





アップルは8月9日、新しい画像生成AIモデル「Matryoshka Diffusion Models(MDM)」およびフレームワーク「ml-mdm」をGitHubで公開。高品質な画像生成AIを効率的に訓練、実行することが可能になった。
複数の解像度の画像を同時に生成
MDMは2024年4月にアップルの機械学習研究チームが論文で発表した画像生成AIモデルだ。
従来の画像生成AIは図のように、一つの大きな画像を段階的に作り上げていく手法を用いていた。

従来の画像生成AI
これに対しMDMは複数の解像度の画像を同時に生成する画期的な方法を採用している。

MDMの画像生成
さらにこの図が示すように、MDMは小さな画像から大きな画像まで並行して生成し、それぞれの情報を相互に活用しながら画質を高めていく。加えて、画像生成の全過程でテキストなどの情報を常に参照することで、与えられた指示に忠実な高品質な画像を効率よく作り出すことを可能にしている。
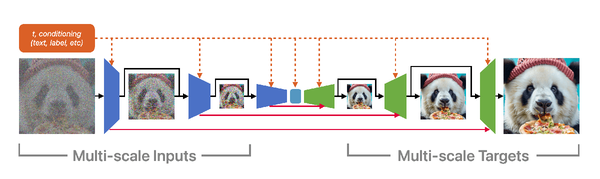
MDMの画像生成
この手法により、MDMは多様で高品質な画像を、従来よりも効率的に生成することができるのだ。
1200万枚のデータセットを使った訓練も可能
GitHubで公開されたml-mdmは、このMDM技術を実装するためのPythonフレームワーク、喩えるなら「説明書付きの工具セット」だ。
そこには、MDMモデル本体はもちろん、訓練・推論・可視化といったコード、さらには1200万組のテキストと画像のペアからなる大規模なデータセット「CC12M(Conceptual Captions 12M)」のダウンロードと訓練の手順まで含まれている。
ただし、CC12Mで学習させたモデルは、ライセンスの制約により公開できないため、代わりにアップルは権利がクリアされた「Flickr2017」データセットで事前学習させたモデルを提供している。
初心者は事前学習モデルで手軽に、研究者はCC12Mで学習させたより高性能なモデルを利用できるという仕組みだ。
開発者コミュニティーでの普及を狙う
MDMは複数の解像度で画像を同時に生成することにより、効率と画質を向上させている。この技術は将来的に動画生成にも応用可能であり、特に広告やメディアコンテンツのカスタマイズなどに大きな可能性があると考えられる。
また、アップルがこのモデルをオープンソースで提供する意図は、単に技術共有を促進するだけでなく、技術的なエコシステムを形成し、開発者コミュニティをアップルの製品向上に結びつけることを目的としていると考えられる。
さらに、市場での技術的優位を確保し、競合他社に対する先行利益を得るための手段としても機能するだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















