

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「Amazon Aurora Limitless Database がプレビュー開始」を再編集したものです。
Amazon Aurora Limitless Database とは
水平スケーリングを自動で行い、毎秒数百万の書き込みトランザクションの処理や1つのデータベースでペタバイトサイズのデータ管理ができるようになります。
Join the preview of Amazon Aurora Limitless Database
従来のAmazon Auroraとの具体的な違いは?
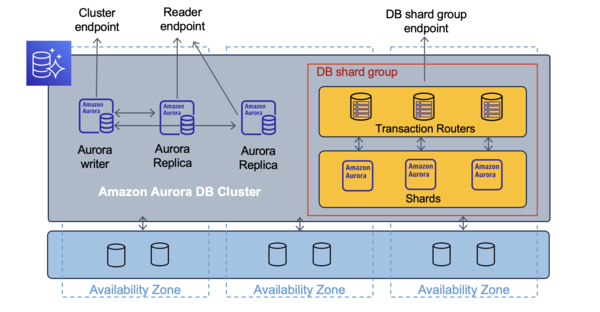
Amazon Aurora Limitless Databaseは2層のアーキテクチャを持っており、トランザクションルータとシャードと呼ばれる複数のデータベースノードで構成されています。
従来のAmazon Auroraではリードレプリカの追加により読み込み性能を向上させることは可能でしたが、書き込み性能に関してはマスターデータベースを稼働させるインスタンスの性能が上限になっていました。
Amazon Aurora Limitless Databaseでは、シャード機能により同時に複数のインスタンスに対して書き込みが行えるようになります。
トランザクションルータによって分散トランザクションを管理して、分散データベース全体での一貫性を維持することも可能となっています。
また、ワークロードが増加すると、指定した予算内で追加のコンピューティングリソースを追加してくれます。ピークに合わせたプロビジョニングは不要で、ワークロードが低い時には自動的にコンピューティングがスケールダウンするようになっています。
プレビューに関して
現在、プレビューはPostgreSQLのみに対応しており、対象のリージョンは以下の5つとなっています。
・米国東部(オハイオ)
・米国東部(バージニア北部)
・米国西部(オレゴン)
・アジアパシフィック(東京)
・ヨーロッパ(アイルランド)
久保 颯涼/FIXER
プロフ画像は猫です。誰が何と言おうと猫です。猫が好きです。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
AWS CDKでECSの環境変数を管理する際に気をつけるべきこと -
TECH
IAMユーザーのアクセスキーを使わず「IAMロール」を使うべき理由 -
TECH
Amazon BedrockからWeb上のコンテンツを参照する新機能「Web Crawler」 -
TECH
Amazon SESでEメールの送信機能/受信機能を作る手順 -
TECH
Terraform:変数の値が未代入でもインタラクティブな入力を回避する方法 -
TECH
ノーコードで生成AI連携! SlackからAmazon Bedrockのエージェントに質問 -
TECH
AWS CDKでGuardDutyのRDS保護を有効化しよう(として詰みかけた話) -
TECH
同世代エンジニアに刺激を受けた!JAWS-UG「若手エンジニア応援LT会」参加レポート -
TECH
AWS CDKとGitHubを使ったIaC=インフラ構成管理の基本 -
TECH
初心者向け:RDSスナップショットを別のAWSアカウントで復元する手順 -
TECH
CX視点で興味深かった「AWS Summit Japan 2024」のセッション - この連載の一覧へ




