




「ウェブページ」を食わせる
以前はテキストファイルやPDFしか扱えなかったが、今回の改良でウェブサイトのURLを入力するだけでそのページの内容をクロールしてくれるようになったので、ネット上の気になるニュースや記事を片っ端から読み込ませて情報ソースにするという使い方もできるだろう。
ただし読み込むのは単独ページのみで階層ごと一気に読み込みというのは現時点ではできなさそうだ。
ここではOpenAIの画像生成AI「Sora」についてウェブサイトから情報を集めてみることにする。OpenAIのSoraに関するページを3ページ、そしてWikipedia(英語版)のSoraのページも読み込ませてみた。
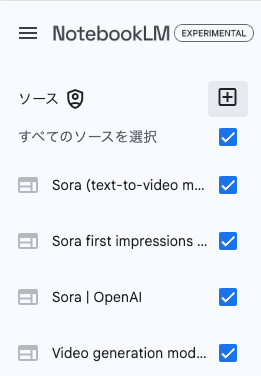
読み込ませた情報ソースは左側に表示される。チェックボックスで参照するソースを選択することも可能だ。
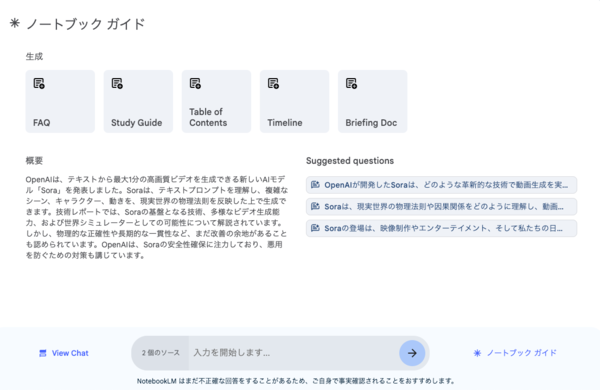
資料を読み込ませるたびにノートブックガイドは自動的に生成される。
特に英語のテキストの場合、参照元を表示してくれる機能が非常に役立つ。
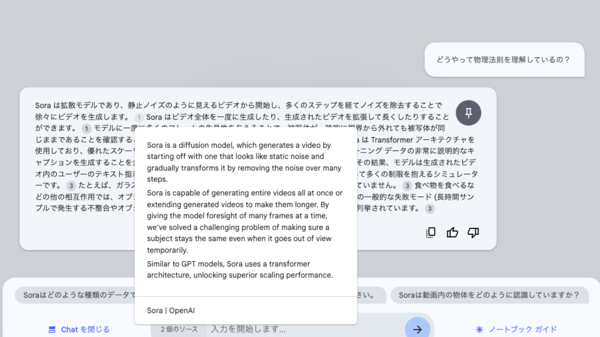
「これらの情報を元にニュース記事を書いて」といった横着な使い方もできる。社内の報告書などインターナルな利用であればまったく問題ないだろう。
筆者はプロのライターなのでAIが書いた記事をそのまま貼り付けて使うといったことはないが、部分的に取り入れたり自分が書いた文章とマージしてもらったりと毎日ヘビーに活用している。

本記事はアフィリエイトプログラムによる収益を得ている場合があります































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


















