





メタは6月18日、テキストだけでなく、メロディー、コード(和音)進行、リズムパターンなど複数の要素をプロンプトとして使用できる音楽生成AIモデル「JASCO(Joint Audio and Symbolic Conditioning)」を発表した。
理論と実践の両面から制御
JASCOの最大の特徴は、その多様な入力方法だ。テキスト、メロディー、コード進行、リズムパターン、音楽の一部など様々な形式の入力を受け付けられる。そのため、楽譜上の情報と実際の音声を同時に扱えて、理論と実践の両面から音楽を制御できるという。
デモサイトには実際に聞くことができるサンプルが用意されている。
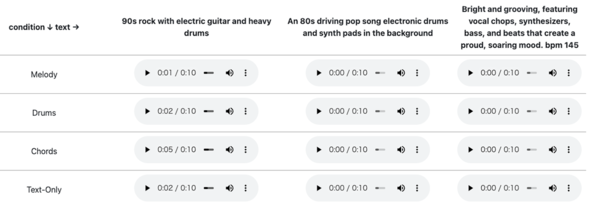
「Melody Conditioning(メロディーによる調整)」では、入力されたメロディーとテキストに基づいて音楽を生成する。
ここでは「ボレロ(ラヴェルによる管弦楽曲)」のメロディーと、「An 80s driving pop song electronic drums and synth pads in the background(電子ドラムとシンセパッドを使った80年代のポップソング)」というテキストで生成された楽曲を聞くことができる。

「Drums Conditioning」では、入力されたドラムパターンとテキストに基づいて音楽を生成する。
通常のドラムだけではなく、ヒューマンビートボックス(口や声だけを使ってドラムを再現すること)などの素材もドラムパターンとして利用できる。

「Chords Conditioning」では、入力されたコード進行とテキストに基づいて音楽を生成する。
下図では「C→F→G→C→F→G→C→F→A7」というコード進行と「Reggae with ukelele and percussions(ウクレレと打楽器を使用したレゲエ)」のようなテキストで生成された楽曲が生成されている。

「Audio Conditioning」では、入力された既存の音声や音楽の一部とテキストに基づいて音楽を生成する。
既存の音楽のリミックスや、特定のアーティストのスタイルを模倣した楽曲の生成などに活用できるだろう。

「Sample Sandbox」では、オーディオデータを元に異なるテキストでどんな音楽が生成できるか試すこともできる。
「Flow Matching」による柔軟な制御
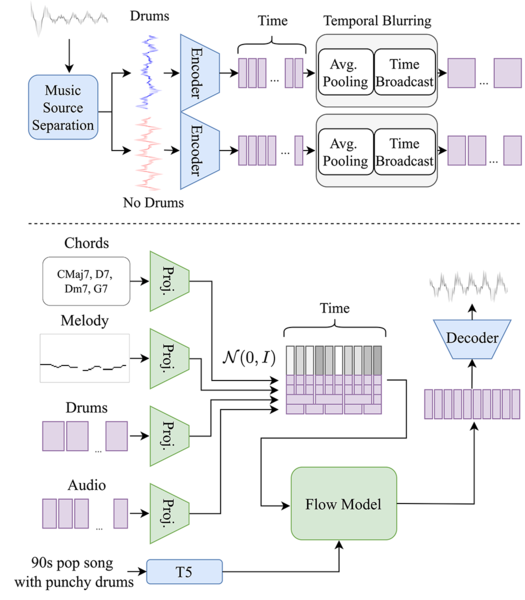
JASCOは「Flow Matching」という、ランダムなノイズから目的の音楽データへの連続的な変換過程をモデル化する新しい機械学習手法により、高品質で多様な音楽生成が可能になっている。
また、テキスト、和音、メロディなどの入力を低次元の特徴量に変換し、それらを単純に結合するのではなく、相互作用を考慮して統合するという独自の手法も取り入れられている。
さらに、与えられた条件(例:リズムパターン)と生成される音楽の時間的な一貫性にも特別な工夫がなされている。これらの多面的な制御能力が、JASCOの特徴となっている。
混合モダリティモデル「Chameleon」も発表
メタは2023年にも「MusicGen」という音楽生成AIモデルを発表している。こちらはテキストからの音楽生成に特化しており、高品質な音楽生成が可能だが、JASCOほど細かい制御はできない。
また、グーグルも「MusicLM」を開発しており、テキストと音声の両方から音楽を生成できるうえ長時間の音楽生成が得意となっている。
JASCOやMusicLMといった高性能AIの登場により、AIはアーティストの創造的なパートナーとして活用されていく可能性がある。今後は、音の強弱や曲の構造などのより複雑な要素の制御、特定の楽器音の追加や変更などの機能の開発が期待されている。
なお、JASCOを開発したメタの基礎AI研究(FAIR)チームはJASCOの発表と同時期に、他のいくつかのAIモデルも公開している。
その中でも特に注目されているのが、画像と文章の両方を理解して生成できる混合モダリティモデル「Chameleon」だ。
また、言語モデルの学習効率を大幅に向上させる新技術「マルチトークン予測」や、AI生成音声を高速で検出する音声透かし技術「AudioSeal」なども発表されている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















