FIXER Tech Blog - AI/Machine Learning
FIXER cloud.config Tech Blog
Stable-DiffusionがNVIDIAのTensorRTで高速化!? 試してみた
2023年11月14日 14時30分更新


本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「Stable-Diffusionが TensorRTで高速化!?」を再編集したものです。
はじめに
こんにちは、GPU有効活用シリーズの第2弾...ではなく1.5弾です。
第2弾のネタはあるのですが、まだ動作検証がうまくいってないのでしばらくお待ちください(今年中に出せればいいなぁ)。
ということで第1.5弾の今回は第1弾の前編で使ったStable-Diffusionによる画像生成がさらに速くなるとのことで、実際に試してみました。
概要
NVIDIA公式が提供するStable Diffusion web UIの拡張機能がTensorRTです。
生成する画像の条件に合わせてモデルを変換することで高速で生成できるようになる..らしいです。
使用するモデル、生成する画像サイズによって変換をやり直さなければいけないので色々試行錯誤するには向いてないかもしれないですね。
セットアップ
公式のサポートページにセットアップガイドがあるので、それにならって準備していきます。
まず、ドライバーのバージョンを確認します。
537.58未満だった場合は、Geforce Experienceでドライバーのアップデートしましょう。

アップデートが完了したら、docker-compose.ymlを書き換えます。
デフォルトではenvironmentのCLI_ARGSに--medvramがついているのですが、TensorRTではこれがついていると動かないようなので消しておきます。

書き換えが終わったら、Stable Diffusion web UIを起動しましょう。
前回同様、
docker compose --profile auto up -d
でコンテナを起動します。
ページが開けたら、まずは拡張機能のインストールを行います。

Extensionsタブの、Install from URLタブに移動し、1番上のURL for extension's git repositoryテキストボックスに
https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
と入力してInstallをクリックします。
完了するとTrainとSettingsの間にTensorRTというタブが出てきます。
出てこない場合は1度コンテナを停止して再起動するといいと思います。
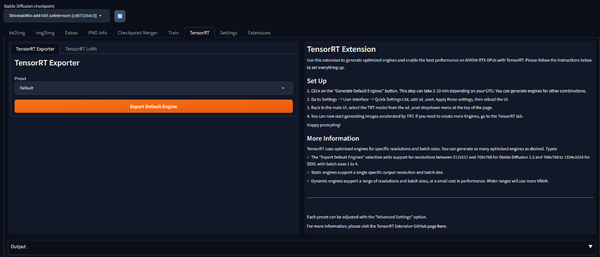
PresetがDefaultのままExport Engineをクリックします。
下部のOutputにExported Successfullyがでたら変換完了です。
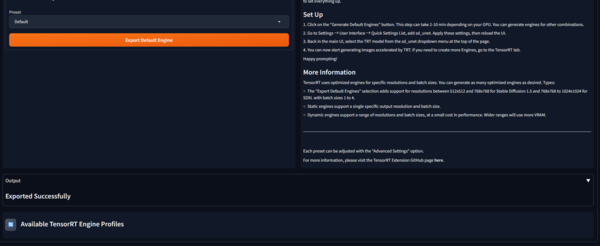
特に何も気にしない場合は、これでOKなのですが、この後第1弾とおなじ 条件で生成して時間比較するため、1024×1024も生成できるようにします。
Presetをのドロップダウンリストから1024×1024を選んでExport Engineをクリックします。
もう一度Exported Successfullyがでたら完了です。
次に、生成したEngine(SD Unet)を選べるようにします。
Settingsタブに移動し、User Interfaceにある、Quicksettings listにsd_unetを追加します。

再起動したら、モデルを選ぶリストの横にSD Unetを選ぶリストが現れます。

これで準備ができました。
ベンチマーク
第1弾と同じ条件で、何回も生成するためにapiを叩くスクリプトを用意しました。
Python
import webuiapi
from PIL.PngImagePlugin import PngImageFile
import time
# create API client
api = webuiapi.WebUIApi(sampler='DPM++ SDE Karras')
root_dir = "/output/txt2img/"
max = 30
times = []
for i in range(max):
start_time = time.time()
result1 = api.txt2img(
prompt="masterpiece, best quality, highres, hs1, 1 girls, full body,standing, bluecolored hair, hair ornament, ahoge, looking at viewer, white background, simple background",
negative_prompt="(easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)",
seed=2439170984,
styles=["anime"],
cfg_scale=7.5,
steps=40,
enable_hr=True,
hr_scale=2,
hr_upscaler="R-ESRGAN 4x+ Anime6B",
denoising_strength=0.55,
)
end_time = time.time()
times.append(end_time - start_time)
info = result1.image.info
with open(f'{root_dir}{end_time}.txt','w') as fp:
fp.write(f'Steps: {info["parameters"]}')
PngImageFile.save(result1.image,f'{root_dir}{end_time}.png')
print(times)
このコードを実行すると全く同じ条件で30枚の画像が生成されます。
実行結果は以下の通りです。

見にくいですが、おおよそ36秒という結果になりました。
続いてTensorRTで変換したSD-Unetを使って生成します。
スクリプトを少し書き換えました。
Python
enable_hr=True,
hr_scale=2,
hr_upscaler="R-ESRGAN 4x+ Anime6B",
denoising_strength=0.55,
+override_settings= {
+ "sd_unet": "[TRT] ShiratakiMix-add-VAE",
+}
)
これで再度実行してみましょう。
実行結果は以下の通りです。

こちらはおよそ30秒という結果になりました。
思ったよりも速くなりませんでしたね。
速くならなかった原因としては、
1.起動時に--xformers を付けていてすでにある程度早かった
2.リサイズにはあまり有効ではなかった
あたりが考えられるかなと思います。
最後に
満を持して?公開されたNVIDIA謹製の拡張機能TensorRTを試してみましたが、思ったよりも速くならなくて少し残念です。
また、この症状が報告されているのを見ていないのですが、この拡張機能をインストールするとコンテナをたてたときに正常に立ち上がらず、一度再起動が必要になります。
なので、個人的には積極的には使わないかなぁという感じです。
将来的にLoraにも対応するらしいので、それが動くようになったらまた試してみたいと思います。
小野 亮太朗/FIXER
23卒エンジニア。SBCでNAS、VPN、マイクラとかのサーバを建てて遊んでる人。
動的型付けよりは静的型付けが好き。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
自治体業務でどう使う? 生成AIアイデアソンに自治体職員が挑戦 -
TECH
Gemini CLIのここがすごい! Go+Vue3のアプリを作らせてみた -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 -
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) -
TECH
“GPT-10”が登場するころ、プロンプトエンジニアはどうなっているか? -
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう -
TECH
BPEの動作原理を学び、自作トークナイザーを実装してみた -
TECH
エンジニアとプロンプトエンジニアの違い、「伝える」がなぜ重要なのか -
TECH
システムエンジニア目線で見たプロンプトエンジニアリングのコツ -
TECH
学生向けの生成AI講義で人気があったプロンプト演習3つ(+α) -
TECH
ユースケースが見つけやすい! 便利な「Microsoft 365 Copilot 活用ベストプラクティス集」を入手しよう - この連載の一覧へ




