




高性能の秘密はグーグルの“力業”か
この仕組みはどうなっているのか。AIエンジニアの動詞さんがその仕組みを解説しています。2025年3月に書かれた記事と基本的には同様であろうと推測されています。
重要なのは、画像も音声もテキストもすべてをリファレンスできるモデルに入れる「Any-to-Any(すべてからすべて)」の考え方です。従来は画像やテキストが別々にAIを学習させていましたが、すべて抽象概念として処理してトークン化してしまい、一つのモデルで学習させてしまう。そうすることで、種類を問わずにそれぞれのトークンを参照できるようにするというものです。
2023年12月に発表された米アレン人工知能研究所が中心になって実施した研究「Unified-IO 2: 視覚・言語・音声・動作を統合した自己回帰型マルチモーダルモデルの拡張」では、any-to-anyモデルである「Unified-IO 2」が、テキスト、画像、画像の変化過程、オーディオ、オーディオの変化過程といった情報を入力することで、様々なバリエーションのあるデータを出力できるようになると説明されています。
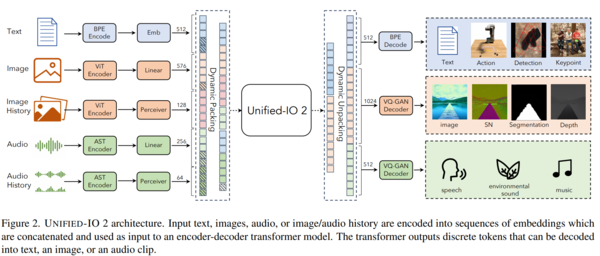
「Unified-IO 2: 視覚・言語・音声・動作を統合した自己回帰型マルチモーダルモデルの拡張」のP.4より
また、学習量を増加させれば、その性能が向上することが証明されています。10億、30億、70億とパラメーター数を向上させると、学習の失敗が減少する傾向がはっきりと出ており、モデルのスケールアップをすると予測力を着実に上げるというスケーリング則が観察できることがわかっています。単純に言えば、この方式は、多数のデータで学習を進めれば進めるほど性能が上がるということが証明されているのです。
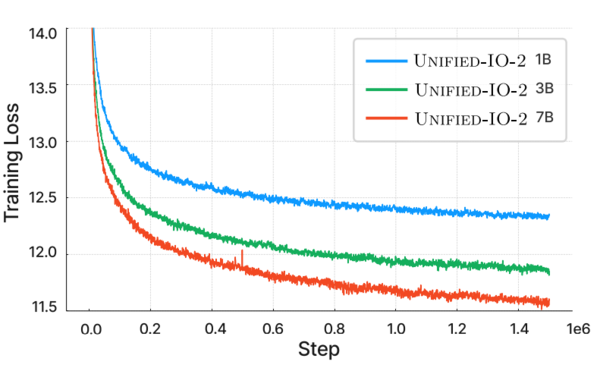
「Unified-IO 2: 視覚・言語・音声・動作を統合した自己回帰型マルチモーダルモデルの拡張」のP.5より
関連する研究は、2023年末から2024年初めにかけて登場したとされていますが、グーグルはそれらの研究を取り込み、データも計算資源も豊富に持っているために、強力に学習を進めて今回のモデルを作成できたということでしょう。要するに、方法論は確立されており、力業で、実現までたどり着いていると言えるのです。
この連載の記事
-
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に -
第139回
AI
AIフェイクはここまで来た 自分の顔で試して分かった“違和感”と恐怖 -
第138回
AI
数百万人が使う“AI彼女”アプリ「SillyTavern」が面白い - この連載の一覧へ








とは")





































