



新市場になってないビッグデータとIoT。日本にあったデータ分析の姿は?
神林節炸裂!Asakusa Frameworkは「分散」から「並列」へ
2015年12月01日 07時00分更新

Hadoop/Sparkは日本市場にあっていない
世界的に見ると、数百ノードを用いたビッグデータ分析はきちんと存在しており、日本市場がむしろ特殊な市場。しかし、中身を見ると、総データ量が同じで、ユーザーの数が違うという現状がある。「米国だと一般企業でも1000ノード以上、数PBのビッグデータが出始めているが、企業はあくまで少数。日本の場合は企業数は多いが、10ノード程度でデータが小さい。そして100~500ノードの真ん中がない」と神林氏は分析する。
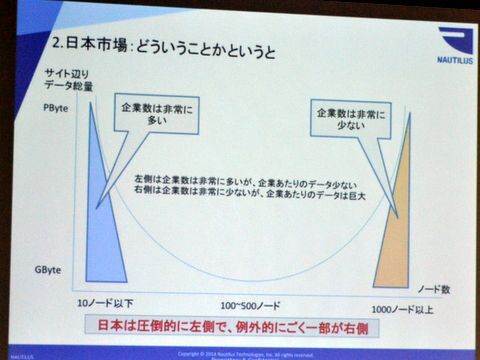
企業は多いがデータが小さい日本企業
この現状を抑えた上で、神林氏はマルチノードの分散処理環境について考察を加える。前提として、分散並列処理環境としてのHadoop/Sparkの優秀さは明らかで、汎用機や大規模なSQLバッチよりはるかに高速。一方で、データ集積の基盤としてのHadoop/Sparkを考えると、日本市場にあきらかにマッチしていないという問題がある。「そもそも100ノード以上の大規模な需要のある米国で開発されているので、日本企業のデータサイズにあわない。だから見ているマーケットサイズとユーザー規模が違うので、効率が悪い」(神林氏)。Hadoop/Sparkはそもそも多数のノードをいかに統括するかをベースにしているので、中小規模のノードをどのように効率化するかの視点が薄い。10~20ノードを効率に動かす代替案がないので、仕方なくHadoop/Sparkを使っているのが日本の現状だという。

データ集積の基盤としてはHadoop/Sparkは日本にあわない
神林氏はHadoop/Sparkのクラスター数に注目する。米国流の1000ノードのクラスターで0.1%の障害率は、つねに1ノードは壊れていることを意味する。つまり、ジョブを走らせている途中に必ず1ノードは故障している計算になるが、もちろん止めることは難しい。そのため、障害対策や復旧に特別な仕組みが必要で、Hadoop/Sparkは当然これらを実装している。しかし、10ノードの場合、0.1%の障害率が顕在化することは少なく、むしろ1ノード故障する方が異常事態になる。「壊れたら、とにかく止める。センスはないが、手動でリスタートすれば、まあ大丈夫」(神林氏)というのが現実的な落しどころだ。

データ集積の基盤としてはHadoop/Sparkのクラスター数と障害対策
こうしたことから、Hadoop/Sparkの障害対策・復旧の仕組み自体がそもそも日本で必要なのかという論に行き着く。Hadoop/Sparkに限らず、分散クラスターは障害復旧がきわめて難しく、つねになにかあるのでノンストップの仕組みが必要になる。これを実現するには、データを同期させたり、余分にデータを持つ必要があるので、アーキテクチャに制約が生じ、オーバーヘッドが大きくなる。「両者はトレードオフの関係にあるので、本来は規模に合わせて調整したい。われわれもさんざんやりましたし、Sparkの開発元にも話したが、できませんと言われました。当たり前だが、彼らは10~20ノードを見ていないので」(神林氏)という。

Hadoop/Sparkの障害対策・復旧のアーキテクチャがそもそも論
Exadataと同じことを1/100の価格で実現できたら?
Hadoop/Sparkが日本市場にあわないこと痛感した神林氏は、Asakusa Frameworkが次に進むべき新しいアーキテクチャについて語る。ムーアの法則が限界に達し、コア数が増え、メモリやバス、I/Oなどの周辺が強化された昨今のハードウェアは、結果として複数のサーバーノードを集約していく方向に進んでいる。インテルの「RackScale Architecure(RSA)」、HPの「The Machine」、AMPLabの「Firebox」などのアーキテクチャでは、インターコネクトやメッシュ状のコア連携、リモートDMAなどを強化し、「サーバークラスターの凝縮化(Condensation)」を実現しつつある。次のAsakusa FrameworkはこのうちインテルのRSAを前提に再設計を施すという。

ムーアの法則が限界に達し、サーバクラスターの凝縮化へ
インテルのRSAでは、バックプレーンを共有するほか、高速なインターコネクト、RDMAのSoC実装、NVMをDIMMソケットで連結するといったさまざまなテクノロジーが投入される。1000コアが透過的に利用でき、メモリを共有できる密結合のクラスターがたかだか10台程度のサーバーで実現できる。このくらいであれば、前述したニーズに十分フィットする。「日本市場だけであんなに高いExadataがバカ売れしているのはなぜか? あれは日本のデータサイズにぴったりだから。RSAと同じような構成をラックの中に全部入れて、1台に見せかけている」と神林氏は指摘する。

インテルのRSAは日本市場に合う
そして、Asakusa FrameworkはこのRSAを前提にエンジンを再設計する。「Oracle Exadataの1/100の価格で、超高速なものが出たらみなさんどうします? やっぱり即効買いますよ。OSSのAsakusaとインテルのコモディティサーバーでExadataと同じことできたら、Hadoop/Sparkは使わないですよね」と神林氏はたたみかける。今までCPUを食いまくっていたRDMAをSoC化し、グリッドとして動作するRSAに今後はコミットするわけだ。
とはいえ、インテルのRSAはまだ市場に登場していない。そのため、今後のAsakusa Frameworkは1ノードでパフォーマンスを徹底的に高める。「並列処理はやりますけど、もはや分散屋ではない」(神林氏)とのことで、メニーコアに特化したエンジンを新たに設計。Hadoop/Sparkが背負っている100ノード前提の障害対策を排除し、高いスループットと低レイテンシを実現するという。

Asakusaの方向性
(次ページ、8時間のバッチが1分を切る!新しいAsakusa Framework)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



