




5ポートの実行ユニットを装備
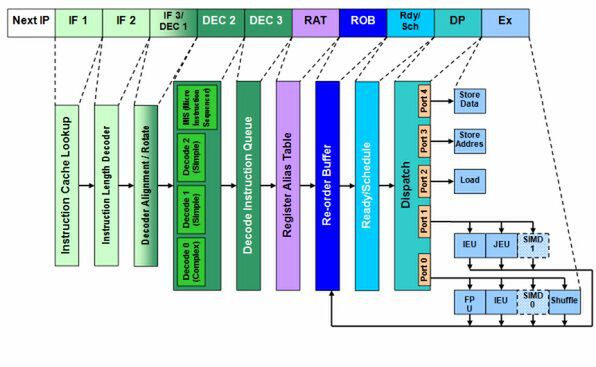
図1 Pentium Proの内部構造図
RATに続く処理が「Re-order Buffer」(ROB)である。これは名前のとおり、命令の並び替えと同時に、終了処理(Retirement)も行なう。ROBはようするに、「今どんな命令の処理を実行中か」の一覧を管理するステージである。ROBそのものはインオーダーであるが、これに続くReady/ScheduleからExecuteまではアウトオブオーダーで実行される。つまり「どの命令がいつ開始され、いつ終了するか」は、ROBにはわからない。
そこで「とにかく実行待機か実行中か、処理完了待ちかはわからないけど、投入はしたよ」という「実行中の命令一覧テーブル」(これをスコアボードと呼ぶ)を管理しているのがROB、ということになる。必然的にROBは、実行ユニットから「この命令の実行を終了したよ」という合図を受けて、その命令をスコアボードから落とす作業も担っている。
ROBから先がアウトオブオーダーでの処理ステージだ。ROBは「現在何μOpが投入されているか」(In-Flightと呼ぶ)を管理し、ゆとりがあるようならばμOpをどんどん追加していく。そうして追加されたμOpは、命令の依存関係などの理由によりすぐに実行できないケースもある。そうした場合に備えて、一時的に命令をプールしておくのが続くReady/Scheduleというステージで、これは一種のキューである。Ready/Scheduledでは最大20個のμOpを格納できる。
このキューから、順次命令を取り出して実行ユニットに振り分けるのが、続く「Dispatch」の処理である。P6の場合、Dispatchには「Port 0」から「Port 4」までの5ポートが用意されて、それらから複数の実行ユニットがぶら下がっている。一番多くの実行ユニットがぶら下がっているのが、Port 0と「Port 1」だ。この2つで整数演算処理やFPU、(Pentium II/III以降で追加された)SIMD演算や特殊命令などを、全部処理している。
1サイクルにひとつのポートから発行されるμOpは、ひとつだけだ。そのため「Load/Store」などのデータ移動「以外」の命令に関しては、Port 0と1の2ポートを使って、1サイクルあたり2命令というのがピーク性能ということになる。
一方Port 2~4は「ロードストアユニット」などと呼ばれることもあり、Port 2はメモリーから(キャッシュ経由で)データをロードして、それを内部レジスタに格納する。一方「Port 3」の「Store Address」は、データをメモリーに格納する際の、メモリーアドレスを計算するユニットである。この計算結果は、「Memory Order Buffer」(MOB、図1では省略)と呼ばれるユニットに渡される。最後のPort 4は「Store Data」で、実際にレジスタのデータをメモリーに格納する処理を行なう。こちらもいったんMOBにデータを格納してから、キャッシュ経由でメモリーに書き戻されることになる。
本来はこれ以外にも、分岐予測がどうなっているのかとか、MOBやRetirementがどうなってるのかなど、細かい話はまだまだある。だが、P6の基本的なアーキテクチャーはこんな構成になっている。x86からμOpsへの変換がある分だけ、デコード段がやや重厚であるが、それを除けばわりと「基本的なスーパースカラー・アウトオブオーダーなプロセッサー」という構成なのが、P6アーキテクチャーだったわけだ。
このP6アーキテクチャーが、続く「Pentium M」や「Core 2」ではどう変化していったのか、というあたりを次回で解説しよう。
この連載の記事
-
第770回
PC
キーボードとマウスをつなぐDINおよびPS/2コネクター 消え去ったI/F史 -
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ - この連載の一覧へ












が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")











