




ローカルLLMの実力は?
ベンチマークでは高い性能が示されているが、実際の使い勝手はどうだろうか。ローカルLLMで重要なのは、日常的な質問に自然に答えられるか、画像やコード生成といった実用的なタスクをどこまでこなせるかだ。ここでは実際にLM Studio上でQwen3.5-9Bを動かし、日本語応答、画像理解、コーディング能力などを確認してみる。
日本語での応答品質
まずは日本語での応答品質から確認してみよう。ローカルLLMでは、文法は通っていてもどこか翻訳調の文章になるケースが少なくない。しかしQwen3.5-9Bの場合、日本語の語順や助詞の使い方が自然で、一般的な質問にも違和感のない文章で回答できる。
例えば「ローカルLLMとは何かを初心者向けに説明して」というプロンプトを投げると、専門用語を避けながら概念を整理した回答を返してくれた。
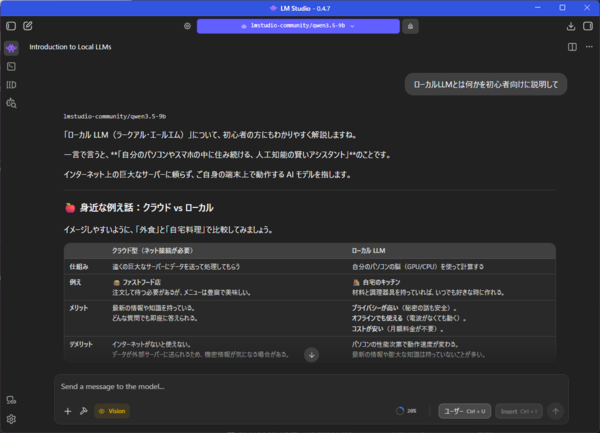
また、文字数指定や箇条書きなどのフォーマット指定にもきちんと従うため、文章生成や要約といった日常的な用途なら十分実用的な品質と言える。
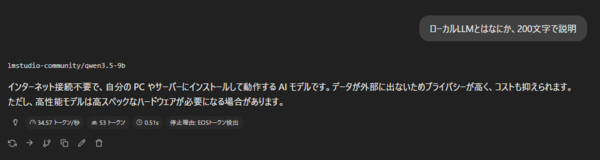
特に印象的なのは、日本語特有の文体の扱いだ。「100字以内で説明」「箇条書きで整理」「例を挙げて解説」といった条件を付けても破綻が少なく、指示をきちんと守った回答を返してくる。前節のベンチマークでも指示追従(IFEval)で高いスコアを記録していたが、実際のチャットでもその傾向ははっきり感じられる。
Vision(画像理解)
次に画像理解能力を確認してみよう。Qwen3.5-9Bはテキストだけでなく画像も入力として扱うことができ、内容の説明や状況の把握が可能だ。ローカルLLMでは画像入力に対応していないモデルも多いが、本モデルは日常用途でも十分使えるレベルに達している。
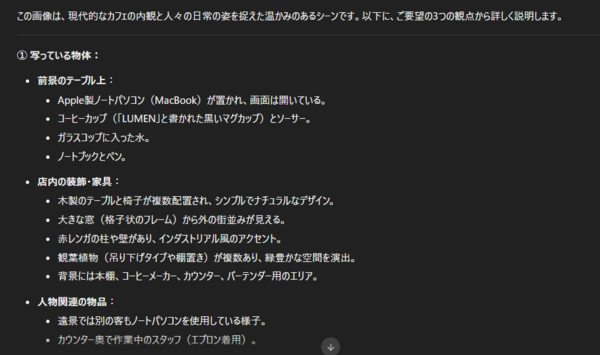
例えば風景写真を入力して、写っている内容や雰囲気を説明するよう指示すると、被写体や状況を整理しながら自然な日本語で説明を返してくれる。

単なる物体認識にとどまらず、「どのような場面か」「どのような用途の環境か」といった文脈レベルの理解も行えるため、構成要素の整理や用途の推測を含めた説明が可能だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第46回
AI
面倒なファイル整理、AIに丸投げできる? 「Claude Cowork」をガチ検証 -
第45回
AI
面白すぎて危険すぎ! PCを“勝手に動かす”AI、OpenClaw(旧Moltbot/Clawdbot)とは -
第44回
AI
「こんなもの欲しいな」が、わずか数時間で形になる。AIツール「Google Antigravity」が消した“実装”という高い壁 -
第43回
AI
ChatGPT最新「GPT-5.2」の進化点に、“コードレッド”発令の理由が見える -
第42回
AI
ChatGPT、Gemini、Claude、Grokの違いを徹底解説!仕事で役立つ最強の“AI使い分け術”【2025年12月最新版】 -
第41回
AI
中国の“オープンAI”攻撃でゆらぐ常識 1兆パラ級を超格安で開発した「Kimi K2」 の衝撃 -
第40回
AI
無料でここまでできる! AIブラウザー「ChatGPT Atlas」の使い方 -
第39回
AI
xAI「Grok」無料プラン徹底ガイド スマホ&PCの使い方まとめ -
第38回
AI
【無料】「NotebookLM」神機能“音声概要”をスマホで使おう! 難しい論文も長〜いYouTubeも、ポッドキャスト化して分かりやすく -
第37回
AI
OpenAIのローカルAIを無料で試す RTX 4070マシンは普通に動いたが、M1 Macは厳しかった… - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





