



非構造化データも扱えるなど競合優位性を強調、「OOW 2019」で発表のDB最新技術動向と戦略を語る
Oracle DBの“都市伝説”を暴く? アンディ・メンデルソン氏が説明
2019年10月29日 07時00分更新

日本オラクルは2019年10月28日、9月に開催された「Oracle OpenWorld 2019(OOW)」の発表内容に基づく、データベース関連の最新技術動向や戦略についての記者説明会を開催した。
来日したデータベース製品担当幹部のアンドリュー(アンディ)・メンデルソン氏らが登壇し、最新版「Oracle Database(Oracle DB)」のほか、「Oracle Exadata」などのエンジニアドシステム製品、自律型データベースサービスである「Oracle Autonomous Database」に関する技術紹介や競合比較、アプリケーション開発者側から見たメリット、製品戦略などについて語った。

Oracle Database、Exadata、Autonomous Databaseそれぞれの最新技術動向を紹介した

米オラクル データベース・サーバー技術担当EVPのアンドリュー・メンデルソン氏

米オラクル Exadata マスター・プロダクト・マネージャーのマリア・コルガン氏
マルチモデル統合型、マルチテナントなど「現在の」Oracle DBが持つ特徴を説明
メンデルソン氏はまず、「Oracle DBに対しては、いくつもの誤った“都市伝説”が流布している」と述べたうえで、その誤りを正していく形で説明を進めた。
たとえば「Oracle DBはリレーショナルデータベース(RDBMS)なので、非構造型データの管理や分析はできない」という“都市伝説”を取り上げた。実際は、最新版であるOracle DB 19cにおいてはRDB(構造化データ)だけでなく、JSONやKey Value、グラフ、ファイルといった非構造化データも格納することができる、マルチモデルの「統合型データベース(Converged DB)」になっていると説明。しかも、従来のRDBと同様の、一貫性のあるクエリやビューであらゆるタイプのデータを参照することができ、DBシステムの信頼性やスケーラビリティ、セキュリティについても同じように実現できると説明した。
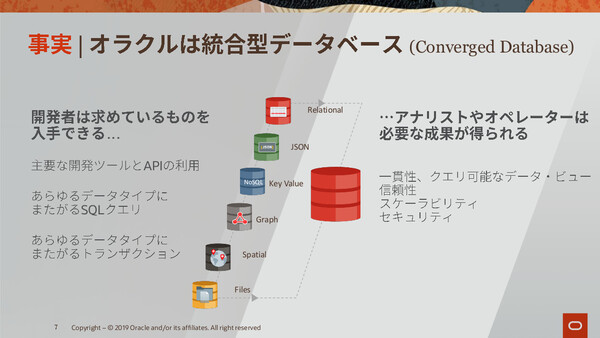
Oracle DBはマルチモデル対応の「統合型DB」であり、従来のRDBと透過的に多様なデータも扱えることを紹介
また「Oracle DBは、マイクロサービスやクラウドといった最新のパラダイムには適していない」という主張については、単一のOracle DBインスタンス上で、完全に隔離された形で大量のDBを展開できる“コンテナライク”な「プラガブルデータベース(PDB)」技術を紹介。このPDBでも前述した多様な非構造型データを扱うことができ、マイクロサービスの開発においては個々の開発者が自在にDB環境を構築/利用できるメリットがあると説明した。
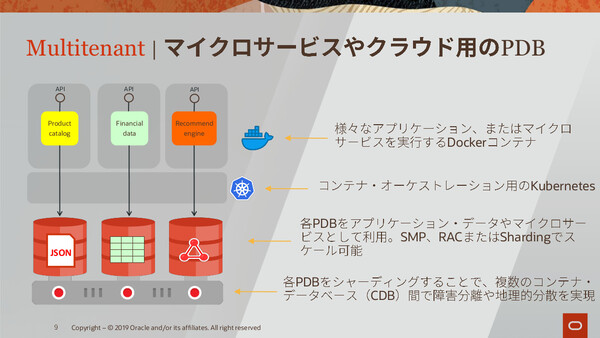
完全に隔離されたマルチテナントDBを実現できるプラガブルDB(PDB)技術によって、個々の開発者が柔軟に利用できるDB環境を提供できると説明
ちなみに現行最新版のOracle DB 19cでは、膨大な量のIoTストリーミングデータを高速に取り扱うための「Streaming Insert for IoT」機能、JSONデータに関する機能拡張などが行われている。来年1月ごろにリリースされるOracle DB 20cでは、新たにブロックチェーンをテーブルとしてネイティブに格納できる「Native Blockchain tables」機能、DBに格納しているデータに対して機械学習モデルを自動的に構築できる「AutoML」機能、インテル「Optane」のようなパーシステントメモリ(永続性メモリ)へのアーキテクチャ最適化といった取り組みが計画されている。


現行最新版の19cと、来年初頭にリリース予定の20cにおける機能強化点
説明の中でメンデルソン氏は、競合するAmazon Web Services(AWS)の名を挙げて、AWSのような競合他社ではブロックチェーンなどのマルチモデルデータをすべて個別のDBMS/サービスで扱わなければならないと指摘し、それらがすべて単一のDBMSで管理できるOracle DBの優位性を強調した。
「たとえばアマゾン(AWS)では、ブロックチェーン『専用の』データマネジメントサービスを作っているが、そうした考えは“クレイジー”だ。Oracle DB 20cならば、ブロックチェーンテーブルを作るだけで、通常と(RDBと)同じようにクエリがかけられる。また、20cではコアDBに機械学習機能を統合するが、競合他社では機械学習をサポートする特定のデータベースを使わなければならない。(そうした複雑さは)開発者にとって“悪夢”だろう」(メンデルソン氏)

Oracle DB 20cでは「ブロックチェーンテーブル」機能も追加される(プレビューリリース)。データ改竄を防止する特徴を持ちつつ、通常のテーブルと透過的に扱えるようになるという
エンジニアドシステムについては、9月のOOWにおいて最新版Exadataとなる「Exadata X8M」を発表している。X8Mは前述したパーシステントメモリを搭載するほか、InfiniBandを100GbE+RoCE(100ギガビットEthernet+RDMA over Converged Ethernet)に置き換えたモデルもラインアップした。メンデルソン氏は、パーシステントメモリとRDMAの採用によって「19マイクロ秒未満」という超低レイテンシのデータアクセスを可能にしており、X8Mは「大きな革命」「ゲームチェンジャーなテクノロジー」だと紹介した。

今年のOOWで発表されたExadata X8Mの特徴。パーシステントメモリや100GbE+RoCEの採用など、より高いパフォーマンスを実現する
なお、Exadataについても「Exadataはベンダーロックインだ」という“都市伝説”があると語る。これに対してメンデルソン氏は、Exadataでしか得られない高いパフォーマンスやスケーラビリティ、信頼性はあるものの、そこで稼働するOracle DBそのものは通常のオンプレミスサーバーでもクラウドサービスでも同一の開発者向けAPIをサポートしており、DBワークロードをロックインするものではないと主張。むしろ、IBMメインフレームやAWS上のワークロードのほうがロックインされる危険性があると反論した。
Autonomous DBはグローバルで数千社が利用、新規顧客獲得のきっかけにも
Autonomous DBについては、データベースのデプロイや構築、チューニングといった作業が自動化/自律化されていること、オンプレミス/クラウド間で同一のエンタープライズ向け機能がビルトインされていること、マルチモデルの統合データベースであること、の3つを特徴に挙げる。そのうえで、Autonomous DBの利用が「アプリケーション開発のうえで最も生産的なアプローチ」だと述べた。
すでにグローバルで数千社の顧客が利用を開始しており、特にこれまでオンプレミス環境でOracle DBを使ってこなかった中堅中小企業層の新規顧客も多く見られる説明した。これは日本、グローバルを問わず同じ傾向だという。
「最終的には中堅中小企業、エンタープライズ(大規模企業)を問わずAutonomous DBへと移行するものと考えている。ただしエンタープライズ層には、長年にわたりOracle DBを使ってきたこれまでの使い方を変えたくないという考えも少なからずある。したがって、エンタープライズ層がAutonomous DBの考え方になじみ、移行するまでには少し時間がかかるだろう」(メンデルソン氏)

Autonomous DB採用顧客の例。製造業システムメーカーのMESTECは、Microsoft AzureとOracle Autonomous DBをダイレクト接続して本番システムで利用する初めての顧客だという
メンデルソン氏は、OOWで発表したクラウドサービスの無期限無償枠「Oracle Cloud Free Tier」でAutonomous DBサービスが利用できることも説明した。Oracle Cloud Infrastructure(OCI)テナントごとに、2つのAutonomous DBインスタンスが利用できる。インスタンスあたり1つのOCPU、20GBのDBストレージという制限はあるが、機能的な制限はないため、開発者や学生をはじめ、誰でもすぐにAutonomous DBを使えるとアピールする。
なお今年のOOWにおいて、Autonomous DBの次なる進化の方向性として“Autonomous Data Platform”ビジョンが示されている。これはAutonomous DBも含むさまざまなデータソースにあるデータの統合を、自動的/自律的に処理するというものだ。マルチベンダー/マルチクラウドのデータソース環境も前提としている。
「ユーザーが、たとえば『このアプリケーションにあるデータと、ここにあるデータとを使いたい』といった具合に指定してボタンをクリックするだけで、あとは自動的にデータの移動や変換といった処理が行われる。これは来年(2020年)から提供するロードマップになっている」(メンデルソン氏)
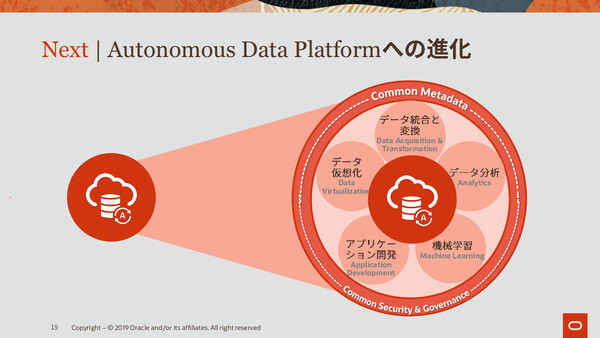
Autonomous DBの先にあるのは「Autonomous Data Platform」。これは自動/自律型の統合データプラットフォーム構想だ
続いて登壇したExadata マスター・プロダクト・マネージャーのマリア・コルガン氏は、アプリケーション開発者の視点から見た「次世代のデータドリブンアプリケーション」開発にかかる課題と、オラクルがOracle DBを通じて提示するソリューションについて説明した。
たとえば「DBの複雑性増大」という課題についてはソフトウェア/ハードウェア両面での自動化やクラウドサービス化、「アジャイルかつ安全なアプリケーションの実現」についてはPDB、「構造型/非構造型データの両方を扱いたいアプリケーションニーズ」に対してはマルチモデル対応DB、といった具合だ。

コルガン氏は、次世代の“データドリブンアプリケーション”実現のためには、DBに多様な要件が求められると説明した
機械学習を用いた「予測型アプリケーション」ニーズについては、Oracle DBが内蔵する多数の機械学習アルゴリズムを適用することでリアルタイムの分析やレコメンデーションが可能であるほか、Oracle DB 20cに搭載(プレビューリリース)されるAutoML機能によって、ビジネスユーザーなど機械学習スキルを持たない人でも活用が可能になると紹介した。
また「安価なデータレイクの活用」という課題については、Oracle DBが安価なクラウドオブジェクトストア上のデータをシームレスに取り込み、クエリ処理できることを紹介。CSV、JSON、Parquet、Avroといった主要なデータ型にも対応しており、データ統合のための余計なコストがかからず、生産性の高いアプリケーション開発が可能になると説明した。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



