



ロードマップでわかる!当世プロセッサー事情 第791回
妙に性能のバランスが悪いマイクロソフトのAI特化型チップMaia 100 Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月30日 12時00分更新

クラスター同士の接続はメッシュ・ネットワークを経由
Maia 100の内部はTensor Unit(TTU)とVector Engine(TVP)、それとデータ移動用のTile Data Movement Engine(TDMA)、Tile Control Processor(TCP)とL1 SRAMから構成されるタイルが基本単位である。
このタイルを4つとNOC、L2 SRAM、CCP(Cluster Control Processor)とCDMA(Cluster Data Movement Engine)から構成されるクラスターがある意味処理の最小単位である。Maia 100はこのクラスターを16個搭載する。
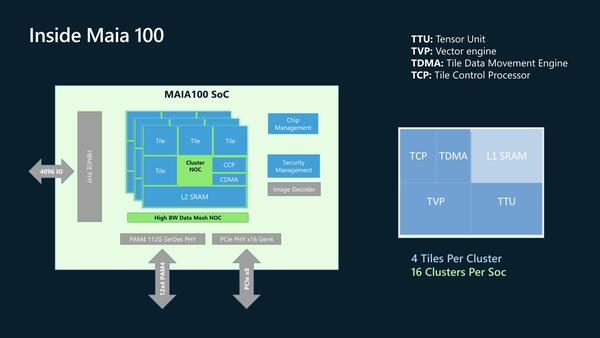
後で出てくるが、クラスター同士もNoCでつながるわけで、つまりNoCが二重になってる形だが、実際にはクラスター内のNoCはもう少し軽量なものなのかもしれない
ちなみに先程6bitマシンと言ったが、それが実装されているのはTTUの方であって、TVPの方はFP32やBF16をサポートするというあたり、比較的普通の8bitマシンベースのSIMD Engineの模様だ。

Vectorの方は、あるいはRISC-Vあたりのコアをベースにカスタムで作り、そこにSIMDエンジンをつないだという構造かもしれない
特徴的なのはまずDMA Engine。単にL2 SRAMとL1 SRAMの間でデータ交換をするのみならず、6bitデータと9bitデータの型変換までしてくれるようだ。
Hardware Semaphoreだが、これはCCPとTCPの間での制御に用いられるようだ。そもそもタイルの中でTVPとTTU、それとブロック図には出てこないがRead Copy Engine/Write Copy Engineの4つのエンジンは独立して勝手に動作する。この4つのエンジンの制御はTCPのお仕事なのであるが、4つのタイルの間で作業を分割するようなケースでは、タイル間の同期を取る必要があり、ここでHardware Semaphoreが利用されるということらしい。
クラスター間の同期にも使われるかどうかは不明で、こちらはメッシュ・ネットワークを経由してのデータフロー式なのかもしれない。そのクラスター同士の接続方法が下の画像だ。
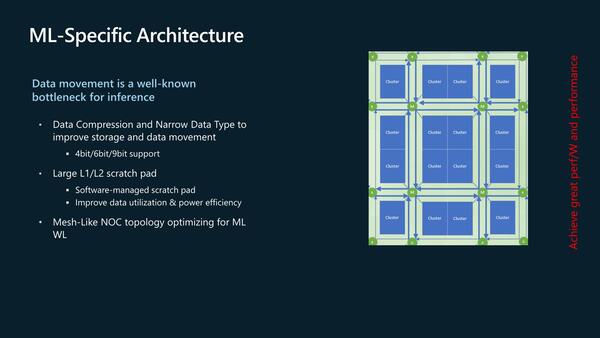
クラスター同士の接続方法。NOCにしたのは、データサイズがけっこういろいろある(4/6/9bit)ことに起因しているからかもしれない。L1/L2 SRAMはどちらもスクラッチパッド扱いで、おそらくこれはTCPおよびCCPによって制御されるのだろう
一見すると良くあるメッシュ構成であるが、よく見ると、4つのMesh Stop(図中の(M))から4つのクラスターに線が伸びているあたり、データの移動をする場合、以下の過程になる。
(1) あるタイルのL2 SRAMからCDMA経由でネットワークのMesh Stop((M)部)にデータを送り出す。
(2) 送られたデータは、目的のタイル(が接続しているMesh Stop)に転送される。運が良ければ1hopで転送できるが、運が悪いと2hopかかる。
(3) Mesh Stopから目的のタイルのL2 SRAMに送り込まれる。
ここで謎なのは、だとしたら「そもそもメッシュ要らなくね?」という話である。4クラスターごとに1つMesh Stopがあるから全部で4つのMesh Stopでいいわけで、それならそもそもMesh Stop同士を相互接続するのはそれほど難しくないだろう。
あと、もう一度上の画像を見ると、(M)とは別に(x)という別のMesh Stopがチップの周辺に置かれているが、この(x)の用途が明らかにされていない。
ここからは筆者の想像なのだが、実はこの(x)は、Chip-to-Chip接続のためのMesh stopなのではないかと考えている。つまりチップレット的に複数のMaia 100を接続可能であり、その際には個々のチップの(x)同士がインターコネクト(UCIeかなにかだろうか?)で接続されるという方法だ。
正直この程度の規模でメッシュライクなNOCを使うのはやや大げさすぎる。が、もしチップレット的に複数チップを接続して使うのであれば、メッシュ風にするのは極めて妥当である。
難点を挙げるとすれば、現在公開されているMaia 100チップはもうパッケージに載せているので、この状態では複数チップを相互接続するには配線長が長すぎて現実的ではないことだ。ただ現状公開されているのはMaia 100が1個のバージョンで、現在複数のMaia 100を搭載するパッケージを開発中だとすれば、これは大きな問題にならない。
Maia 100は単体で820mm2の巨大なダイで、それにHBM2Eが4つ付くから、全体の面積は軽く1000mm2を超える。これを複数搭載しようとすると、巨大なシリコン・インターポーザーが必要になるが、TSMCのCoWoSでこれが可能になるのは早くて2026年だろう(現状でも80×80mmのパッケージは作れるが、これでは2つ載るかどうか微妙なところだ)。
ゆえに、この世代ではメッシュの実装はするものの、複数チップの接続を実際に行なうのは次世代Maia向けといったところが実情ではないかと考える。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























