




ComfyUIの弱点、Claude Codeで克服も
今度はもっとアバウトにリクエストを出してみます。「ゴッホと浮世絵を混ぜたような絵」、「東京で怪獣と戦車とが戦っている絵」、「水没した東京の廃墟を泳ぐクジラ」、「巨大な猫が東京を占拠」。それぞれにお題を出すだけで、Claude Codeがプロンプトを設計し、ComfyUIに指示が出され、次々に画像が作られていきます。もちろん、もっと詰めていくならば、それらのプロンプトの中身を検討して作り込んでいくこともできます。

ゴッホと浮世絵を混ぜたような絵

東京で怪獣と戦車が戦っている絵

水没した東京の廃墟を泳ぐクジラ

巨大な猫が東京を占拠
さらに画像を参照させて、それに似た画像を分析させて作らせることができます。
1枚目は、左下の明日来子さんがハイキックをしている画像をClaude Codeに読み込ませ、これに近い画像を作るようにと指示して作った画像です。2枚目はアニメキャラに近いキャラクターで、銃を構えているようにと指示したものです。画像のリファレンスを行っているわけではないので、テキストのプロンプトのみでのディティールの再現には限界がありますが、一定の再現性を持たせた画像を作ることができています。
これらのことはComfyUIの中だけも、カスタムノードやLLMなどを組み込むことで実現ができるのですが、いちいちプロンプトを修正したりといったことをしなくとも、Claude Codeにテキストで指示するだけで修正ができるため、圧倒的に簡単になります。

AIモデルの明日来子さんがハイキックをしているもの(左下)を真似させた

アニメ風キャラクター(左)に銃を構えさせた
これらのものはZ-Image Turboだけではなく、ComfyUIで制御できるものであれば、他のモデルでも同じように制御可能です。例として、前回紹介した、動画AI「LTX-2.3」の「WhatDreamsCost」を使った複数枚動画を同じ仕組みで生成してみることにします。(参考:「無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか」)
ゲストキャラの田中さんの正面からの画像を元に、上から下へとカメラワークが変化するという動画を作ることにします。その角度の違う画像は、アリババの「QwenEditImage-2511」と「Multiple Angles LoRA」を使います。これは正面カット1枚あれば、そこから斜め上から、斜め下まで別のカットを作ることができます。これも同じように、AIに指示して撮影する角度を指示して作成します。
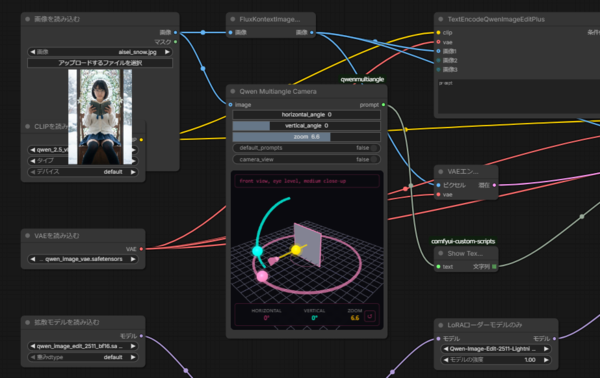
QwenEditImage-2511とMultiple Angles LoRAのComfyUIのWorkflowの一部

生成された田中さんの画像。中央の画像を参考に、右側から角度を変えた画像が作られている
この5枚の画像のリンクを、Claude Codeに読み込み、LTX-2.3の環境に入力データとして入れるよう指示することで、一貫した動画をつくることができます。また、画像内容も解釈させて、適切なプロンプトを作成させます。そして、画像を生成します。
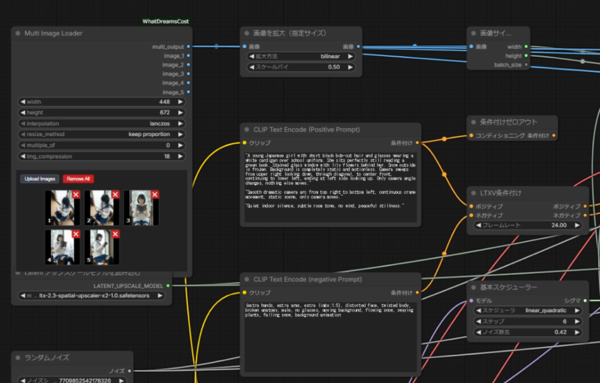
LTX-2.3 WhatDreamsCostのWorkflowの一部。生成した動画のメタデータを再度開いた状態なので、配置は変わっている
△生成された結果。カメラがスムーズにつながっている
ComfyUIで、1台のPCで作業する場合に、画像AIと動画AIを連続的に生成する場合には、手作業で切り替える必要があります。それぞれのAIのモデルを同時にVRAMに展開しているとサイズの問題から溢れてしまう可能性があるため、同じWorkflowにまとめて組み込むことが推奨されません。
しかし、Claude Codeで制御すると、画像AIを使って画像を生成したあとに、違うWorkflowの動画AIにその画像を読み込んで動画を生成するということまでが、制御可能になります。自動で一連のフローを自動で回せるようになります。Claude Codeが手足としてComfyUIを使うことで、複雑なワークフローも、より簡単に、より連続的に扱うことが可能になるのです。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










