networks)などの最新のアルゴリズムを対象とすることに優れています。また、交通標識モデルのハッキングをさらに実際の例に移しているところです。
最後に、マカフィーはこの重要な分野でセキュリティ業界をリードしていると考えています。マカフィーを際立たせる1つの側面は、ATRとAATのユニークな関係とチーム間のコラボレーションです。詳細かつ最先端のセキュリティ研究機能を備えたATR、世界レベルのデータ分析と人工知能の専門知識を備えたAATのように、それぞれが独自のスキルセットを活用しています。これらのチームの協業において、できることは限られていますが、悪意のある攻撃者が脅威を理解または兵器化する前に、独自のコンポーネントを備えた新たな攻撃ベクトルで脅威を予測、調査、分析、および防御に尽力します。
さらに詳細を御覧いただく際は、引用されている参考文献のいずれかやhttps://mascherari.press/introduction-to-adversarial-machine-learning/の「敵対機械学習の概要」をご参照ください。
[1] Technische Universitat Braunschweig(ブラウンシュヴァイク工科大学の厚意により)
[2] Grosse, Kathrin, Nicolas Papernot, et al. ”Adversarial Perturbations Against Deep Neural Networks for Malware Classification” Cornell University Library. 16 Jun 2016.
[3] Cleverhans:https://github.com/tensorflow/cleverhansにある攻撃の構築、防御の構築、およびベンチマークの両方を行うための敵対的なサンプルライブラリ。
[4] Goodfellow, Ian, et al. “Generative Adversarial Nets” https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
[5]Papernot, Nicholas, et al. “Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples” https://arxiv.org/abs/1605.07277.
[6]LISA = Laboratory for Intelligent and Safe Automobiles
※本ページの内容は、2020年2月19日(US時間)更新の以下のMcAfee Blogの内容です。
原文:Introduction and Application of Model Hacking
著者:Steve Povolny and Celeste Fralick
協力:Catherine Huang, Ph.D. and Shivangee Trivedi
本記事はアフィリエイトプログラムによる収益を得ている場合があります



