



レイトレーシングにDLSS、RTコアやTensorコアの役割、自動OCテスト機能まで!
Turingコアの構造も謎の指標「RTX-OPS」の計算方法も明らかに!徐々に見えてきたGeForce RTX 20シリーズの全貌
2018年09月14日 22時00分更新

「TU104」及び「TU106」コアの構成
そして、TU104及びTU106のダイアグラムもお見せしよう。TU106はTU104のハーフモデルといったところだが、NVLinkのインターフェース自体が削除されている点に注目したい。
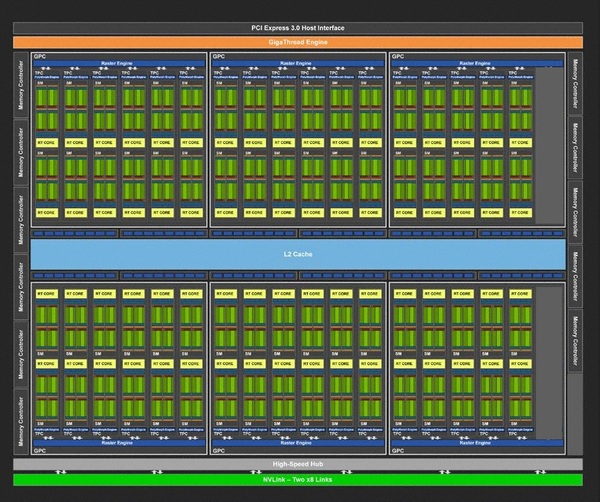
TU102ベースのRTX 2080 Tiのダイアグラム(再掲)。
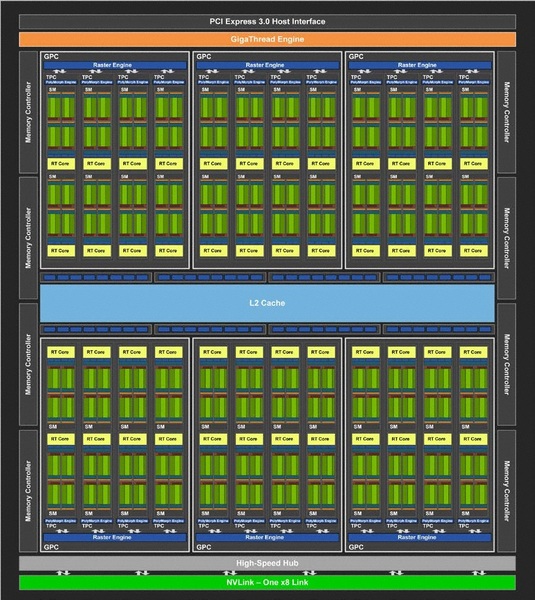
TU104ベースのRTX 2080のダイアグラム。GPC(Graphics Processing Cluster)6基構成は共通だが、内包するSMの数が8基に減らされ、メモリーコントローラーも8基(32bit×8=256bit)になっている。

TU106ベースのRTX 2070のダイアグラム。TU104のGPCやL2キャッシュはそれぞれ半減している。さらに、NVLinkのインターフェースを除去した格好だ。
GDDR6メモリーとメモリー圧縮技術
VRAMは単に画面に出力するデータの置き場所だけでなく、GPU内で走るシェーダーや、それが扱うデータなど、描画処理に使う様々な情報の置き場所である。つまり、VRAMとGPUのやり取りにモタつきが起これば、描画処理全体の足をひっぱる。特に液晶ディスプレーが高解像度化するほど、描画処理が複雑になるほど、VRAMのスループットが重要視される傾向にある。
そのスループット問題を解決されると思われていたHigh Bandwidth MemoryことHBMだったが、蓋を開けてみれば配線(特に貫通ビア)が難しく、歩留まりの悪化とコストアップを招いてしまったのはライバルAMDのR9 Fury~RX Vegaの現状を見ればわかる。NVIDIAもTITAN VなどでHBM2を採用しているが、RTX 20シリーズではコストや実装効率の良い「GDDR6」を選択した。
GDDR5Xを1世代で捨てGDDR6に移行した理由は明らかにされていないが、GDDR6は18GHz(相当)までをターゲットにしており、将来性があることとがひとつ。そして、GDDR5Xはメモリーアクセス時の粒度(Granularity)が大きいという点が理由ではないかと思われる。
GPUの描画処理においては、1回に32B(バイト)程度の小さなデータをメモリーから取り出すことが多い。だがGDDR5Xは、1回のアクセスで64B単位でしか取り出せない。つまり、粒度が大きいので効率が悪いのが弱点となる。一方で、GDDR6ではGDDR5と同じ32B単位で取り出せるので効率が良いのだ。
RTX 2080 Tiではメモリークロックは14GHz相当とクロックも上がるため、メモリー周りの回路設計には相当な労力が割かれている。次の図はGDDR6の“アイ”パターンと呼ばれるものだが、Pascal初出時のGDDR5X、GTX 1080 Tiと同時に発表された11GHz版GTX 1080におけるメモリーのアイパターンを比べてみると、GDDR6のアイパターンのほうが中央に大きな“目”のように見える空間が目立つ。このアイパターンの大きさこそが、RTX 20シリーズのVRAMスループットを支えているのだ。
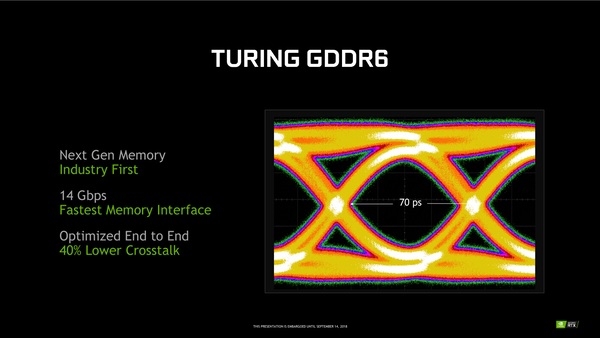
GDDR6のアイパターン。中央に見える目のような部分が大きく、輪郭のように見える部分の線(実際は波形の集合)が細いほど、信号が良質であることを示す。図はアイパターン1つぶんの時間が70ピコ秒、つまり14GHzであることを示している。
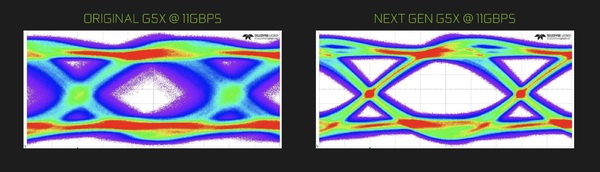
これは11GHz版のGTX 1080発表時にNVIDIAが公開したデータ。左が10GHz時代のGDDR5Xメモリーを11GHz動作させた時のアイパターンで、輪郭がボヤけており、アイパターンの開口部も小さい。様々な改良により11GHzのGDDR5Xを達成した時のアイパターンが右(左右の幅は90ピコ秒、11GHz)となる。
メモリーがクロックが11GHzから14GHzに向上すれば、メモリー帯域は単純計算で27%程度向上する。メモリーバス上を流れるデータをもっとコンパクトにすれば、さらにスループットを稼ぐことができる。Maxwell~Pascalでもメモリー圧縮技術は重要なトピックだったが、TuringではPascalのメモリー圧縮技術をさらに改良したものが搭載された。
具体的な技法については明らかにされていないが、RTX 2080 TiとGTX 1080 Tiを比較した場合、有効帯域が約50%増加。つまり、データ量をほぼ半減させることに成功している。もちろん、データ圧縮効果についてはゲームにより異なるが、単純なメモリー性能の向上ぶんに上積みする形でメモリー圧縮技術が効いてくる。特にWQHDや4K、8K環境での効果が期待できるだろう。
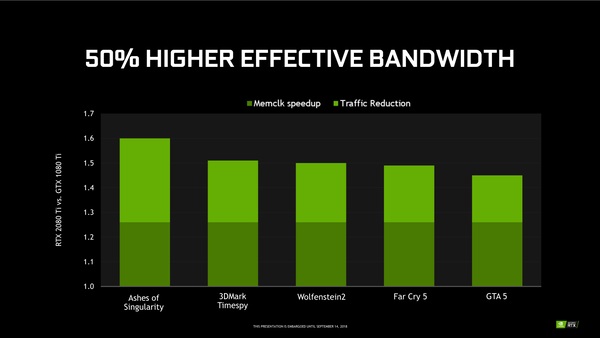
GTX 1080 Tiを基準にした時、RTX 2080 Tiのメモリーシステムがどれだけ帯域を向上させたかというグラフ。濃い緑の部分はメモリークロックの向上ぶん。薄い緑の部分はメモリー圧縮効果であるため、ゲームやベンチマークの種類によって効果が異なる。両者を合わせれば、GTX 1080 Tiの約1.5倍のメモリースループットが得られるということだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります













で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")
























