




限られたデコーダを効率よく使う
MicroOps Fusion
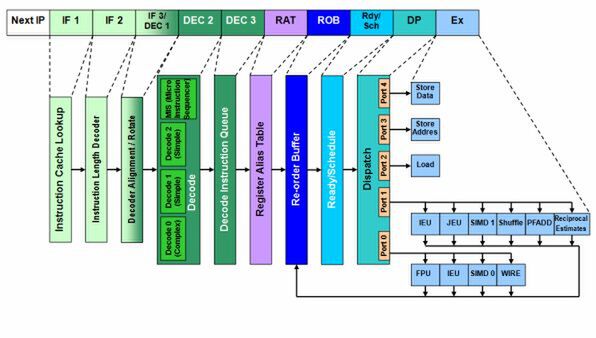
図1 Baniasの内部構造図
- add eax, dword ptr data
P6までは上の命令を2つのμOpsに分けていた。一方、MicroOps Fusionではこれを分けずに、下のようなひとつのμOpに変換して、DEC3以降に渡す。
- load+add EAX, dword ptr data
これによるメリットは2つある。ひとつはDecode Instruction QueueやRe-order Buffer(ROB)の、効率化が図れることだ。前回も触れたが、デコード段(DEC2)以降の内部は、すべてμOpで取り扱われる。DEC3では最大6つのμOpを格納してレジスタの割付を行なうし、その先はROBに格納されて、いわば「実行待機中」の状態になるわけだが、実行待機中の状態にできる命令数は限られる。
そのため、ひとつのx86命令がひとつのμOpに収まれば、その分レジスタ割付を効率化できるし、ROBではより多くの命令を実行待機中の状態にできる。これはアウトオブオーダーにおける実行効率の改善に効果的である。
もうひとつのメリットは、MicroOps Fusionを使うことで、DEC2で「Decode 0」ではなく「Decode 1・2」が使えるようになることだ。前回も説明したが、Decode 1・2はひとつのx86命令をひとつのμOpに変換する「Simple Decode」なので、1対1で変換する場合のみ利用可能である。そのため、これまでは例に挙げた命令の変換にはSimple Decodeを使えず、Complex Decodeである「Decode 0」を使うしかなかった。
ところがMicroOps Fusionを使えば、Decode 1・2で処理が可能になる。これによりデコード能力が(この命令に関して言えば)倍増することになる。もちろんデコード段が倍になったからといって性能が倍になるわけではない。最終的には実行ユニットで処理されるのに、ここの数は変わらないからだ。しかし実行ユニットを、より効率的に利用できるようになったことは大きい。
この方法は、RISC的な考え方からすればやや邪道とも言えるが、実際RISCプロセッサーもこうした複雑な命令をどんどん取り込んだので、現実的な正常進化の範疇である。しかもMicroOps Fusionは、それほど内部構造をいじらなくても実装可能であり、手間がかからないわりには効果的な改善と考えられる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















