




文字を取り出す
この文字先頭位置から「書記素クラスタ」(文字)を取り出すには、GetNextTextElementメソッド(https://learn.microsoft.com/ja-jp/dotnet/api/system.globalization.stringinfo.getnexttextelement?view=net-7.0)を使う。このメソッドは、コードポイントが複数あっても、1つの書記素クラスタ分を文字列として出力してくれる。
具体的には、ParseCombiningCharactersの出力(文字の先頭位置)を、2つ目の引数に入れて文字(書記素クラスタ。セグメント)を取り出す。ParseCombiningCharactersの出力する位置を変数に入れおく。
$p=[System.Globalization.StringInfo]::ParseCombiningCharacters($x)
次にこれを使って、文字を順次取り出す。
$p | foreach-object { [System.Globalization.StringInfo]::GetNextTextElement($x,$_)
とすればよい。
ついでに16進数でダンプさせるなら、
$p | %{ $t=[System.Globalization.StringInfo]::GetNextTextElement($myKatu,$_); "$_ $t`t$(([int[]][char[]]$t)|%{$_.ToString('X4')})" }
などとする。
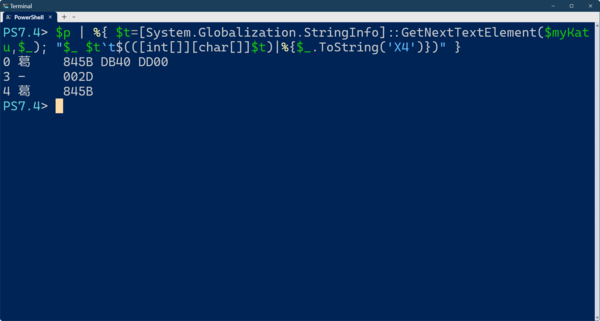
「葛󠄀-葛」という文字列を16進数で表現すると、「葛󠄀」は、ベースとなる文字のコードポイントである「0x845B」に異字体セレクタがついたものになる。ただし、異字体セレクタは、UTF16では、Dから始まるサロゲートペアになるため、先頭の「葛󠄀」は、文字列中では、3つの16 bitワードで表現される
サンプルとしてもう少し複雑な文字列を使ってみる。
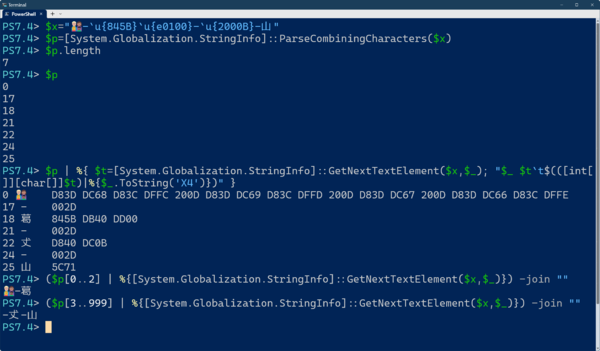
さらに複雑な文字列を$xに定義する。先頭は家族4人の絵文字でそれぞれに肌の色を指定してある。その次に異字体セレクタのついた文字、さらにサロゲートペアになる文字、最後の通常漢字を半角ハイフンでつなげてある。書記素クラスタは7つ。先頭から3文字(書記素クラスタ3つ)を得たければ、範囲指定演算子とGetNextElementメソッドを使って先頭3つの書記素クラスタを取り出して-join演算子で繋ぐ。文字列後半を取り出したい場合にも同様に、後半部分を取り出して結合すればよい
これは、家族4人の絵文字と異字体セレクタ付きの文字、サロゲートペアになる文字、それ以外の漢字の4つをハイフンでつなげたもので、$xに代入してある。まずは、$pに文字列内の先頭位置を格納しておく。このとき$p.lengthが書記素クラスタの数(文字数)となる。
$p=[System.Globalization.StringInfo]::ParseCombiningCharacters($x)
$p.length
$p
たとえば、先頭から3文字目(葛󠄀)までを取り出したいなら、
($p[0..2] | %{[System.Globalization.StringInfo]::GetNextTextElement($x,$_)}) -join ""
とする。前半の$p[0..2]は、3つ目の書記素クラスタの開始位置までの開始位置を取り出すもの(配列のインデックスなので0から始まることに注意)。後半の部分は、GetNextTextElementを使って、書記素に対応する文字列を取り出し、全体を-joinで結合して1つの文字列としている。
同様に後半4文字目から最後までを取り出したいなら。
($p[3..999] | %{[System.Globalization.StringInfo]::GetNextTextElement($x,$_)}) -join ""
とする。「[3..999]」は、書記素開始位置配列の4文字目から最後までを取り出すもの。範囲演算子では、対象配列の最大インデックスが分からないとき、それよりも大きなインデックス値を指定(ここでは999)を指定しておけば、エラーにならず、最大インデックスを指定したのと同等になる。もちろん「$p[3..($p.Length-1)]」などのように正しく計算してもいいが、最大インデックスを超えない大きな数を使うほうが簡単だ。
このようにすることで、文字列の前半部分(Left関数)、後半部分(Right関数)のようにユニコード文字列を正しい位置で分割することができる。
ユニコードになって、さまざまな文字を扱えるようになった反面、単純な文字列処理が不可能になり、今回のように、StringInfoクラスなどを使ってテキスト・セグメンテーションをして、その上で、分割などの処理をする必要がある。
なお、ユニコードの正しいテキスト・セグメンテーション(前述のUAX#29)には、.NET 5.0以降の対応なので、処理には、PowerShell(pwsh.exe)のほうを利用する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第521回
PC
Windowsでアプリをインストールしたときに警告が表示する「Defender SmartScreen」と「Smart App Control」 -
第520回
PC
WindowsターミナルのPreview版 v1.25では「操作」設定に専用エディタが導入 -
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")























