CDataサイト開設記念インタビュー第一弾
複雑なデータアクセスの課題 シンプルに解決するCDataの存在意義
提供: CData Software Japan

データコネクティビティを提供するCData Softwareの特設サイトがいよいよオープンした。オープンを記念して、CData Software Japan代表社員の疋田圭介氏にロングインタビュー。初回はCDataが挑むデータアクセスの課題について深掘りする。(以下、敬称略 インタビュアー ASCII編集部 大谷イビサ)

CData Software Japan代表社員 疋田圭介氏
APIも、認証も、データ形式もバラバラ クラウド時代のデータアクセス
―――AIの利用が拡大し、ますますデータの利活用が叫ばれています。こうした中、CDataはどういった課題に向き合っているのか、市場や技術動向の分析からお願いします。
疋田:業務アプリケーションは使えば使うほどデータが溜まっていきます。その中で、データ連携というと、通常は業務データ処理の自動化か、分析用のデータパイプラインの2種類を指します。
自動化に関しては、労働力不足やクリエイティビティな作業への集中という点で理解してもらえますし、データドリブンな意思決定のためのデータ分析も必要性が認知されてきました。だから、業務アプリケーションからデータを取得し、自動化や分析に活用する「データアクセス」のプロセスが重要です。
―――実際にどのようなことをやっているのですか?
疋田:データアクセスは、利用するアプリケーションからリクエストを投げ、認証を通って、必要なデータを取得するためにクエリ(SQL)を投げるというプロセスになります。
昔はODBCやJDBCなどの汎用データアクセス規格があったので、SQLだけ使えれば、あとはプロトコルを意識する必要がありませんでした。データベースも基本はリレーショナルDBなので、SQLを使えばデータといっしょにメタデータも取得できました。もちろん、認証はいくつかありましたが、クエリのやり方も、データ形式も、スタンダードが決まっていたので、困らなかったんです。
でも、今はWeb APIや認証、データ形式もさまざま。一言でAPIと言っても、各SaaS事業者が自社の戦略にあわせてAPIを実装しているため、それぞれのAPIは違う。RESTful APIは、SQLのようにかっちりと固まった規約・ルールではなく、緩いスタイルです。SalesforceのSOQLやFacebookのGraphQLと独自実装のAPIを持っているサービスも多いです。
―――認証やデータ形式もさまざまな種類がありますね。
疋田:認証もIDとパスワードだけで通るシンプルなものもあれば、OAuth 2.0 のようにトークンが何度も行き来するものもあります。JWT(ジョット、JSON Web Token)など聞き慣れないと発音に悩むものもあります。SSO(シングルサインオン)となれば、さらに複雑になる訳です。
もちろん、スキーマ構造もリレーショナルテーブルだけではなく、キーバリュー、ドキュメントなど多種多様だし、メタデータも静的なものや動的なもの、動的・静的のミックスなど簡単ではありません。そして実際のデータアクセスには、複数テーブルのジョインやフィルタリング、ソート、グルーピングやバルク処理などの機能が必要になります。それぞれに理由があったり、APIを開発した方の好みがあるわけですが、結果としてRESTful APIと呼ばれているものは多様なバリエーションに分かれてしまっています。
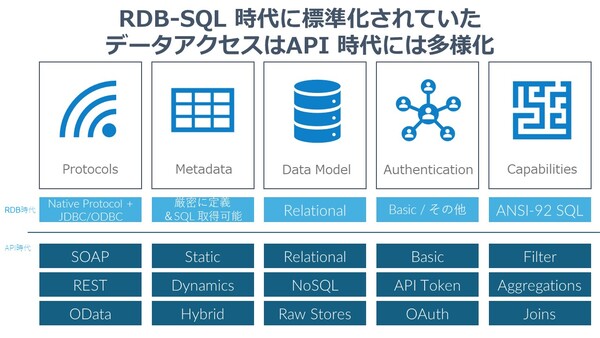
このジャンルの多様さは、ある意味ヘビーメタルと同じ。外から見たら、メロスピもデスメタルもゴシックメタルもグラインドコアもブラックメタルも同じです(笑)。とはいえ、メタラー同士が話し始めたら細かい議論になります。メタル談義では相手の人は用語やジャンルにズレがあれば文句を言いつつ丁寧に訂正してくれますが、APIはプログラミング。ざっくり同じだと思って、リクエストを出してもAPIはエラーを返すだけです。
―――確かに(笑)。そういう意味では、ITの世界ってプロトコルだったり、OSだったり、いろいろなものシンプルになっている気がしますが、データアクセスの部分だけは逆走していますね。
SQLという業界標準に乗っかるCDataビジネス
―――では、CDataはこの課題をどのように解決してくれるのでしょうか?
疋田:CDataのライブラリを使えば、いろいろなデータをSQLで取得できます。なぜSQLかというと、「どんな方法でデータが欲しいですか?」という投票があったら、SQLはダントツ一位だからです。Javaだろうが、C++だろうが、Pythonだろうが、プログラミング言語は違えど、データアクセスはSQL。民主主義だったら、SQLは40年間ずっと大統領ですよ(笑)。
―――エンジニアはもちろんですが、アプリケーションから見てもうれしいはずですね。
疋田:プログラマーさんたちだけではなく稼働しているプログラムにもそれぞれ投票権があったら、それこそSQLはぶっちぎりで1位を維持です。そこで、CDataであれば、アプリケーションからプログラマーさんもアプリケーション側も慣れ親しんだSQLを投げれば、相手先の認証を経て、Web API経由でテーブルデータとして取得できます。
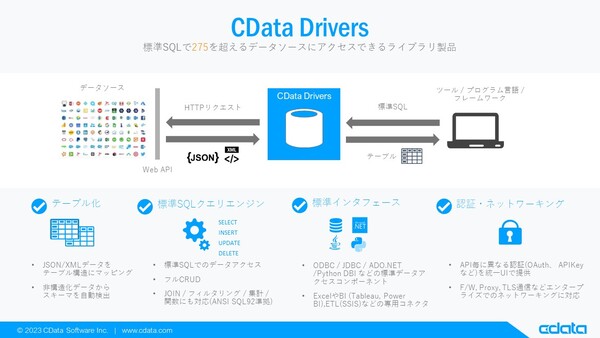
SQLでデータを取得できるCData Driver
市場では、アプリケーションからWeb APIへのデータアクセスが実装されるたびに、この「認証して、APIに合わせたデータリクエストを作って、戻ってきたJSONなどのデータをアプリで使えるテーブル状態にする」という作業をそれぞれのプロジェクトのエンジニアがコードを書いています。何万回、何十万回と似たようなデータアクセス処理を優秀で忙しいエンジニアさんたちが書いているのです。「そこ、がんばる必要ある? だったら統一化しませんか?」というのが私たちの提案です。
CDataでは、基盤となる「CData Drivers」があり、それを活用する形でクラウド提供の「CData Cloud Connect」、データベースのAPIを作成する「CData API Server」、データパイプライン処理を自動化する「CData Sync」、SalesforceとSQL Serverの双方向データ統合を実現する「CData DBAmp」、ファイル転送・EDI・EAIなどを提供する「CData Arc」などです。
―――対応するデータソースのもすごい数ですね
疋田:当初は50くらいでしたが、今は270くらいあります。

さまざまなレイヤーに対応するCDataの製品群

データソースもすでに275種類を超える
―――本社は北米で、日本法人設立は2016年ですね。そこからの経緯を教えてください。
疋田:最初に飛びついてくれたのは、アステリアやウイングアーク1stなどデータ系のミドルウェアを提供するツールベンダーです。すでにAPIに連携するコネクタ実装を複数行なっており、APIごとの違いや仕様変更への追従の大変さが良く分かっていらっしゃるベンダーですので、いち早くCDataの価値を見抜き、CData 製品を自社の製品に組み込むOEM契約をしてくれました。

国内トップベンダーがOEMパートナーに
次に導入してくれたのが、「このツールからこのSaaS につなぐ」という顕著化したニーズを持っているユーザー企業です。たとえばPowerBIからkintoneのデータを使いたいというユーザーは、多機能で大きなツールより、単機能の弊社のコネクターを選択してくれています。こうしてどんどんユーザーが増え、累計では3500ライセンスくらい。OEMパートナーも20社を超えています。企業が利用するSaaS種類がどんどん増えていく中でデータコネクタはビジネスとして引き続き大きな可能性があると考えています。
国産SaaS連携、ETL用途、リンクサーバー、データパイプラインなどの事例
―――こうして拡がってきた典型的なユースケースを教えてください。
疋田:基本的にはPowerBIやTableauを使ってkintone(サイボウズ)、Backlog(ヌーラボ)、スマレジなど国産SaaSのデータを見るというパターンが多いですね。難しい設定なしでBIツールから分析できるというこのシナリオはまさに鉄板です。外資系ツールベンダーは日本のSaaSのコネクターを用意することは稀なため、うちに白羽の矢が立ちます。
次はETLツールの用途。すでにオンプレミスのデータ分析基盤はあるけど、新しいSaaSがあるので、データ連携したいというパターン。データソースはMarketoやSalesforce PerdotなどのようなMAツール、チケット管理のJira、ワークマネジメントのAsana、ビジネスチャットのSlackやLINE WORKSなど。自らコネクターを書くのではなく、CDataを使えばデータを利用するまでが圧倒的に早いです。

kintoneからPowerBIの利用

ETLやデータ連携ツールの追加コネクター
―――ここらへんはわりと業務現場のユーザーの用途ですね。情報システム部前提のユースケースはありますか?
疋田:根強い人気のシナリオはSQLサーバーのリンクサーバー用途です。今までSQLサーバーをバックエンドのデータベースとしてオンプレの基幹システムを構築してきた企業が、Salesforceのような別のクラウドに顧客データを移行してしまった場合、開発から見て一番楽なのは、SQLサーバーに今まで通りアクセスすれば、バックエンドでSalesforceデータを処理してくれるというやり方。これを実現してくれるのがリンクサーバーです。オンプレミスのカスタムアプリケーション用途で、クラウドのデータを持ってきたい場合によく使われます。
ここ数年でニーズが大きくなっているのがデータパイプラインです。カスタマーサクセス分野で、どんぴしゃなタイミングで、どんぴしゃな施策を打つためには、リアルタイムに顧客のデジタルタッチポイントのデータを収集し、分析できる基盤が必要になります。そのためにオンプレミスのOracle DBやSQLサーバーから顧客データを取得しつつ、SalesforceやZendesk、Jiraなどのクラウドデータ、Webの各種データなどを、BigQueryやSnowflakeに流し込んでがっちゃんこ(統合)するわけです。

SQLサーバーのリンクサーバー用途

データパイプラインとしての利用
―――いろいろなデータ連携ができるんですね。
疋田:はい。ただ、うちはデータ連携のベンダーですが、データにアクセスすること自体には価値ないと思っています。データを持ってくることで、自動化が実現できるとか、分析によって意思決定ができる方が大事です。
―――ユーザーは本来やるべき価値創造にフォーカスしてくれと。
疋田:われわれが使いやすいコネクターを提供することによって、データ連携の手間を最小化して、本来やるべき自動化やデータ分析に注力しましょうというのが重要なメッセージです。「価値を生み出す前の価値のない作業を楽にする」というのが、CDataの存在意義です。
(つづく)
この記事の編集者は以下の記事もオススメしています
-
デジタル
ThoughtSpotからSalesforceへのダイレクト接続をCData Connect Cloudで実現 -
デジタル
データパイプラインとETLパイプラインの違いとは?それぞれの特徴から選定のポイントまで解説 -
デジタル
GmailデータをExcelに取り込む方法|Gmail APIの使い方 -
デジタル
kintoneとStripeをノーコードで連携!kintoneの製品マスタを自動でStripeに移行してみる -
デジタル
Smartsheet APIにOAuth認証でつないでPostmanからデータ取得する方法 -
デジタル
Salesforceへの書き戻し機能搭載!CData Sync v23.4でReverseETLが実現 -
sponsored
IT企業は東京じゃないとダメ? CDataの日本法人があえて本社を仙台に置く理由 -
デジタル
SAP Aribaの注文書や請求書データを取得・分析する方法 -
デジタル
CData Arc -(サポートを利用するときに役立つ)設定やログの取得方法 -
sponsored
脱CSV・Excel! CData+AWSが実現するデータ分析基盤の価値 -
sponsored
データ分析のアジリティとガバナンスの課題 CDataとAWSでとことん語ってみた -
デジタル
イベント管理SaaSとBIがノーコードで連携できると、参加者動向がガッツリ分析できて便利 -
デジタル
Google Cloud、CDataのコネクタで外部データソースとの連携強化 -
Team Leaders
“API公開率が2割未満”の国内SaaSを変える 生成AIでAPI実装を60分にまで短縮