Amazon DataZoneが解決するデータ分析基盤の課題とは?
データ分析のアジリティとガバナンスの課題 CDataとAWSでとことん語ってみた
提供: CData Software Japan

CData Software Japan リードエンジニアである杉本和也氏と、アマゾン ウェブ サービス(AWS)のソリューションアーキテクトでデータ分析を専門とする大薗純平氏の対談。前半はCData SoftwareとAWSとの連携がテーマだったが、後半はガバナンスとアジリティの両立、そしてDataZoneを中心としたAWSのソリューションとCDataとの組み合わせなどを思う存分語ってもらった。

品質、分散、信頼性などデータ分析にまつわる課題は山積み
大谷:後半はデータを溜めるだけではなく、分析するための基盤作りがテーマです。まず杉本さんからデータ分析にまつわる課題について教えてもらえますか?
杉本:Amazon QuickSight、PowerBIやTabelauなどのBIツールを使って、現場自らデータ分析をしようといういわゆる「市民開発者」にあたる人は増えています。これ自体は「データの民主化」という流れなので素晴らしいのですが、個人的にはBIツールのベンダーさんから整形されたデータベースのデータを使っている方はごく一部。ほとんどの方はローカルのCSVファイルやExcelを使っている」と聞いて、けっこうびっくりしています。

CData Software Japan リードエンジニア 杉本和也氏
大谷:どこらへんが問題点なのでしょうか?
杉本:品質の問題が発生すると思っています。
本来、ビッグデータって、ボリュームだけではなく、品質や更新頻度なども要件になっています。でも、あるお客さまは情報システム部に依頼して、売上をCSVファイルとしてもらうには、最短でも3日、通常は1週間かかるとお話されていました。リアルタイムのデータでないと、当然タイムラグが生じるので、現状との乖離が起こります。品質と更新頻度の要件を満たせないわけです。
これだと経営が要求する更新頻度スピードを満たせないし、ダッシュボードを作っても、現場に信用してもらえません。
大谷:大薗さんはいかがですか?
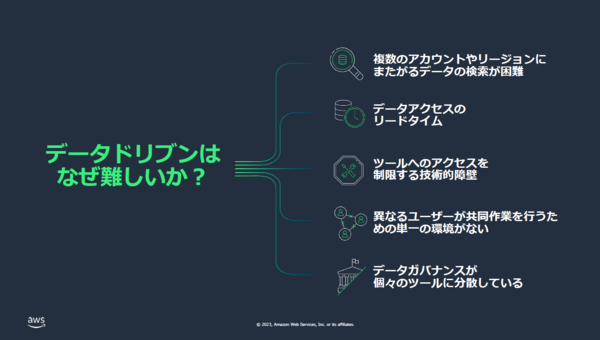
大薗:データドリブン経営に至るまでは、さまざまな課題があります。
まずデータが分散しているということです。必要なデータがどこにあるかわからないし、見つけてもアクセスできないし、アクセスしようにも誰に聞いたらよいかわからない。アクセスできたとしても、このデータは正しいのか?という信頼性の問題があります。
データドリブンはなぜ難しいのか?
しかも、最近は1人ではなく、チームで分析するので、データを共有する必要があります。でも、コラボレーションするための環境がありません。ビジネスユーザー、データサイエンティスト、データアナリストなどのインターフェイスが別々になっているので、同じデータを見ながらコミュニケーションができないことになります。
最後にデータガバナンスの課題があります。分散しているため、ルールが統一されておらず、それぞれの事業ドメインで完結してしまっているのです。基準となるデータ自体が違うと、データを元に判断がオーソライズされないことになります。
大谷:なるほど。
大薗:また、マスターデータの問題もあります。同じ会社なのに「株式会社」と「(株)」という表記の違いで異なるデータとして登録されたり、プライバシーやコンプライアンス上、本来扱っては いけないデータを扱ってしまうということもあります。
ただ、これはどのデータをどのように扱うべきなのかの指針がないことから起因する問題です。でも、業務は動かさなければならないし、上からもやれと言われている。みんな困りながらもデータを扱っている状態です。
大谷:今までの話を聞けば、IT部門がデータを1ヶ所に集めて、ガバナンス前提でがっちり管理すればよいのでは?と思うのですが。
大薗:そうすると、今度はそこがボトルネックとなり、アジリティ(柔軟性)を失います。
そもそも、IT部門が全事業ドメインのデータを整理し、管理していくのは容易なことではありません。事業ドメインに関する知識では事業部門を超えることは難しいですし、全事業のすべてのニーズに応えてデータパイプラインを開発・運用していくのも大変です。全社データのアクセスポリシーを定義していくのも困難ですし、それゆえデータ利用者側からしてもどのデータをどのように活用できるか、判断するのが難しい。ガバナンスがないために、データ管理する側も、利用する側も、それぞれ課題を抱えているのが現状だと思います。

アマゾン ウェブ サービス ジャパン アナリティクス ソリューションアーキテクト 大薗純平氏
大谷:統合するとアジリティを失い、分散するとガバナンスが欠けてしまうというわけですね。
大薗:本来はデータを使ってイノベーションを起こし、経営に活かしたいはずなんです。ガバナンスを効かせすぎると、柔軟性がなくなります。だから、Excelを使って各部門でデータ分析し始めるのですが、こうなると無法地帯になってしまいます。
ただ、これは二者択一なわけではなく、ガバナンスも、アジリティも、両方大事ですよねというのが、われわれのメッセージです。これを実現するのはもちろん簡単ではないのですが、一つのソリューションとして提供するのがAmazon DataZoneになります。

アジリティとガバナンスの両立を目指すAmazon DataZone
データプロデューサーとデータコンシューマーを仲介するAmazon DataZoneの役割
大谷:こうした課題を踏まえてAmazon DataZoneがなにを解決してくれるのかを教えてください。
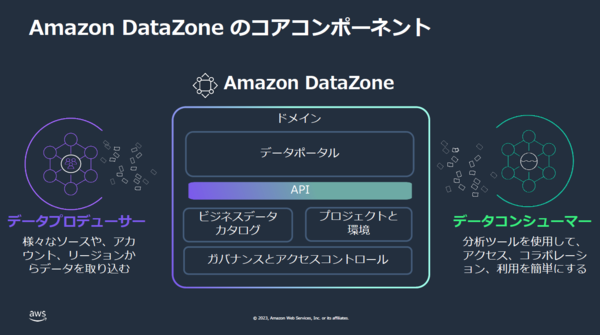
大薗:データ分析の関係者を分類すると、さまざまなソースやアカウント、リージョンからデータを取り込むデータプロデューサーと、データにアクセスして、コラボレーションしながら、分析を行なうデータコンシューマーがいます。
杉本:たとえばデータプロデューサーはWebサイトを管理していて、アナリティクスや問い合わせ系のデータを管理している方々。その一方で、CMOやマーケティング担当者はデータコンシューマーとして、それらのWebデータとCRM系データ、バックエンドのERPのデータなどにアクセスしたいと考えている方々ですかね。
大薗:まさにそうですね。データプロデューサーは、実際にデータの分析を行なうデータコンシューマーが利用しやすい形にデータを取り込む必要があります。
DataZoneのコアコンポーネント
その点、DataZoneは両者を仲介する役割を持っており、既存のデータウェアハウス(DWH)やデータレイクなどにビジネスカタログと検索ポータルを付加してくれます。これにより、ユーザーはセルフサービスでデータの登録を行ない、必要なデータを発見し、活用しやすくします。データへのアクセスを管理し、単一のビューでデータを見つけることができます。
イノベーションのきっかけって、いろいろなデータを掛け合わせて見てみることから始まることもあると思うんです。でも、今までは、そもそもデータがあるのか、どこにあるのか、あったとしてもどんなデータかすらわからなかったんです。DataZoneを使うことで、自分たちの持っているデータと、持っていないデータを掛け合わせることが可能になります。
大谷:なぜメタデータが必要なんでしょうか? データコンシューマーは「どんなデータかわからない」とおっしゃいましたが、やっぱりわからないんですかね。
杉本:たとえば、SAPには「BNKA」というテーブルがありますが、なんだと思います?
大谷:アイドルグループみたいですが(笑)、わからないです。
杉本:BANK MASTERというテーブルです。でも、BNKAと言われてもビジネスの方はわからない。日本の基幹システムだと「KKM」というテーブルがあって、これって「勘定科目マスター」なんです(笑)。
大谷:なるほど。これだけじゃ、現場の人はお手上げですね。
杉本:この場合は、現場の人たちが使いやすいようにメタデータを付与してあげることが必要になります。ただ、メタデータの登録って、データ分析の本質ではない。分析のためにあったらうれしい記述ですが、項目も追加しなければならないし、更新もされてしまう。
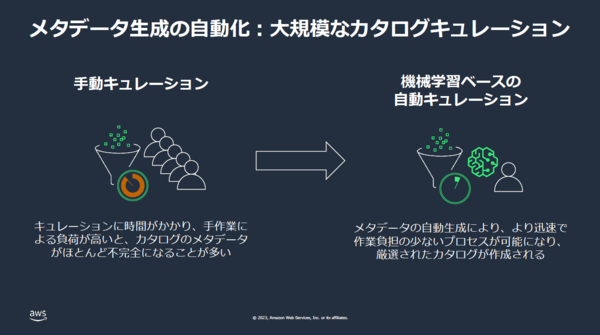
大薗:確かに「●●テーブル」「カラムA」のようなIT 部門しかわからない名前のファイルがいっぱい集まっても意味がありません。だけど、メタデータを人手で登録するインセンティブがないんですよね。人手でも可能ですが、すごく負荷がかかります。
杉本:世の中にデータカタログ系の製品は数多く存在します。データカタログを見て、自分たちがアクセスしたいデータ、所有データはどれかを確認したいというニーズもあります。ただ、データカタログのメンテナンスって、めちゃくちゃ面倒くさい作業なんです。これをセルフサービス化、自動化してくれるDataZoneはすごく便利です 。
大薗:DataZoneでは、テーブル名や列名などのメタデータを生成AIが読み込んで、自動的にラベル付けをしてくれます。予測したラベルはあとから編集もできます。また 、このデータがどのような内容なのかのサマリやユースケースを記述してくれます。そのデータに慣れ親しんでない方でも、サマリやユースケースを見れば、見当がつくはずです。
大谷:それはすごい。生成AIならではですね。
メタデータを生成AIは組み込んでラベル付け
データのアクセス管理まで実現 アジリティとガバナンスを両立
大薗:また、DataZoneは特定のグループに対して、まとめてデータのアクセス権を付与することができます。これにより、「担当者同士がメールで勝手にExcelファイルを送る」といったようなガバナンスの効いてない状態を回避できます。データにまつわるワークフローまで含めて、きっちり管理が完結するというのが、DataZoneのよさなんです。
杉本:自分もDataZoneを触らせてもらいましたが、カタログでデータを見つけて、アクセス権までリクエストできるというのがすごくいいんです。アクセス管理まで1つのプラットフォームで完結するというのが一番のポイントだと思っています。加えて、自社のデータ分析の環境をアーキテクチャのテンプレートとして保存できるBlueprintの機能も気に入っています。
大谷:これはDataZoneにデータを収集し、新しいデータベースを構築するというイメージなのですか?
大薗:実際は仮想的に収集しています。だから、データコンシューマーはDataZoneのインターフェイスを介することで、分散したデータの物理的な位置を意識せずに、データにアクセスできます。リッチなメタデータが付与されたビジネスカタログを見れば、自分の業務に活かせそうなデータを見つけることが可能になるわけです。
大谷:なるほど。だからガバナンスとアジリティを両立できるわけですね。
杉本:CDataのプロダクトは、DataZoneと直接連携するわけではなく、Amazon S3やAmazon RedshiftなどのAWSのデータ分析基盤と連携します。ただ、CDataのプロダクト自体もAWS上で動作します。だから、データ分析基盤で必要な収集から管理、分析までをAWS上ですべて完結させることも可能です。
大薗:データ分析基盤にデータを格納し、その情報をDataZoneに登録すると、 DataZoneが先ほど話したAIによるメタデータの付与やアクセス権の管理を実現してくれるわけです。
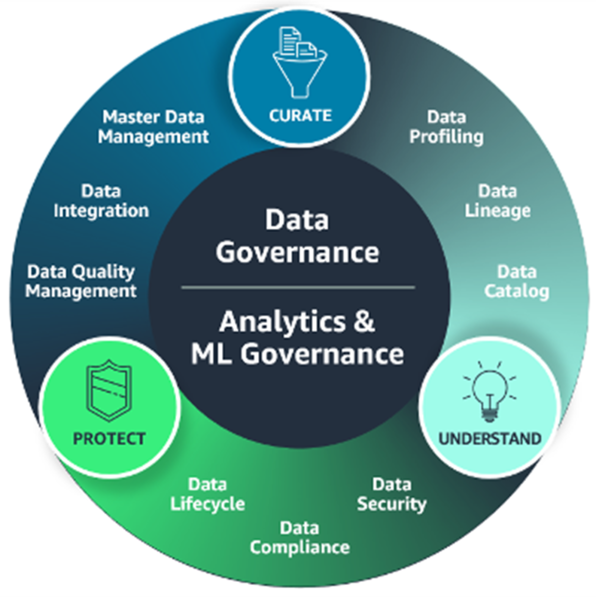
AWSではデータガバナンスの重要な3つの柱を以下のように捉えています。
1.CURATE(データ統合や品質管理などデータのキュレーション)
2.UNDERSTAND(データカタログ管理やプロファイリングなどデータの理解)
3.PROTECT(データセキュリティ管理やコンプライアンスなどデータの保護)
データガバナンスの3つの柱
Amazon DataZone では主に2のデータの理解と3のデータの保護をカバーしています。CData は1のデータのキュレーションの一部を果たしてくれると思います。
鍵はメタデータ 正しいデータにアクセスできる環境を維持できる仕組みこそガバナンス
大谷:最後、大薗さんから読者に対してデータガバナンスに関するメッセージをお願いします。
大薗:ガバナンスは、データの漏えいや誤用を防ぐためのまもりの施策と見られることもあります。だから、CData Syncのようなツールでいろいろなところからデータを集めてくるのは危険と思われがちです。確かに昔はそういうこともあったかもしれませんが、今や正しい人が正しいデータにアクセスできる環境を維持し続ける仕組みこそがガバナンスなんです。

一般的にはアジリティとガバナンスは、トレードオフの関係として見られがち。でも、ガバナンスを整えると、アジリティも上がることをお客さまにはお伝えしたい。CDataを用いて、データを持ってきていただければ、AWSはアジリティとガバナンスを両立できる仕組みを提供できます。
大谷:杉本さんにはCDataとAWSで実現するデータ分析基盤の価値を教えてください。
杉本:生成AIの利用を前提として、今回のようにAmazon DataZoneにデータを集める一つのモチベーションは、カタログにも関わってくるメタデータだと思っています。生成AIで正しい判断や結果を得たいのであれば、これからはビジネスデータのコンテキストが自分たちのプラットフォームにどれだけ集約できているかが鍵になると思っています。
たとえば、先述したSAPのデータ項目が単なる記号になっているのか、もしくはビジネスのドメインを含めたコンテキストが含まれているのかで、生成AIで分析したときの回答の精度が違ってくるはずです。これは前述したようにDataZoneのメタデータ付与機能が大きな役割を果たしてくれるのですが、CData SyncがAPIで取得したデータを使いやすい形にモデリングし直してくれるというのも大きいんです。人を前提としたデータカタログとしても、生成AIを前提としたデータにしても、最適化した状態でAWSプラットフォームで利活用できる。これがCDataとAWSが組み合わせた価値だと考えています。
本記事はアフィリエイトプログラムによる収益を得ている場合があります