



“データをためる”と“データを活用する”の2製品が解決する課題、得られるメリットを知る
「HPE Ezmeral」がシンプルに実現する大規模データ活用の姿とは
2024年08月09日 11時00分更新

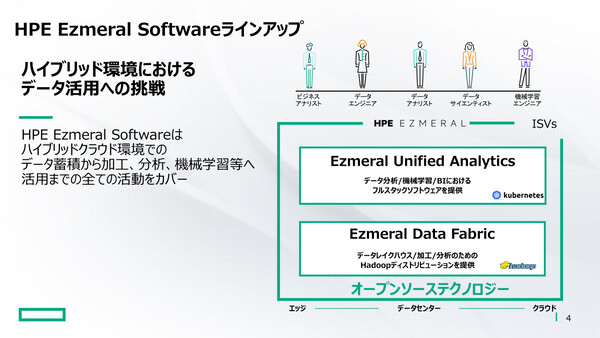
「HPE Ezmeral Software」は、ハイブリッドIT環境における「データをためる」と「データを活用する」をシンプルに実現するソフトウェア製品
日本ヒューレット・パッカード(HPE)が現在、国内への展開に注力している統合データプラットフォーム「HPE Ezmeral(エズメラル) Software」。なぜHPEがソフトウェアを? 統合データ基盤「HPE Ezmeral」に注力する理由を率直に聞いた
HPE Ezmeralには「データをためる」HPE Ezmeral Data Fabricと、「データを活用する」HPE Ezmeral Unified Analyticsの2製品がラインアップされている。この2製品は一緒に導入することも、個別に導入して他社製の既存システムと連携させることも可能だ。今回の記事では、それぞれの製品が持つ特徴やメリットについて、できるだけシンプルにご紹介したい。
「データのサイロ化」問題を解消するHPE Ezmeral Data Fabric
まずは「データをためる」HPE Ezmeral Data Fabricから見ていこう。これは2019年に買収したMapRのデータプラットフォーム技術をベースに、機能強化を重ねてきたソフトウェア製品だ。
企業が自社データから新たな価値を引き出すためには、社内にいるすべてのデータユーザーが、あらゆるデータに対して柔軟にアクセスし、活用できる環境が重要である。しかし、多くの企業では今なおデータがシステムごとに分断されている。これが「データのサイロ化」問題である。
サイロ化したデータ環境では、そもそもどんなデータが存在するのかがわからず、柔軟にデータを組み合わせた分析もできない。さらにはデータ管理の手間やコスト、セキュリティ、コンプライアンス(個人情報保護、データレジデンシーなど)にまつわる課題も生じる。とは言え、現在のIT環境はハイブリッド化が進んでおり、データの発生源は複数の場所(パブリッククラウド、データセンター、エッジ)に分散している。生成されるデータ量も急増を続けており、すべてのデータを一カ所に集めて管理することは困難だ。
こうした数々の課題をシンプルに解消するのがHPE Ezmeral Data Fabricだ。地理的に分散された複数のデータソースにある幅広いタイプのデータを仮想的に統合して、単一のデータプレーンを提供することで、すべてのデータに対して迅速かつ柔軟にアクセスできる環境を提供する。一つのプラットフォームに集約することにより、管理やセキュリティ、コンプライアンスといった課題も、よりシンプルに解消できる。
分析/AI向けのデータレイクハウスとして、HPE Ezmeral Data Fabricが格納できるデータのタイプ(フォーマット)は幅広い。ファイル、オブジェクト、NoSQL、ストリーム、ドキュメントなど、企業が扱う多様なデータをひとまとめに格納することが可能だ。そして、いったん格納したデータはさまざまなベンダーの分析ツールから標準的なAPIを通じてアクセスできるようになる。
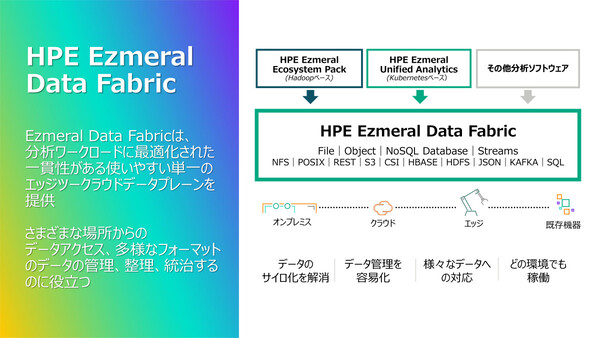
「HPE Ezmeral Data Fabric」の概要
グローバルに分散配置してもデータへのアクセスはシンプル
HPE Ezmeral Data Fabricの特徴のひとつが、「グローバルネームスペース」によるデータ管理/データアクセスだ。たとえば、HPE Ezmeral Data Fabricは複数の場所(データセンター、パブリッククラウド、エッジ)にクラスターを分散配置することが可能だが、すべてのデータは単一のグローバルネームスペースで管理される。つまりユーザーは、データの実体がある場所を意識することなくアクセスできる仕組みだ。
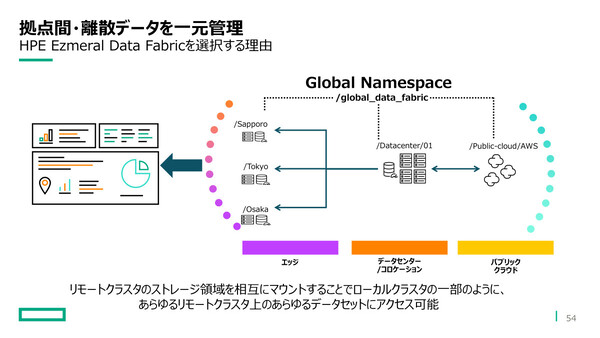
「グローバルネームスペース」によって、データがどこにあっても意識することなくアクセスできる
高いスケーラビリティも特徴だ。「Apache Hadoop」互換の高速分散ファイルシステムをベースに構築されており、エクサバイト級まで拡張できるスケーラビリティを持つ。このファイルシステムの上に、「Amazon S3」互換のオブジェクトストア、NoSQLデータベース、Pub/Subサービスなどを備える構成だ。
ハイブリッドクラウド環境やグローバル展開企業の場合は、処理パフォーマンス(レイテンシ)を改善するため、分析対象のデータをできるだけ身近な場所に置きたいというニーズもあるだろう。HPE Ezmeral Data Fabricは、クラスター間でのデータのクローニング(レプリケーション)機能を持つので、それが簡単に実現できる。
さらに、ストレージの階層化にも対応している。利用頻度の低いデータを「Amazon S3 Glacier」のような低コストのクラウドストレージ(アーカイブ層)に自動移行させることで、ストレージコストを節約しつつ、グローバルネームスペースを介していつでもデータアクセスできる環境になる。
さらに、オプション製品「HPE Ezmeral Ecosystem Pack」を追加すれば、Hadoop関連のソフトウェア群(Spark、Hive、Kafkaなど)も商用サポート付きで利用できるようになる。データ加工、データパイプライン作成といった高度なデータ処理を、HPE Ezmeral Data Fabric側で実行できる仕組みだ。
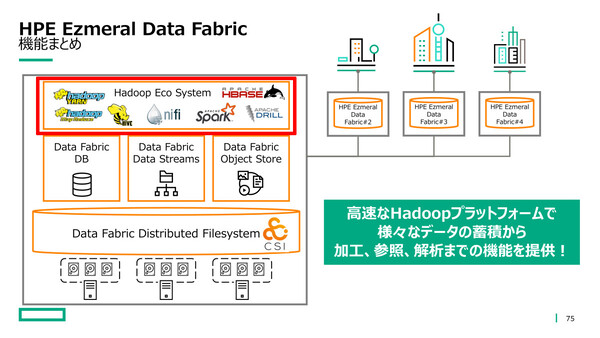
HPE Ezmeral Data FabricはKubernetesの永続ボリューム(CSI)も提供する。さらにオプション(赤枠部分)を追加すれば、Hadoop関連ソフトウェアを使った高度なデータ処理まで可能になる
データのセキュリティについては、ディスク内のデータと転送中のデータを暗号化しているほか、粒度の細かな認証/認可によるアクセス制御、さらにすべてのイベントをログ記録する監査の仕組みを備えている。データレジデンシー要件に対応する「ジオフェンシング」機能もある。これらのセキュリティの管理も一元化されるので、管理負荷の軽減とセキュリティレベルの底上げが両立できる。
グローバルではエンタープライズでの導入が進んでいる。たとえばメルセデス・ベンツグループでは、自動運転車開発のためのグローバルなデータプラットフォームとしてHPE Ezmeral Data Fabricを導入した。このデータプラットフォームは、テスト車両から1日あたり3PB超のデータが取り込まれ、1日あたり1.5PB規模のデータ処理が行われる大規模なものだ。世界中から数千人のエンジニアやパートナー、データサイエンティストがアクセスするため、テストデータはグローバルに展開するクラスター間で同期されており、データ活用の効率化につながっているという。
また、特に日本企業では「重要なデータはクラウドに上げず、オンプレミスに保持したい」という要求が強いが、そうしたケースでも役立つ。オンプレミスにHPE Ezmeral Data Fabricを配置してデータを蓄積し、分析に必要なデータだけをダイレクト接続されたクラウド環境に転送して処理を行う、というかたちだ。こうした柔軟なデータ環境が構成できるのも、HPE Ezmeral Data Fabricの特徴である。



