




Lunar LakeのGPU動作周波数はおよそ1.65GHz
Vector Engineの構造もだいぶ変わった。というよりもともとのXeが変だったのかもしれないが、従来は2つの256bit Vector Engineで1つのスレッドコントロールを共有する、つまり1つのスレッドコントロールが2つの256bit Vectorを管理する)という構造で、それぞれ別にレジスターファイルを持つ構造だったのが、今回1つにまとめられることになった。
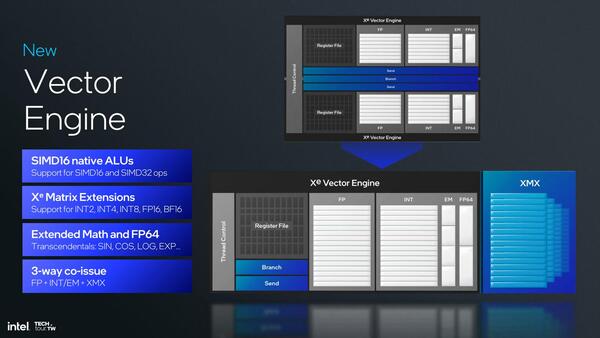
扱えるデータ型などには違いがないし、3-way co-issueも以前からと同じである
おそらくはこれによって、内部のスケジューリングが多少簡単になり、それが冒頭の画像に出てくる"Higher utilization"につながっていったと考えられる。
ちなみにMXMの構成は1サイクルあたり2万48Ops(FP16)ないし4096Ops(INT8)となっており、これは現在のIntel Arcで利用されているXe-HPGのものと同じ性能である。

Xe-HPC(Ponte Vecchio)はこの2倍の性能であるが、構成的にそこまで搭載するのは難しかったものと思われる。性能とのバランス、という話だろう
ここからLunar LakeにおけるGPUコアの動作周波数が推定できる。上の画像にあるように、XMXはINT8なら4096 Ops/サイクルとなっている。これとは別にVector Unitの方ではDP4A命令が実行できる。
MXMはMeteor Lakeの時代にも搭載されていたもので、XeSSなどでも利用されているものだ。その処理性能をまとめたのが下の画像であるが1024 Ops/サイクルとなっており、合計で5120 Ops/サイクルとなる。
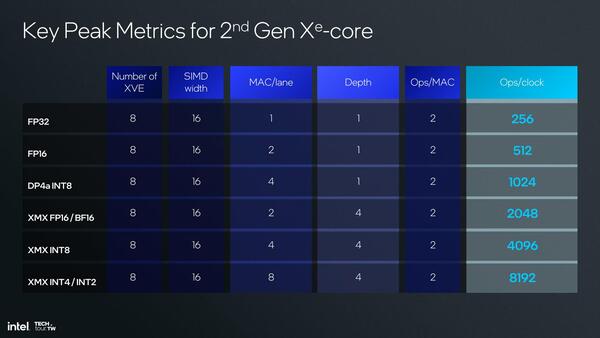
Xeコアあたりのスループットそのものは、(XMXの有無を除くと)Meteor Lake世代から変わらない
これはXe-Core1つあたりの処理性能なので、8 Xe-CoreのLunar Lakeでは4万960 Ops/サイクルとなる。この処理性能で67TOPSを実現しようとすると、動作周波数は1.6357...GHzとなる計算だ。
1.6GHzでは65.5TOPS、1.65GHzだと67.6TOPSほどになるので、現実問題としては1.65GHzで、これを丸めて67TOPSと称しているのではないかと推定できる。
この数字、Meteor Lake世代は1.75~2.35GHzとやや高めだったことを考えると低いという感じもするが、前回説明したようになにしろメモリー帯域がMeteor Lakeよりも低めである。
また前回説明はしなかったが、Memory Side CacheはGPUからアクセスできないことが質疑応答の際に明らかになっている。これはどういうことかというと、Memory Side CacheをGPUのワークエリアとして利用することは一切想定していないという話である。
8MB程度では、テクスチャーキャッシュ、あるいはレイトレーシング用のワークエリアとしては明らかに不十分であって、しかも前回の筆者の推定が正しければMemory Side Cacheはスヌープキャッシュやライトバックキャッシュとしても使われるため、GPUに割けるような領域はほとんどないだろう。
ということは、Lunar LakeはMeteor Lakeと比べても6割程度のメモリー帯域でGPUのやりくりをしないといけないわけで、無駄に動作周波数を上げてもメモリー帯域が間に合わないからGPUが空転することになりかねない。この1.65GHzというのは、メモリー帯域を使い切るギリギリの数字なのかもしれない。
ちなみにVector EngineやXMXだけでなく、レイトレーシング・ユニットの強化も行われている。ただこれに関しては、Meteor Lakeの時代からどの程度向上したのかが明確にされていない。

BVHはBounding Volume Hierarchyの略で、レイトレーシングの交差判定を高速化するための階層的なデータ構造を指す。この下でボックスを処理できるトラバーサル・パイプラインを3つ搭載しているのがわかる。この例ではボックスはウサギ全体だが、この箱をさらに細かく分割することで、よりリアリティのある描画になる
効率は間違いなく向上しているのだろうが、絶対性能という観点で見るとMeteor Lakeと比較して同等くらいが精いっぱいかと想像される。理由は、レイトレーシングもまたメモリーアクセスを多用するためだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































