




リファレンスクロックがないため
REQ/ACKを利用したハンドシェイクで非同期通信
気になるSASIの速度であるが、実は仕様には規定がない。そもそも先の信号ピンのところで説明したように、SASIにはリファレンスクロックに当たる信号がない。要するに同期式ではないわけだ。では通信はどうやって行なったか? というと、REQ/ACKを利用したハンドシェイクである。下の画像がそのタイミングチャートであるが、デバイスからの読み込みなら以下の手順になる。
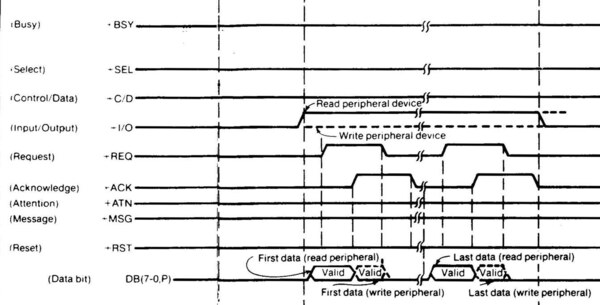
本当はこのチャートは2ページぶち抜きでさまざまなシーケンスが示されているのだが、ここではDataのRead/Writeのみを抜粋した
(1) デバイスがREQをAssertする(0→1にする)
(2) この段階でDB0~DB7にはデバイスからのデータが載るので、ホストはこのデータを読み込む
(3) データを読み込み終わったホストはACKをAssertする(0→1にする)。このタイミングでDB0~DB7の信号は有効だが意味がなくなる
(4) REQ/ACKの両方がAssertされたら、デバイスがREQをNegateする(1→0にする)。この段階でDB0~DB7の信号は無効になる
(5) ホストがACKをNegateする(1→0)。これで1回の転送が終わる
同様にデバイスへの書き込みは以下のとおり。
(1) デバイスがREQをAssertする(0→1にする)
(2) ホストはACKをAssertする(0→1にする)
(3) この段階でDB0~DB7にはホストからのデータが載るので、デバイスはこのデータを読み込む
(4) デバイスはデータを読み込み終わったら、REQをNegateする(1→0にする)。この段階でDB0~DB7の信号は無効になる
(5) ホストがACKをNegateする(1→0)。これで1回の転送が終わる
要するにホストとデバイスの両方が、どれだけ高速にハンドシェイクするかで転送速度が決まるわけだ。実はこの仕組み、のちのSCSIにもほぼそのまま継承されたのだが、SCSI-1が公称5MB/秒、実効でも1~2MB/秒の転送速度が確保できた(なにをつなぐか次第ではあったが)のに対し、SASIはそこまで速度が出なかったように記憶している。おそらく1MB/秒未満だっただろう。
ちなみにSASI自身は、純粋にホストとデバイスの間でメッセージやデータを交換するI/Fの規定であって、その上でどんなデータを流すかといったことには一切関与していない。これは続くSCSIも同じではあるのだが、本来ならもっと汎用に利用されても不思議ではなかった。
ただそこまで普及しなかったのは、より優れた上位規格としてSCSIが登場し、これが市場を席捲してしまったためだろう。またFDDに関しては、IBM-PCの頃から本体内蔵が一般的になってしまったことにより、拡張バスにFDDのコントローラーを搭載、そこから直接FDDのI/F(34ピンのやつだ)にフラットケーブルなどで接続することになり、SASIを使う必要性がなくなった。
米国では1983年発売のIBM-PC/XTこそSASIだったが、1984年発売のIBM-PC/ATはIDEに移行。1984年発売のMacintosh 128Kは外部FDD接続用に独自I/Fを採用した(内蔵HDDはなし)が、1986年のMacintosh Plusでは外部接続用にSCSIポートを搭載した。
こんな経緯もあってか海外では1990年を待たずにSASIはほとんど消えてしまっており、たまにSASIが必要な場合に向けてSASI/SCSIのコンバーター(SCSI HDDをSASI I/Fに接続できるようにするもの)が使われたりしたほどだ。消えるのが妥当なI/Fだった、としていいだろう。
※お断り:記事初出時、PC-9801シリーズのFDDがSASI接続だった旨を記述しておりましたが、これは筆者の記憶違いによる誤りである模様です。当該箇所を削除しお詫びします。(2024年3月21日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























