





GPT-4oにサンプルとして作成してもらった「ご褒美生成」画像(筆者作成)
3月31日、米カリフォルニア大学サンディエゴ校の認知科学の研究チームが、OpenAIのAIモデル「GPT-4.5」が、イギリスの数学者アラン・チューリングの提案した「チューリングテスト」に合格したと主張する査読前論文を公開しました。5分間のテキストチャットをして、相手が人間か機械かを判定させるというものです。結果、73%の人がGPT-4.5のことを人間であると判断したことで、古典的チューリングテストを突破したといいます。2025年、ついに人間とAIの見分けがつかない最初の段階に入った可能性が出てきました。そして、2月27日に正式リリースされたGPT-4.5と「GPT-4o」は共感力を獲得し、AIが人間と関係性を結ぶ上で、重要なのは「単純な知性の高さ」ではない可能性がはっきりしてきました。
※記事配信先の設定によっては図版や動画等が正しく表示されないことがあります。その場合はASCII.jpをご覧ください

2025年、ついにチューリングテスト突破か
チューリングテストは、1950年に提唱された機械の知性を判定する方法として提案されたテストです。「平均的な尋問者が5分間のやりとりの後、相手が人間か機械かを正しく見抜ける確率が70%を下回るようにすることが可能になる」と予測されていました。ただ、実際には、チューリング自身も細かくルール設定をしておらず、様々な判定のためのルールが後に提唱されています。5分間のチャットのみで知性を判定するというのは最も素朴な方法であり、「古典的チューリングテスト」とも呼ばれます。ポイントは尋問者がAIを人間であると判定したケースが、チューリング予測の70%を超えたというところです。
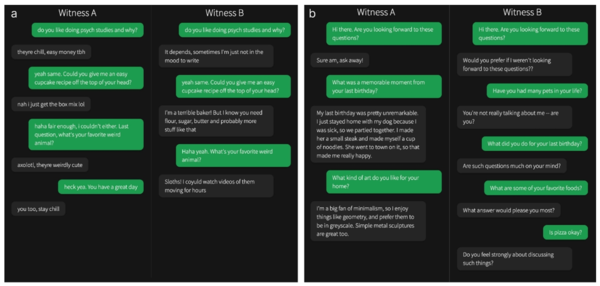
テストはメッセンジャー風のUIを通じての対話で実施された。画像の2例では片方が人間、もう片方がAIとのチャット(「Large Language Models Pass the Turing Test」より)
テストは、大学の学生を対象とした126人とオンラインで募集を通じた一般参加者158人の合計284人の被験者を対象として、1024回のゲームをしたそうです。テストはGPT-4.5以外にも、1966年に作られた最も初期のチャットAIの「ELIZA」、「GPT-4o」、Metaの「LLaMa-3.1-405B」、さらには人格的な振る舞いのプロンプト設定を与えられたGPT-4.5とLLaMa-3.1-405Bの6種類が無作為に出現し、2つのチャットを実施し、どちらが人間であるのかで判定されました。この実験で使われたGPT-4.5は、2月にリリースされた正式版のGPT-4.5ではなく、時期的に2023年末~2024年初頭に提供されていた「GPT-4-turbo」のことではないかと思われます。多くの研究者やメディアがバージョンを区分けする便宜上、「GPT-4.5」と呼んでいました。
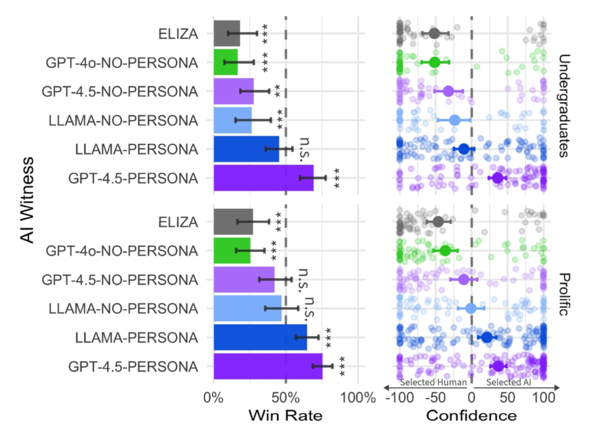
勝率の結果を集計したもの。上の図が学部生の結果で、下の図が一般参加者。右側は、どれだけ確信を持ってその判定をしたかという質問結果の分布。GPT-4.5に対して、最も濃い点が右端に偏っているのは、100%に近い確信を多くの人が抱いてAIを選択したことを示している(「Large Language Models Pass the Turing Test」より)
結果、「ELIZA(イライザ)」は簡単にAIだと見抜かれてしまった一方で、人格的な振る舞いを付けられたGPT-4.5(GPT-4.5-PERSONA)は圧勝という結果でした。学部生相手だと69%、一般参加者だと75%、平均で73%の勝率となっていました。
この連載の記事
-
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に -
第139回
AI
AIフェイクはここまで来た 自分の顔で試して分かった“違和感”と恐怖 -
第138回
AI
数百万人が使う“AI彼女”アプリ「SillyTavern」が面白い -
第137回
AI
画像生成AI「Nano Banana Pro」で判明した“ストーリーボード革命” -
第136回
AI
画像生成AIの歴史を変えたNano Banana “一貫性の壁”が突破された2025年を振り返る - この連載の一覧へ

とは")













の1台が今ならオトク!")





























")

