



生成AIをさらに掘り下げたAWS re:Invent 2023の基調講演
マルチモーダル、ベクトル検索、リスキリング AWSが生成AI開発支援をより強化
2023年12月18日 10時30分更新

AWS re:Inventの3日目、前日のアダム・セレプスキーCEOの基調講演で多くの時間が割かれた生成AIについて、さらに深掘りするのがAWS バイス・プレジデントのスワミ・シバスブラマニアン(Swami Sivasubramanian)氏だ。同氏は、生成AI開発を支援する基盤モデルやベクトル検索の拡充について紹介しつつ、ユーザーデータと生成AI、そして人間との協調がイノベーションや新しい体験を生むとアピールした。

AWS バイス・プレジデントのスワミ・シバスブラマニアン氏
サードパーティの基盤モデルを追加 Amazon Titanはマルチモーダルへ
登壇したシバスブラマニアン氏は、生成AIアプリケーションの要諦として、「さまざまな基盤モデルへのアクセス」「ユーザーデータを扱うプライベートな環境」「容易に扱えるアプリケーション開発ツール」「目的に特化した機械学習のインフラ」の4つを挙げる。その上で、他のクラウド事業者と比べても、機械学習のワークロードがもっとも動いているのがAWSとアピールし、現在提供している3層の生成AIのサービススタックを紹介する。
シバスブラマニアン氏が最初に発表したのは、LLMを含む幅広い基盤モデルへのアクセスを提供するAmazon Bedrockでサポートされる新モデル。一般利用が開始されたのは、Anthropic Claude 2.1とMeta Llama 2 70B、Stability AIのStable Diffuion XL 1.0などだ。
サードパーティの基盤モデルを追加しつつ、独自基盤モデルである「Amazon Titan」ももちろん強化する。シバスブラマニアン氏は、20年に渡るAmazonでのAIのノウハウと知識を組み込んだAmazon Titanの新機能について紹介した。
たとえば、Amazon.comにおいて製品のリコメンデーションを行なう場合は、埋め込みベクトル(Vector Embedding)を用いることで、検索の体験を高めている。ここでいうベクトルとは言葉と言葉の関係性を表すもので、ベクトルを使うことで、文脈を機械が理解できる数字に変換することができる。

自然言語と埋め込みベクトル
テキストに関しては、Amazon Titan Text Embeddingを提供しているが、今回は文字だけでなく、画像も組み込める「Amazon Titan model mulutimodal Embeddings」を発表した。「より豊富なマルチモーダルな検索を利用できる」とシバスブラマニアン氏はアピールする。
また、テキスト処理のためには、8000トークンのコンテキストウィンドウに対応した「Amazon Titan Text Express」が利用可能になった。英語に最適化された会話やチャットなどを前提としているが、100以上の多言語対応もプレビューで公開された。また、Titan Textファミリーの中でもっとも高速な「Amazon Titan Text Lite」は、4000トークンに対応するという。
さらに自然言語からプロ並みの画像を生成できる「Amazon Titan Image Generator」もプレビューとなった。独自データを用いることで、ブランドにあったカスタマイズされたイメージも生成できる。さらに「責任あるAI」をコミットメントにのっとり、Titanで生成した画像はすべて「ウォーターマーク(透かし)」が入るようになっているという。シバスブラマニアン氏は、イグアナの色や背景を変えたり、イグアナ自体の方向を変えたりといった操作を編集ツールから行ない、聴衆を驚かせた。
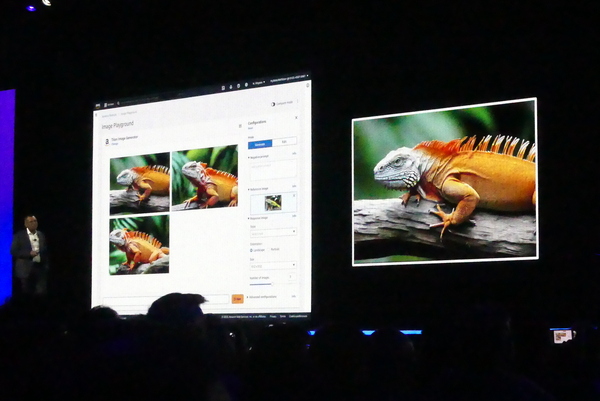
Amazon Titan Image Generatorによる画像編集のデモ
シバスブラマニアン氏はAmazon Bedrockについて、「最高のモデルを柔軟に選択できる。ニーズが変わって適用できる。短い時間でお客さまの体験を改善できる」とメリットをアピールする。今年初めにBedrockを発表して以来、ユーザーはすでに1万社を超えており、SAP Concurは出張依頼の提出に、ジョージアパシフィックは工場データの運用に、ユナイテッド航空は自然言語を用いた運航状況の問い合わせに活用されているという。
ユーザーデータこそがAI開発の差別化要因
続いてシバスブラマニアン氏がアピールしたのは、AI開発においては、企業や組織が保有しているデータが大きな差別化ポイントになるという点だ。
まず紹介したのは、ユーザーによる生成AIサービスの設計や立ち上げを支援する生成AIイノベーションセンターだ。長年に渡るAmazonのAI開発の知識やノウハウ、Amazonの機械学習分野のエキスパート(データサイエンティスト、エンジニア、ソリューションアーキテクト)がユーザーと連携し、生成AIの価値を活かした顧客向けのソリューション開発を加速する。また、Anthropic Claudeのモデルを用いて、エキスパートがファインチューニングなどを施すカスタムモデルプログラムも発表された。
さらに大規模な分散トレーニングを効率化するための専用インフラとして発表されたのが「Amazon SageMaker HyperPod」になる。昨今、基盤モデルの大規模化により、トレーニング時間は飛躍的に伸びており、TrainiumやGPUのようなカスタムチップを用いた分散環境でも、学習に数週間から数ヶ月かかる場合も増えている。
これに対してSageMaker HyperPodでは分散トレーニング用のライブラリを提供し、ワークロードを自動分割。チェックポイントを自動保存し、ハードウェア障害等で処理が中断しても、最後のチェックポイントからトレーニングを自動再開するという。「学習モデルのトレーニングを何週間、何ヶ月も短縮できる」とシバスブラマニアン氏はアピールした。

分散型の学習環境をマネージするSageMaker HyperPod
また、Amazon SageMakerも複数のアップデートが施された。まず、推論を担うSageMaker Inferenceにおいては、インスタンスに複数のモデルを収容することで平均50%のコスト削減が可能になった。また、負荷に応じたリクエストルーティングにより、平均20%のレイテンシが削減したという。
バイアスを検出し、モデルの透明性を向上するSageMaker Clarifyでは、複数の基盤モデルの比較機能が追加された。事前に用意されたプロンプトで試験を実施し、レポート形式で結果を得られる。また、ノーコード機能も強化され、自然言語の指示によるノーコードでのデータ準備も可能になるという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



