



アップルのAI、「Apple Intelligence」がiPhoneやMacを変える! 「WWDC24」特集 第16回
アップルのAIがすごいところを技術的に見る。速度と正確性の両立がポイント
2024年06月12日 16時30分更新

様々な最適化手法で高性能かつ高速化
Apple Intelligenceは高性能と高速化を両立するため様々な最適化処理が施されている。
大量のテキストデータ処理を効率化するためには「グループ化クエリによる注意機構(grouped-query-attention)」という技術が使われている。
さらに、単語を数値に変換する際に使用する「語彙埋め込みテーブル」を共有することで、必要なメモリと処理時間を削減している。
具体的にはデバイスモデルは4万9000語、サーバーモデルはそこにより多くの言語や専門用語を加えた10万語の語彙テーブルを持つ。
また、モデルのパラメータを少ないビット数で表現することで、メモリ使用量と処理速度を改善する「低ビット量子化」、モデルに追加学習させることで精度を維持しながらパラメータ数を削減する「LoRAアダプター」という技術も組み合わせて使用されている。
さらに、各操作に最適なビットレート(データ処理速度)を選択するための「Talaria」と呼ばれるツールや、「活性化関数」と「埋め込み」の量子化、そして「キーバリュー(KV)キャッシュ」の効率的な更新といった一連の最適化により、「iPhone 15 Pro」では、最初のトークンを生成するまでの待ち時間が約0.6ミリ秒に短縮され、毎秒30トークンの生成速度が達成されたという。
特筆すべきことに、このパフォーマンスはトークン推測手法(「token speculation techniques)を適用する前の水準であり、トークン推測によりさらに生成レートが向上するという。
モデルの適応は「アダプター」と呼ばれるモジュールを使用
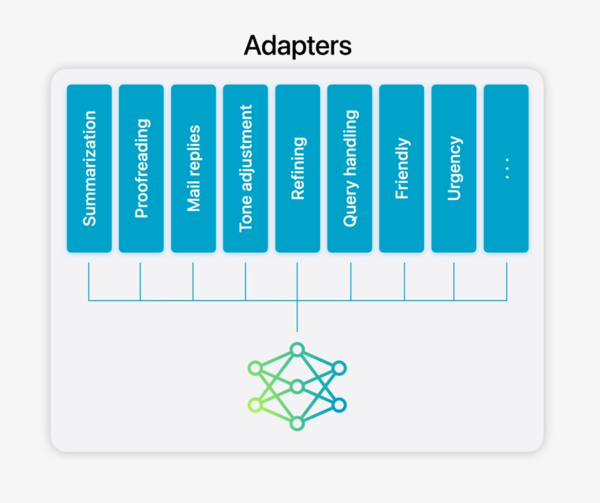
豊富なアダプターでLLMを微調整
「LoRAアダプター」についてもう少し詳しく見てみよう。
大規模言語モデル(LLM)は、膨大な数の「パラメータ」を持つことで、様々なタスクをこなせるが、すべてのタスクにすべてのパラメータが必要なわけではない。
Apple Intelligenceは「アダプター」と呼ばれる特定のタスクに特化したパラメータのセットのような小さなニューラルネットワークモジュールを使用する。
アダプターは、事前トレーニングされたモデルのさまざまな層に接続でき、タスクに応じてモデルの特定の部分(文章の理解に重要な「アテンション」や、情報を処理する「フィードフォワードネットワーク」など)を微調整する。
重要なのは、微調整はアダプター層に対してのみ適用され、元のモデルの主要な部分は変更されないということだ。これにより、モデル全体を再トレーニングするよりもはるかに高速かつ効率的にモデルを適応させることができるのだ。
また、必要なときにだけアダプターをロードすることでメモリを節約し、処理速度を向上させることもできる。Apple Intelligenceはそれぞれの機能に特化した幅広いアダプターを提供することで、カメレオンのように様々なタスクに柔軟に対応できるようになっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第22回
Apple
Apple WatchもAI! watchOS 11の新機能から「次」が見えた -
第21回
Apple
Apple Vision Pro、6月28日に日本上陸! Apple Storeで体験するなら無料だ! -
第20回
Apple
アップルは「AIスマホ」でどこまで競えるのか? 今後グーグルとの勝敗は(石川 温) -
第19回
Apple
アップルWWDCで明かされたのは「パーソナルインテリジェンス」への挑戦だった(西田宗千佳) -
第18回
Apple
アップルID、「アップルアカウント」に変更。サインイン体験あらわす表現に -
第17回
Apple
みんな「Hey Siri!」は恥ずかしかったw AirPodsの新機能は「首を振るだけ」 -
第15回
Apple
【現地レポ】アップル次期OS、注目したい3つの機能! キーワードは「整う」 -
第14回
iPhone
アップル「iOS 18」見られたくないアプリだけロックできる新機能 -
第12回
iPhone
アップル「iOS 18」支払い機能が便利! 分割払いの指定や、iPhoneで割り勘も -
第11回
iPhone
iPhone版「消しゴムマジック」精度高そう! iOS 18新機能「クリーンアップ」 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















