



バックアップを変える重複除外ストレージ「Data Domain」 第2回
同じ重複除外ストレージでもここまで違う
価値のあるD2Dを実現するData Domainの重複除外とは?
2012年01月30日 09時00分更新

前回は、データの大容量化が進む中、磁気テープによるバックアップの限界について見てきた。今回はディスクを使ったD2Dバックアップに高い価値を提供するEMC Data Domainの重複除外技術について、徹底的に解説していこう。
「D2Dなら重複除外が必須!」はなぜか?
バックアップのメディアが磁気テープからHDDに移っていくのは必然的な流れだ。しかし、磁気テープを単にディスクアレイ装置に置き換えただけでは、近年のデータ増大や性能不足、運用管理の増大といった事態に対応できない。その点、EMCのData Domainは重複除外という技術を用いて、バックアップするデータ自体を削減することが可能だ。
重複除外では、データをブロック単位に分割し、同じブロックは重複しているとみなす。そして、構成要素と設計図のみを保持し、同じ内容のブロックが繰り返し書き込まれ、容量を消費するのを防いでいる。さらに圧縮処理を加えることで、ディスクを消費するデータ自体を削減する。Data Domainでは、平均で10~30分の1という削減効果が得られ、最大98%のデータ削減が可能になるという。
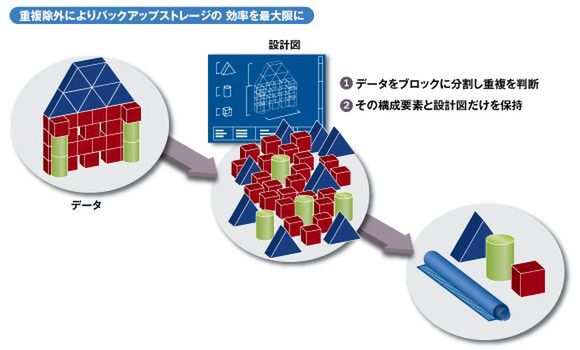
バックアップのデータ自体を削減する重複除外の仕組み
重複除外の効果は絶大だ。対象のデータが減れば、バックアップにかかる時間は大幅に短縮される。オプションソフトウェアである「DD Boost」を用いて、バックアップサーバー側に重複除外の処理を分散させることで、スループットをさらに高めることができる。また、今までのようにデータ量にあわせてディスクを増設したり、増設作業のためにシステムを止める必要もなくなる。
重複除外は、利用期間が長くなればなるほど効果も高くなる。下の図では、金曜日にフルバックアップ、月曜日から木曜日までは増分バックアップという一般的なローテーションにおいて、重複除外がどのように動作するのか示したものだ。いったんフルバックアップを取得してしまえば、増分データのうち同じデータはポインタだけ取得するため、論理容量に対する実際の利用量はどんどん減っていく。この例では本来は2.4TB必要だった容量が、2週目には308GBで済んでいる。削減率としては7.8倍だ。ディスクを消費しないので、バックアップを長期に保持することも可能になる。
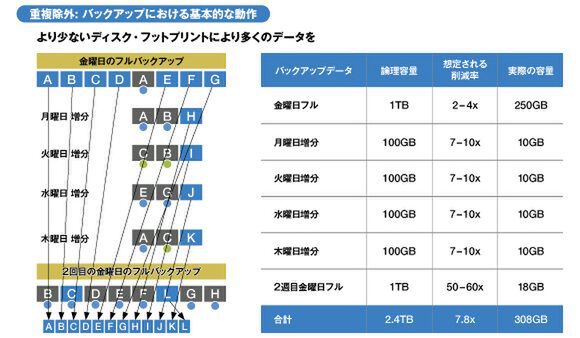
重複除外を用いたバックアップローテーションとその効果
さらに、データ自体のサイズを小さくすることで、磁気テープに頼らず、ネットワーク経由で遠隔地にバックアップが保管できる。大容量ではなかなか実現できなかったWAN経由でのレプリケーションも、データを減らす重複除外を使えば、ネットワークに負荷をかけることもないため、十分に現実的になってくるわけだ。下図のように重複除外で削減されたデータをWAN経由で遠隔地に転送できればよいので、テープ搬送のような手間やタイムラグも発生しない。
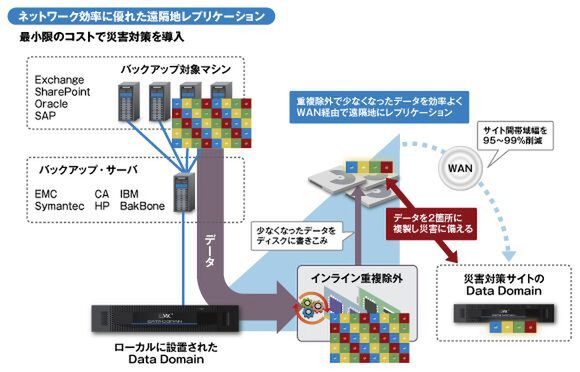
重複除外により、ネットワークを活用したレプリケーションが実現
数ある重複除外ストレージの中でData Domainが選ばれるわけ
シンプロビジョニングやストレージ階層化管理(ティアリング)とともに、バックアップストレージ製品では一般的となりつつある重複除外だが、Data Domainはこれをいち早く実装したストレージとして知られる。製品投入が早かったこともあり、重複除外ストレージとしては圧倒的に高いシェアを誇り、EMCが開発元である米データドメインを2009年に買収して以降も、シェアはいまだに衰えない。
単に製品投入が早かっただけではなく、技術的な優位点もシェア拡大に大きく貢献している。Data Domainと他社製品との技術的な違いとして、「インライン方式」と「ポストプロセス方式」という処理方法の違いが挙げられる。
他社の多くの製品は、いったんデータを保管して重複除外を行なうポストプロセス方式を採用している。しかし、ポストプロセスでの処理は、いったんディスクに保存してから処理を行なうため時間がかかる。8時間というバックアップウィンドウがあったとしても、その後に重複除外の処理を行ない、それが終わってレプリケーションという話であれば、次のバックアップスケジュールが来てしまう。また、データ自体を保存するためにディスク領域が必要になるのも弱点。そもそもデータ容量を少なくするために重複除外のストレージを導入しているのに、重複除外のためにディスクを増やさなければいけないというのは本末転倒といえる。
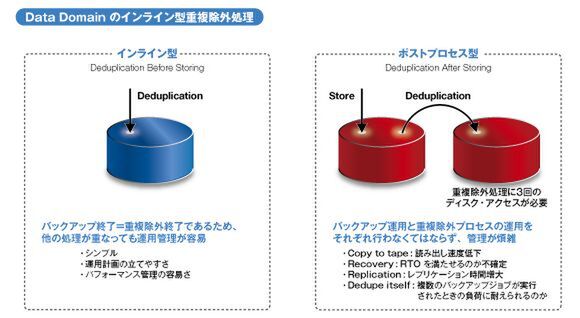
Data Domainが採用するインライン方式(左)と他社製品で多いポストプロセス方式(右)
これに対して、Data Domainではバックアップサーバーから取得したデータに対し、CPUとメモリ上で逐一重複除外の処理をかけていくインライン方式を採用している。インライン方式であれば、小さくなったデータだけをディスクに書き込むため、バックアップやレプリケーションにかかる時間を大幅に短縮できる。
また、重複除外の処理は、データサイズが小さく、ブロックの区切りに柔軟性があったほうが、重複率が高く、除外の効果が大きい。他社製品がファイル単位や固定長ブロックで重複除外を行なうのに対し、Data Domainでは可変長のブロック単位で重複除外を行なう。インライン方式で、精度の高い可変長ブロック単位というCPUに負荷をかける処理でありながら、性能が落ちないのも、ひとえにDataDomainの重複除外アルゴリズムの優秀さ故といえよう。
「100万円から」という低価格なら導入も視野に
とはいえ、処理能力の速さや高い重複除外の効果というメリットの裏腹で、Data DomainはCPUに大きな負荷がかかる設計となっていたため、潤沢なリソースを持ったハードウェアを採用していた。そのため、価格が概して高価で、EMCによる買収前はエンタープライズのユーザーがほとんどであった。
しかし、2011年の2月には、平均で従来の約半額という大幅な価格改定を行ない、中小規模向けの「Data Domain DD610」で200万円強(参考価格)という価格を実現した。そして、2011年11月には3.98TBのローエンドモデル「Data Domain DD160」をリリース。いよいよ「100万円から」という低廉な価格から重複除外を用いた最新のD2Dバックアップを導入できるようになった。最新のインテルアーキテクチャーを採用したハードウェアを採用することで、性能と価格のバランスをきちんととることができたわけだ。もはや、「重複除外は敷居が高い」「Data Domainは高い」という常識は完全に覆されたといえるだろう。
●
次回以降は、このDataDomainがテープ運用と比較してどれだけ容易か、重複除外の効果がどれだけ高いかを実際に調べてみたいと思う。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第4回
サーバー・ストレージ
悩める管理者に贈るData Domainのリアルな検証結果 -
第3回
サーバー・ストレージ
磁気テープを使う管理者Sの嘆きとData Domainへの期待 -
第1回
サーバー・ストレージ
磁気テープのバックアップをやめるこれだけの理由 -
サーバー・ストレージ
バックアップを変える重複除外ストレージ「Data Domain」 - この連載の一覧へ



