




動作させるだけで一苦労、コミュニティも活発とはいえず
また、実際にローカル環境で動作させようとすると、筆者の環境でもかなり苦労しました。
そもそもが、入力するプロンプトを画像にするために解析するテキストエンコーダーを4種(Llama、T5-XXL、CLIP-G、CLIP-L)も使います。Flux.1 Devの場合は3種類だったため、テキストの理解力はこの追加により引き上げられているのかもしれません。しかし、当然ですが、その分、VRAMの使用量が増加します。量子化(軽量化)が小さいfp16モデルだとそれぞれ34.2GBもあり、fp8モデルでも17.1Gもあります。さらにClipも読み込むわけですから、VRAMが多く必要になるわけです。
とはいえ、全体をフルパッケージで自動的にインストールしてくれるような便利なインストーラーは存在しないようで、WebUI A1111系にも対応していません。そのため、最初のファイルの設定はかなり戸惑いました。この時点で、挫折する人は多そうな気がします。
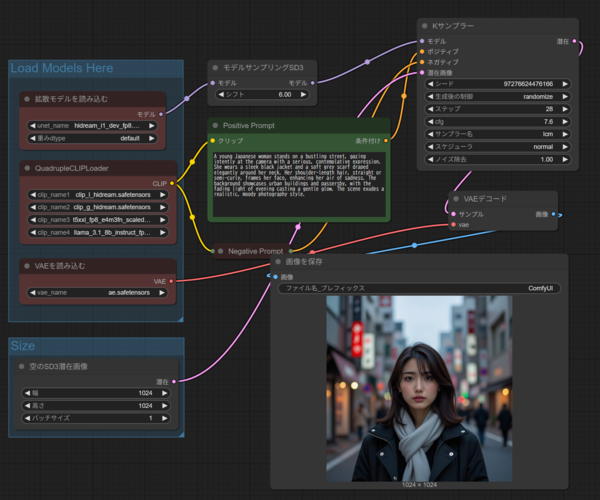
ComfyUIが公開しているHiDream-I1にネイティブ対応したサンプルワークフロー。特徴は対応するために新たに作られた4種のCLIPを読み込み可能にした「Quadruple CLIP Loader」(ComfyUIリンク)
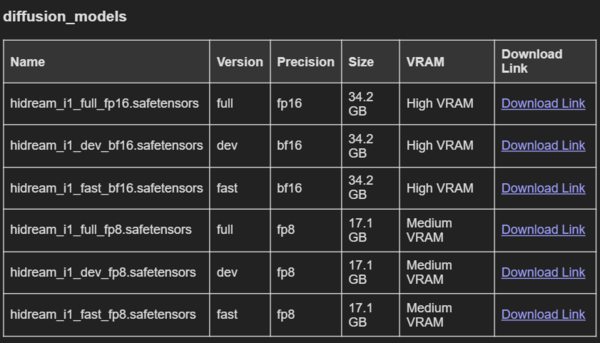
ComfyUIワークフローで使用できるモデルの一覧表。量子化(圧縮)されていても、かなりサイズが大きい
なによりHiDream-I1には課題があります。一定量の強力な性能を誇りながらも、エコシステムを作るところに苦戦していることです。
いずれのモデルも厳しい制限がないMITライセンスで公開されており、商用利用についても大きな制限がかかっていないという使いやすさがあります。しかしながら、公開されているHuggingFaceのダウンロード数は、Devが3万2000、Fullが4万で、Fastが6万3000にとどまっています。FullとFastの2モデルの公開は一定の成功を収めているとは言えるものの、すでに公開から250万回以上ダウンロードされているFlux.1 Devに比べると、現状のユーザー数は大きく見劣りします。
LoRAなどの追加学習データを作りやすい環境も登場していないようで、ユーザーが公開したLoRAの数も少なく、あまりコミュニティは活発ではないようです。同様に、ControlNetといった画像を制御するための追加モデルも開発されている気配はまだありません。
やはり要求スペックが高すぎることもあり、利用者をかなり選んでしまうことや、性能の高さがあるにしても、多くのユーザーにとっては既存のエコシステムから急いで切り替えたいと感じさせるほどではないといったことが原因なのでしょう。また、そもそもの画像が、少し中国風に寄りすぎているという印象もします。

連載のオリジナル作例キャラクター「明日来子さん」の画像から、プロンプト解析して生成した画像。うまく雰囲気は出ているが、それでもどこか中国っぽさを感じる(HiDream-I1-Devで作成)
本来はライセンスとしても使いやすいモデルのはずなのですが、サービス展開しているAIクラウドサービスも限られており、「Replicate」や「Fal.ai」といったクラウド時間貸出型の一部サービスに限られています。Fullバージョンの公開が4月と後発であることもあって、今後の広がりを目指していくことになると思われますが、特に欧米圏での認知が遅れているという印象です。もちろん、中国語圏で開発されたという強みがあり、中国では支持されているようですが、それでもAPI展開には中国政府の検閲規制もあるために中国本土向けにも思うように広げることができない事情もあるようです。
ただ、4月28日には「HiDream-E1-Full」というというimage-2-image(画像から画像)に対応したモデルを追加で発表しました。ユーザーの画像をより自分の意図通りにコントロールしたいというニーズに応えようという努力は続けています。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第165回
AI
AIがBlenderを勝手に操作 3D制作のハードルが一気に下がった -
第165回
AI
社内WebサービスをAIで開発 完成後に直面した運用の壁 -
第164回
AI
AIはすでに、私たちの心を内部で再現しているのかもしれない -
第163回
AI
無料の画像生成AI「Krea 2」が話題 実写もアニメもこなす新勢力 -
第162回
AI
ローカルAIで“しゃべる推理ゲーム”を作ったら、思ったよりちゃんとゲームになってきた -
第161回
AI
わずか3日で停止された新AI「Claude Fable 5」は何がすごかったのか -
第160回
AI
寝不足になるほど面白い ローカルAIと音声合成をつないだら、キャラが普通にしゃべり始めた -
第159回
AI
AIを使える人と使えない人で、とんでもない差が出ると実感した理由 -
第158回
AI
SDXLの次はこれ? アニメ特化のローカル画像生成AI、驚きの実力 -
第157回
AI
AIだけでゲームは作れるのか? Codexに7本作らせて見えた実力と限界 -
第156回
AI
ChatGPTの画像生成AIは本当に最強か Nano Bananaと比べて見えた“弱点” - この連載の一覧へ


















ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




