




2週間空いてしまったが、スーパーコンピューターの話を続けよう。今回は再びアメリカに戻る。1984年、サンノゼでCydromeという会社が創立された。
創立メンバーはDavid Yen博士、Wei Yen博士、Ross A.Towle氏、、Arun Kumar氏、Bob R. Rau博士といった面々である。
ネタバレになるかもしれないが、これらの面々のその後の経歴を紹介しておくと、David W. Yen博士はSun Microsystemsの副社長やJuniper Networkの副社長、Ciscoの専務などを歴任。
Wei Yen博士はその後SGIの専務を勤めながら同時にArtXを創立、その後はいくつかの会社の取締役会に名前を連ねたり創立したりしつつ、現在はAcer Cloud Technologyを率いている。
Arun Kumar氏は、SGIのディレクターを経ていくつかの会社のCEO/CFOを勤め、現在はITA(International Trade Administration:アメリカ合衆国商務省国際貿易局)の次官補という役職に就かれている。
そしてCydra 5のチーフアーキテクトを勤めたBob R. Rau博士はHPの研究員となって2002年に逝去された。さて、このメンバーのその後の経歴に何かしら連想されるものがないだろうか? というのが今回のお題だ。
その話は後にするとして、このCydromeという会社は独自のアーキテクチャーのシステムであるCydra 5を開発した。まずはここから解説したい。
50~100万ドル程度で購入可能な
気軽に使えるシステム「Cydra 5」
Cydra 5の目的は、50~100万ドル程度で購入可能でありながら、1000~2000万ドルクラスのスーパーコンピューターの1/4~2/3程度の性能が期待できるシステムである。
彼らはこれを強調すべく、Cydra 5 Departmental Supercomputerと呼んでいた。Departmentalというのは部門の意味で、要するに組織全体で使うものではなく、部門ごとに導入して気軽(?)に使えるようなシステムを目指していたということだ。
もちろん、そんなシステムが簡単にできるわけもないので、さまざまなテクニックに加え、いくつかのトレードオフを考慮していた。
Cydra 5の元をたどると、米TRWのESL(Electromagnetic Systems Laboratory)が開発していたPolycyclic Architectureに基づくベクトルプロセッサーに行き着く。
一種のデータフロー・アーキテクチャー(データが来た順に処理を行なう仕組み)で、多くのデータフロー・アーキテクチャーと同じようにこれも非同期構成だったらしい。
Cydra 5は同期式のシステムなので、この点では異なるのだが、これに近い概念を実現するために複数種類のプロセッサーを混在するヘテロジニアス・マルチプロセッサーの構成を取った。
下図が全体の構成であるが、中核にあるのがインタラクティブ・プロセッサーで、ここが計算以外のほとんどの処理を担う。
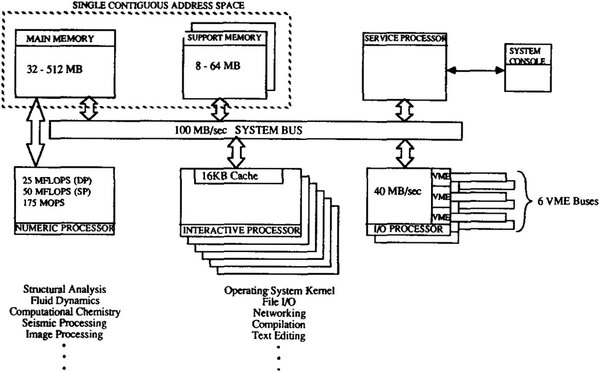
Cydra 5の構成図。Numerical ProcessorとMain Memoryが、System Busを介さずに接続できる構成になっているあたりは非常にわかりやすい
※画像の出典はCydromeの“The Cydra 5 Departmental Supercomputer: Design Philosophies, Decisions and Trade-offs”(http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=47160)。以下の資料も出典は同じ。
I/O向けにはI/O Processorが別に用意され、またシステム管理用にService Processorも搭載されるが、計算処理は別に用意されたNumerical Processorが担うという仕組みだ。
ここでトレードオフとして、Numeric Processor以外は、トータルで10MIPS程度の性能があれば良いと割り切り、比較的低速なプロセッサーを複数並べる構成とした。
ちなみに10MIPSという数値は、Numeric Processorが必要とするデータの読み書きなどをハンドリングするのに、この程度があればなんとかなるという試算だった模様だ。
1984年の時点ではまだ主要なRISCプロセッサーはあくまでペーパープラン、もしくは設計中ということで、唯一利用できる製品はMotorolaの16MHz駆動のMC68020であった。
資料には明示的には書かれていないが、どうもNumeric Processor以外はすべて16MHz駆動のMC68020で実装した模様だ。性能的には33MHzのMC68020で5.36MIPSという数字があるので、16MHzだとおよそこの半分になる。
そこで、MC68020を複数個搭載した。最低限4つあれば合計で10MIPSを超えるが、実際はもう少し多く実装したようだ。
→次のページヘ続く (演算性能を上げるために細かい並列性を高める)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ













ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












