



ロードマップでわかる!当世プロセッサー事情 第879回
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略
2026年06月08日 12時00分更新

前回予告したように、今回もコネクティビティについてだ。ISSCC 2026でNVIDIAのNikola Nedovic博士(Sr.Research Scientist)が発表した"Emerging Low-Latency Optical Connectivity"の内容を解説したい。
なぜAIに新たなネットワークが必要なのか?
フロントエンドとバックエンドの分離
そもそも光接続を利用するニーズはなにか? として博士が指摘するのはまず消費電力。PUE(Power Usage Effectiveness:IT関連施設におけるエネルギー効率を測定する指標)は2023年の段階で1.58程度になっているが、もうこれ以上下がらない(むしろ上がっている)のがわかる。
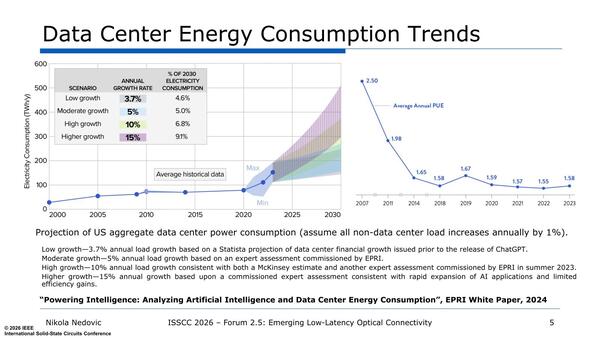
PUEとは「設備全体の消費電力÷IT機器の消費電力」であって、2023年の実績では付帯設備(冷却や電源供給など)がIT機器の消費電力の58%近くに達しているという意味になる
加えて全体の消費電力も上がる傾向にあるのは言うまでもない。さらにIT機器そのものの電力も上がりつつある。例えば1Pbpsの転送速度が求められる時代に、転送効率が5pJ/bitだとするとその転送だけで5kWの消費電力になる。
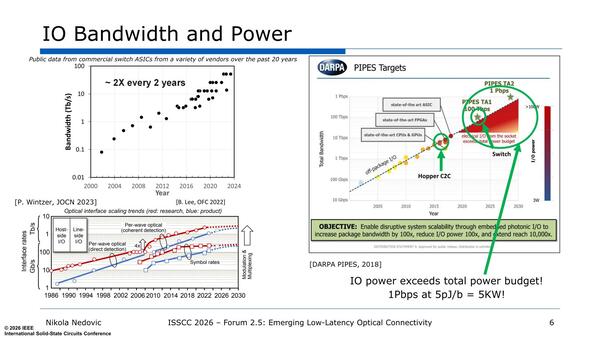
転送効率が5pJ/bitだとすると転送だけで5kWの消費電力になる。前回のグラフを見てもらっても、5pJ/bitの達成すら難しいことがわかるだろう
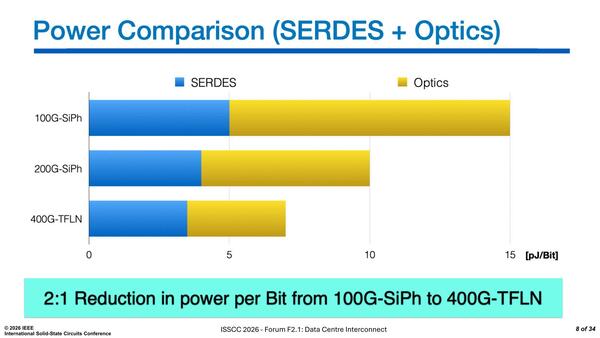
前回のグラフ
実はこの消費電力問題、もうそんなに先の話ではない。というのは以前のアナウンスでは今年後半に登場するKyberラックベースのRubin Ultra NVL576ではNVLinkが1.5PB/秒(=12Pbps)、CX9(つまりイーサネット)が115.2TB/秒(=921.6Tbps)になる予定だった(NVL576そのものの構成が変わったため現在はこの数字にはならない)からで、仮に1pJ/bitまで下げてもNVLinkが12KW、イーサネットが1KWを喰う計算になる。
これをなんとかしようと思った場合、特に帯域が増えるとどうしても銅配線を利用する電気信号では消費電力が爆増する(あと距離が伸びた場合も同じく)ということで光配線しかない、という話になる。講演ではこの後光接続を利用した場合の帯域や特性、BERの検討などが論じられているが、これは新しい話ではないのでここでは割愛する。要するに光接続はすでにコストを含めて有望な選択肢になっている、という話だ。
ではデータセンターの現場はどうなっているのか? というのが下の画像だ。AI FactoryというのはNVIDIAの造語であって一般的な用語ではないと思うが、AIデータセンターは従来型のクラウド用データセンターと比べてプロセッサーの数が5倍、消費電力は20倍近くに跳ね上がる。

データセンターの構造。40MW程度で済んでいるうちはまだ可愛かったのだが……
問題はその100Kなり512Kなりのプロセッサーをどうつなぐかである。下の画像はやや古いネットワーク構成であって、コア-アグリゲーション-エッジという3層のスイッチを経てその下にCPU(サーバー)がぶら下がるFat-Tree構成である。
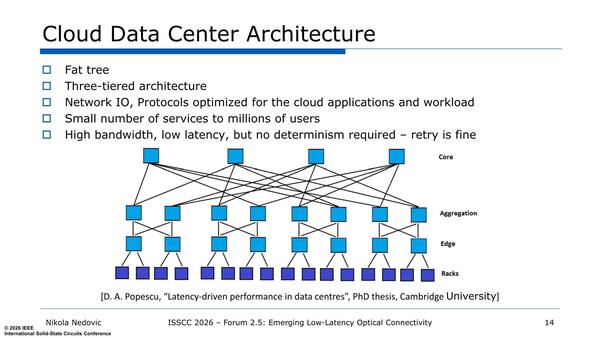
Leaf-Spineは単にコアとアグリゲーションのつなぎ方に工夫を凝らしただけで、本質的にはFat-Treeとあまり変わらない(スイッチ台数の違いなどはあるが)ともいえる
これ以外のものとしては、例えばHPのDragonFlyや、京あるいは富岳で採用されたtofu interconnect(6次元メッシュ/トラス)構成などがあるが、これは例外的である。最近ではこれがLeaf-Spine構成になっているわけだが、ただFat-Treeの2次元的な接続をLeaf-Spineの3次元的な構成に変えたからといって劇的に性能が変わるわけではない。
こうした従来型のネットワークの場合、レイテンシーが大きくなると性能が急速に低下するケースが多い(アプリケーション次第)というのは以前から知られていた話である。
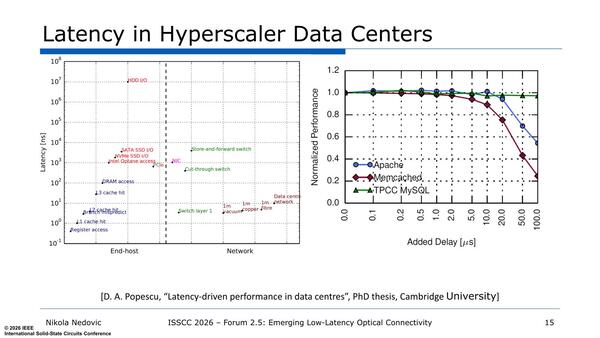
左図は主要なアクセス手段とそのレイテンシーをまとめたもの。右はレイテンシーが大きくなると性能がどう低下するかを示したもの。TPCCのMySQLのように、最初からレイテンシーが大きいことを盛り込んだアプリケーションなら性能低下が抑えられる。問題はなんでもこうした対処が可能ではないことだ
これがAIデータセンターではどうなっているのか? というのが下の画像である。従来型のネットワークによる接続(Front End)とは別に、GPUというかアクセラレーター同士を接続するネットワーク(Back End)を用意することになっている。
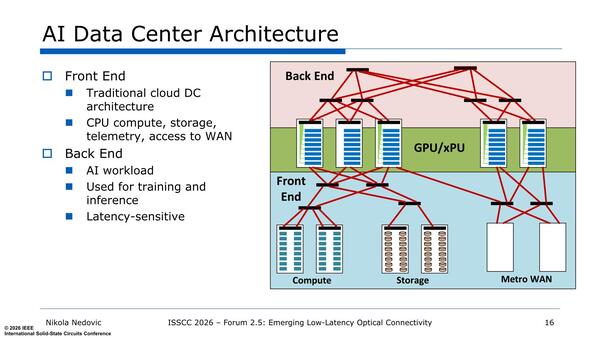
NVIDIAで言えばFront EndがCX9を使った従来型イーサネット、Back EndがNVLinkである
レイテンシーが大きくても構わない接続はFront Endを、レイテンシーを低く抑えたい接続にはBack Endを使おう、というわけだ。このFront Endをスケールアウト、Back EndをスケールアップとNVIDIAでは定義している。
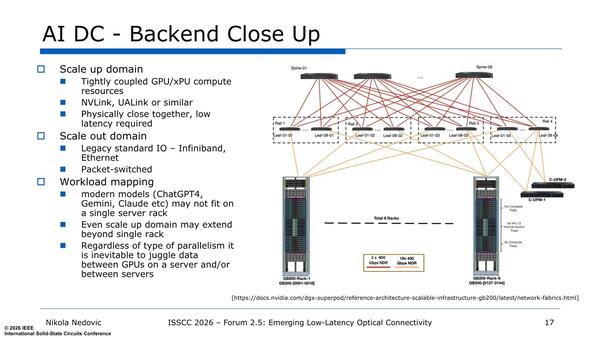
InfiniBandでもスケールアウト扱いである。また、パケットスイッチは基本的にスケールアップには向かないとしている
この2つをどう使い分けるか、の説明が左下のWorkload mappingに示されている。要するに大規模なLLMなどでは、1枚どころか1本のラックですら足りないくらいに規模が大きくなっており、こうした用途で必要としている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












