




HPE(Hewlett-Packard Enterprise)はItaniumベースの製品を(表立ってはできないから、ひっそりと)x86ベースに移行を促す努力をしながら、競合(Dell EMCやLenovo)とのサーバーマーケットのシェア争いを繰り広げていたわけであるが、そのかたわらでおもしろい研究をしていた。それが、The Machineである。
CPUではなくメモリーを中心に設計された
サーバー「The Machine」
The Machineとは、2000年代前半から開発が始まった、非常に意欲的な未来のサーバーである。一口で言えばメモリー主導型コンピューティング(MDC:Memory Driven Computing)を実装するプロトタイプの名前が“The Machine”である。
そもそもMDCとはなに? という話であるが、The Machineのコンセプトではメモリーとプロセッサーを切り離すことにある。
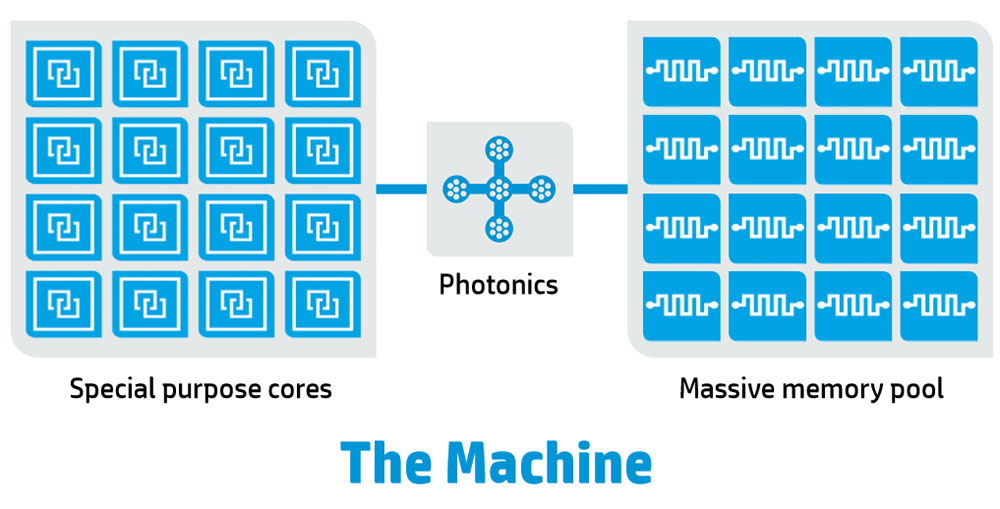
The Machineのコンセプト:左がComputation、右がMemoryのPoolとなる
通常、メモリーはプロセッサーに接続されており、例えばあるデータをプロセッサーAで処理し、その結果をプロセッサーBでまた処理するといった場合、まずAのローカルメモリーからデータを取り出して処理、その結果をBに送り再び処理し、それをBのローカルメモリーに格納する(だいぶ端折っているのはご容赦を)といった具合に、プロセッサーによる計算(Computation)が主役であり、データはプロセッサーに従属する形でシステムのあちこちに移動することになる。
もちろん昨今のマルチコアの場合は、1つのCPUの中に複数のプロセッサーコアが内蔵されており、共通のメモリーを利用しているため、その範囲で言えば同じメモリー領域を使うことになるが、それこそスケールアウトタイプのサーバーの場合はノードあたりのコア数は控えめに抑える方向にあるので、冒頭に述べたようなシチュエーションは実際にあり得るし、しかもその際には相対的に低速なネットワーク(イーサネットなりなんなり)を経由することになるから、レイテンシーも大きい。
そこで逆転の発想で、メモリーは一ヵ所に集めて、そこに多数のプロセッサーがアクセスする、という構成を取ったのがMCDである。
データの置き場所は移動せずに、プロセッサーが必要な時にそのデータを取り出し、また元の場所に格納する仕組みを取っている。
特徴的なのは、このメモリーは不揮発性であることを前提にしていることだ。つまりメモリーがそのままストレージとしても機能するわけで、これにより処理のたびに遅いストレージから読みだして、処理後に再び遅いストレージに書き戻す手間が必要なくなる。
当然ながらこれはアーキテクチャー的に従来の計算主導型コンピューティング(CDC:Computation Driven Computing)とはまったく異なるため、ソフトウェアレベルでの互換性はなく、MDCにあわせて作り変える必要がある。
ただ逆に言えば、従来はソフトウェア互換性などの理由でx86(もうここではさすがにItaniumという言葉は出なかった)を選ばざるを得ないケースが多かったわけだが、MDCでは別にx86である必要すらなく、さらに言えばCPUである必要もない。GPUとかFPGA、今ならAIプロセッサーなどもここに含まれるが、こうしたもののハイブリッド構成で全然構わないということになる。
ただ、この方式の欠点はプロセッサーとメモリーの間の距離が長くなり、レイテンシーが増えて帯域が減ることである。
そもそもなぜこれまでメモリーがプロセッサーのそばに置かれていたかと言えば、プロセッサーが高速で動くためにはメモリーに高速にアクセスできないと、メモリーアクセス待ちが大量に発生してしまい、性能が頭打ちになるためである。
もう1つ、副次的な理由を挙げるとすれば、広く使われているSDRAM(DDR/DDR2/DDR3/DDR4含む)はいずれも64bit幅(ECCを含めると72bit幅)のパラレルバスであり、物理的にけっこうな配線面積を取る。
したがって、あまり長距離を引き回すと基板への実装が難しくなり、レイテンシーも加速度的に増える。信号線は等長配線が要求されるので、一番配線長が長いルートに合わせて配線の引き回しが行なわれるからだ。結果、無駄に配線が長くなる。
このあたりを嫌って、例えばFB-DIMMやRambusのRDRAM/XDR/XDR2といったソリューションも出てきたものの、ほとんど定着せずに消えていった(XDR2に至っては採用例がないまま終わった)ことを考えると、非標準的なメモリーを利用するのはリスクが高く、するとSDRAMをベースに考えざるを得ず、結果としてプロセッサーのそばに置くしかない、という結果に落ち着くことになる。
これに対するHPEの解は、Silicon Photonicsを利用した光インターコネクトを利用することだった。Silicon Photonicsに関してはいろいろ話がある。この分野、インテルはもう10年以上も研究しているものの、商品化されたのはほんのごく一部でしかなく、現時点でもまだ商用利用が可能なレベルに達しているとは言えない。このインテルの苦闘の歴史は、それだけで1本分の記事以上のボリュームがある。
最近では(NVIDIAに買収される予定の)Mellanoxが一時期ずいぶん関連企業を買収して精力的に開発を進めてきたものの、2018年1月に断念。チームも解散しているといった具合に、実は非常に敷居が高い。
もっともThe Machineのコンセプトが発表された時点では、まだわりと現実的に実現可能と思われていた技術であり、HPEの見通しの甘さを責めるのは難しいだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












