




Pコアのハイパースレッディングを廃止
ALUはALUが同時に6個動作するほか、シフトや乗算(MUL)、分岐(JMP)も3つずつに増量された。

iDIVはMISCに含まれてしまったのかここには出ていないが、そろそろ×2くらいになっていても不思議ではない
またFPU/Vectorも同時4命令処理に拡充されている。FMAが256bitとあることからもわかるように、まず間違いなくAVX512は実装されていない。ただほぼ同じアーキテクチャーを利用すると想定されるGranite Rapidsの場合、V0~V3にAVX512の実行ユニットを追加する形になると思われる。

FP ALUは64bit幅なので、同時に稼働すると256bit相当となる。また除算(Div)も×2に強化された
データキャッシュも変更になった。Golden Cove~Redwood Coveでは48KBのL1 D-CacheとL2という組み合わせだったが、Lion CoveではL1 D-CacheがL0 D-Cacheになり、新たに中間的なLatencyを持つ192KBのL1 D-Cacheが追加された。

L1をL0に改称したのは、Pコア全体の共有キャッシュがL3なので、逆算してL0にせざるを得なかったのだろう。構造的に言えば追加されたものがL1.5 D-Cacheという感じではある
つまりデータ側はL0~L3まで4レベルのキャッシュ構造となった格好だ。レイテンシーも若干削減されているが、帯域幅自体は変わらないことになっている。
そして実行ユニットが強化された分、ロード/ストアーユニットも当然強化する必要がある。AGUが6個となり、またロードアクセスとストアーアクセスの両方が3個づつになった。これに合わせてData TLBのエントリー数も96→128に強化されている。

Store Dataそのものは2ポートのまま変わらずなので、ピークのStore Bandwidthは変わらない(そもそもL0 D-CacheのBandwidthが変わっていないからこれは当然だが)。ただ、同時により多くのStoreを発行できるようになったことで効率を上げられる
もう1つの大きな変更は、Pコアでハイパースレッディングを無効化(というか、削除)したことだ。ハイパースレッディングというか一般にSMT(Symmetric Multi-Threading)のメリットは以下の2つある。
- メモリーアクセスのレイテンシーの遮蔽(あるスレッドがメモリーアクセス待ちをしている間、他のスレッドがコアを利用することで、無駄な待機時間を減らす)
- 実行ユニットの利用効率向上(アウト・オブ・オーダー実行では、必ずしも全部の実行ユニットがフルに使われるとは限らないので、複数スレッドを同時に実行することで実行ユニットの利用効率を上げる
インテルがPentium 4にハイパースレッディングという名前でSMTを実装した時の最初の目的は2番目であり、これで最大30%性能が向上する、とされていた。実際現在でも、ハイパースレッディングを有効にした場合、IPCないしスループットが30%ほど向上し、その一方で消費電力が20%ほど増加するとしている。20%の消費電力増加で30%性能が向上するなら、これは悪くないバーターなわけだ。
ただ、Lunar Lakeの場合には少しシナリオが異なる。もともとMeteor Lakeの頃からそうだが、雑多な処理はEコアに任せて、処理負荷の重い物だけをPコアに行なわせることで効率を上げるのがインテル・ハイブリッド・テクノロジーであり、これを効果的にするためにAlder Lakeで導入されたのがインテル・スレッド・ディレクターである。
そしてデスクトップ向けはともかくLunar Lakeの使われ方を考えた場合、シングルスレッド処理性能が高いのが重要で、Pコア全体でのマルチスレッド処理はそれほど重要視されないシナリオが考えやすい。こうなると、ハイパースレッディングというかSMTはむしろシングルスレッドの性能を妨げる要因になりえる。
つまり本来なら効果的に全部の実行ユニットをフルに使うことで性能が上げられるはずなのに、SMTを利用することで別のスレッドと実行ユニットの取り合いになる可能性があるからだ。
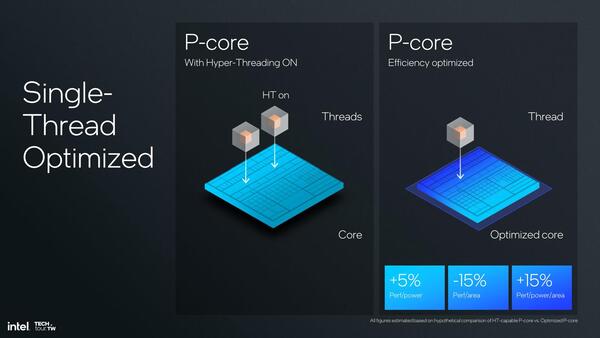
性能/エリア比が落ちているのは、SMTを無効化したことでトータルの性能としては落ちているため。シングルスレッド性能で比較するとおそらく向上している
またSMTを実装する際には、ある程度エリアサイズのオーバーヘッドが発生する。以前Core 2の時は10%程度とされていたが、具体的には完全にスレッドごとに独立して持つもの(例えばPC:Program Counterなど)はそれほど多くない。
ただ、例えば内部のレジスターファイルは、どちらのスレッド用かを管理するために1bitの管理フラグを追加する必要がある(から、64bit長のものが65bit必要になる)といった具合に、あちこちに余分な回路が必要であり、そうしたものの合計が大体10%ほどになるわけだ。
これはデスクトップあるいはサーバー向けには許容されるのだろうが、前回も説明したようにギリギリまで面積を詰めたいLunar Lakeにはこの10%も惜しかったのだろう。
そしてSMTを無効化することで、消費電力も若干減る(扱うスレッドが1つで済むから、スレッド間の調停も不要だし、SMTをサポートするための回路もなくなる分、そこで費やしていた消費電力も削減できる)。こういう判断に基づき、Lunar Lakeではハイパースレッディングが廃止された。「無効化」ではなく「廃止」なのだそうで、物理的にLunar Lakeではハイパースレッディングが利用できなくなっているらしい。
このあたりはまだ明確ではないが、おそらくLion CoveもXeon向けに利用されるだろう。それがGranite Rapidsなのか、その次のDiamond Coveなのかは不明だが、こうした転用を考えた場合、ハイパースレッディングの機構そのものは論理設計上は残っており、ただしそれを物理設計に落とす段階で機構そのものを省いた、という形で実装されていると筆者は考えている。これは、同じダイをEPYCとRyzenで共有する(からSMTを無効化することはできても省けない)AMDとの違いである。
なお、2022年頃はGranite RapidsはRedwood Coveベースという報道もあったが、あれからだいぶロードマップが変わっているので、まだRedwood Coveベースなのかは不明で、Lion Coveベースの可能性もある。
こうした改良の積み重ねで、Lion CoveのIPCは平均14%の向上を実現したとされている。特に消費電力が少ない(≒動作周波数が低い)時のIPC向上率は18%以上としており、これでSnapdragon Xシリーズに搭載されたNuvia由来のOryonコアを圧倒したい、というわけだ。
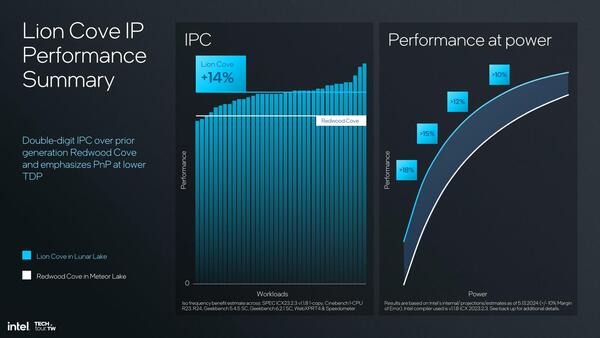
Copilot+ PCの動作環境を考えると、TDPはかなり低め(15W前後?)を想定しており、その枠で性能を引き上げるためには右図のような特性がどうしても必要、ということでもある
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")




























")













