
配線のために生産ラインを再構成までした
MCM周り
MCM周りについてもいくつか説明があったので紹介しよう。下の画像がRyzen 3000シリーズの内部構成である。
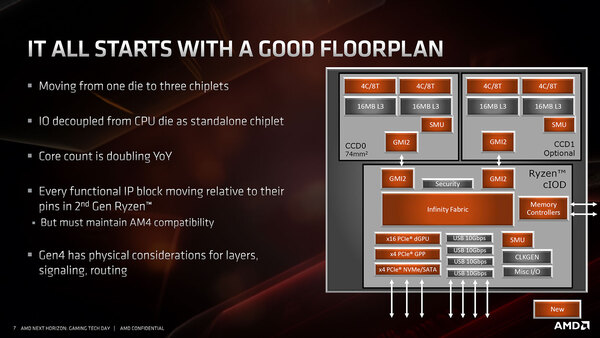
Ryzen 3000シリーズの内部構成。画像には描かれていないが、各々のCCD内には、2つのCCXとSMUをつなぐインフィニティーファブリックがあり、ここからGMI2経由でI/Oチップレット側のインフィニティーファブリックにつながる構造になっていると理解するのが正しいと思われる
連載496回で、「インフィニティーファブリックのコントローラーがI/Oチップレット側に移動すると、Zen 2内部の制御(それこそSenseMIなどがインフィニティーファブリックの上で実装されている)が遅くならないか?」というのが、CCXを8コアでないかと考えた最大の理由だったのだが、こちらにその回答が入っている。
図中でSMU(System Management Unit)とあるのが、そのインフィニティーファブリックを利用したSenseMIを始めとするさまざまなシステム管理を司る部分である。つまり以下のことがわかる。
- CCXは引き続き4コアベース
- CCD(つまりCPUチップレット)全体の制御は、CCD内のSMUが行なう。同様にcIoD(つまりI/Oチップレット)の制御は、cIoD内のSMUが行なう
構図としては連載496回で図解したZenベースのダイの内部ブロックに近いものになると考えられる。
ちなみに一見すると簡単そうに見えるが、実際はI/Oチップレットが従来と同じ150μmピッチのボール状バンプ(メッキで形成した突起状の接続電極)なのに対し、7nmプロセスを使ったCPUチップレットではこれが130μmピッチに狭まったそうだ。

ここで150μmに広げたら、おそらくCPUチップレットのダイサイズが無駄に肥大化することになったと思われる。ダイサイズをギリギリまで抑えつつ、必要なピン数を維持するためには、バンプピッチを減らすしかなかったのだろう
これを解決するために、従来のように配線に直接バンプを構成するのではなく、銅で柱を立て、その上にバンプを形成するという解決案を取ったそうである。

メリットとして“common die height after assembly”とあるのは、7nmプロセスのCPUチップレットのダイの厚みが12nmのI/Oチップレットの厚みと異なっており、これを銅(Cu)の高さで調整することで同じ厚みにすることで、ヒートシンクの設計を容易にしたとと思われる
またこのRyzen 3000では既報の通りPCI Express Gen4をサポートするが、16GT/秒に達する信号速度に対応するために、パッケージの材質を改善して損失を減らす工夫が必要だったそうである。

16GT/秒のPCIe Gen4ですらこれなのだから、次に控えている32GT/秒のPCIe Gen5はさらに大変になりそうだ
下の画像がそのパッケージ層の配線で、おそらくは一番信号線のレイヤーだと思われるが、中央下のI/Oチップレットとその上に2つ並ぶCPUチップレットの間を直結しているのがインフィニティーファブリックの配線、左側に出ているのがおそらくはDDR4、そしてI/Oチップレットの中央および右上から、パッケージの右側に出ているのがPCI Express Gen4の配線と思われる。

パッケージ層の配線。従来のRyzenでは10層基板を利用したが、Ryzen 3000シリーズではこれが12層に増えたそうだ
実装もいろいろ大変だったそうで、生産ラインを再構成する必要があったというのも無理ないところである。

配線のために生産ラインを再構成。1×CCD構成の製品ラインと2×CCD構成の製品ラインを完全に分けるというのも現実問題として無駄が多くなって難しいわけで、どうしても1つの製品ラインでこれを実現する必要があったのだろう
ということで、今回はCPU周りを深く掘り下げて解説した。全然性能やラインナップの話まで行けなかったのだが、このあたりはRadeon RX 5700シリーズ周りのまだ触れてない話題と併せて次週紹介する予定だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












