





東京大学松尾研究室発のAIベンチャー「ELYZA」は3月13日、700億パラメーターの最新日本語大規模言語モデル(LLM)「ELYZA-japanese-Llama-2-70b」を発表した。
100Bトークンの日本語コーパスで追加事前学習
「ELYZA」デモサイト
同モデルは英語の言語能力に優れたメタのLLM「Llama 2」シリーズに日本語能力を拡張するプロジェクトの一環で得られた成果物だ。
具体的にはLlama 2に対し、日本語による追加事前学習と事後学習を実施。追加事前学習には約100Bトークンの日本語コーパスを用い、事後学習には「日本語での指示追従能力と一般的な知識を向上させることを目的としてELYZAが独自に構築した高品質なデータセット」を用いているという。
モデルの学習には「GPT-4」や「GPT-3.5 Turbo」など、規約において出力を他モデルの学習に利用することが禁止されているモデルの出力は一切含まれていないという。
なお、これまでのようなオープンソースでの公開ではなく、同モデルを含むELYZAの日本語LLM群を「ELYZA LLM for JP」シリーズとし、2024年春以降API提供という形で(恐らく)有償公開ということになるだろう。
日本語LLMでは最高峰の性能

Tasks 100による人手評価(国内モデルとの比較)
LLMの指示に従う能力や、ユーザーの役に立つ回答を返す能力を測ることを目的とした日本語ベンチマーク「Tasks 100」による評価では、同じくメタの「Llama 2 70B」をベースとする他の日本語 LLM国内モデルの中で1位となっている。
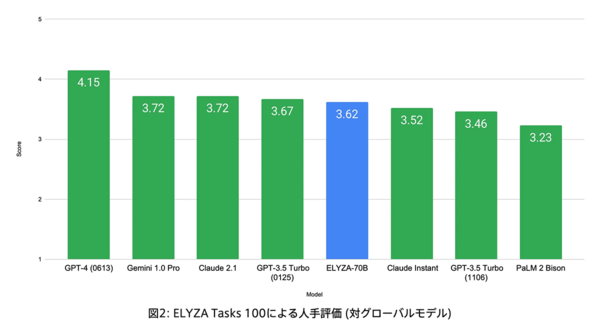
Tasks 100による人手評価(グローバルモデルとの比較)
さらに、「Claude Instant」や「GPT-3.5 Turbo (1106)」といった海外のモデルを上回り、その他のグローバルモデルとも遜色ないスコアを獲得した。
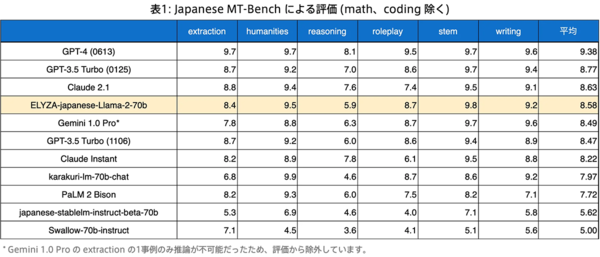
Japanese MT-Benchによる性能評価
Stability AIが提供するLLMの対話性能を測るためのベンチマーク「MT-Bench」を日本語訳して作られた「Japanese MT-Bench」による性能評価では、グーグルの「Gemini 1.0 Pro」や「GPT-3.5 Turbo」を総合スコア(平均)で上回っているほか、「stem」など一部のカテゴリーでは「GPT-4」を上回る数値さえ見せている。
ELYZAは今後も日本語LLMの研究開発を進め、より高性能な日本語LLMの実現に向けて投資を続けていくという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















