




Windowsには「Windows 音声認識」(Windows Speech Recognition、以下WSR)という機能が、Windows Vistaから標準で搭載されている。しかし、Windows 11 22H2からは英語に限り「Windows音声アクセス」(Windows Voice Access)が用意された。さらにこれとは別に、Windows 11には「Windows音声入力」(Voice Typing)という機能が導入されている。今回は、Windowsの「ボイス」関連機能を整理する。
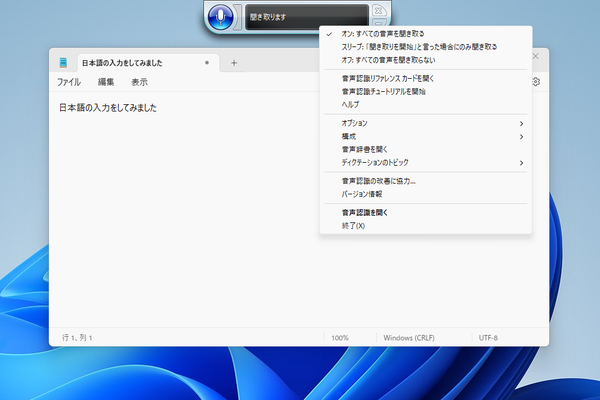
Windows VistaからWindows 10までは「Windows音声認識」が、Windowsのボイス機能として使われていた。起動すると、画面上部に音声入力状態などを示すインジケーターが表示される
そもそもボイス機能とは?
本記事では音声認識などの「音声」を「ボイス」と表記する。というのも、日本語の「音声」には、声以外の楽曲などを含んだ音全体を意味することがあるからだ(たとえば音声入力端子など)。ボイス関連機能とは、音声認識技術を使いなんらかの作業をするものだ。音声認識技術にもいろいろあるが、さらにそれを使った作業によってボイス機能は分類される。
ボイスをテキストに変換するのが「Speech to Text(STT)」だ。この逆、テキストをボイスに変換が「Text To Speech(TTS)」。STTの音声認識に対して、こちらは音声合成と呼ばれる。
もう1つは、音声でなんらかの操作をさせる「Voice Command」や「Speech Command」などだ。GUIでは、対象や機能の選択、アプリケーションの起動などをマウスなどのポインティングデバイスを用いるが、これらを含めて音声でコンピュータを操作するのがVoice Commandである。
コンピュータにおける音声認識技術では、実はこちらのほうが先に実用化されている。発声の中から適切な単語を見つけることができるなら、正確に発音を認識してテキスト化する必要がないからだ。16ビットCPU時代、メーカー製PCのオプションとして音声認識ボードなどが作られ、簡単な操作が可能だった。
Voice Commandは、単にキーやマウス操作を音声で代用するだけでなく、現在のコンピュータの状態を音声で伝える技術も必要になる。画面上のテキストを読み上げる「スクリーンリーダー」に似ているが、音声で伝えるのは画面に表示されているテキストだけでなく、現在のウィンドウでどのような操作が可能なのかなど、文字以外の情報も伝える必要がある。
基本機能として、STT、Voice Commandなどの機能を統合したのがWindows Vistaに搭載された「Windows Speech Recognition」だ。マイクロソフトは、以前からボイス関連の機能を開発してきた。その成果としてWindows XP Tablet PC Editionに統合されたボイス機能があった。
このエディションでは、汎用的に音声入力や音声操作が可能だった。しかし、Tablet PC Editionは、通常のWindowsとは異なるライセンス製品で、一般的なWindowsの機能として統合されたボイス機能の提供はWindows VistaのWSRからとなる。なお、同時にTTSとしてWindowsナレーターも提供され、音声認識/音声合成データは、言語パックの基本的な要素となった。
ただし、WSRはいきなり現在のような形になったわけではなく、Vistaから時間をかけて段階的に発達してきた。たとえば、ボイス機能の下位で使われるオーディオスタック(オーディオ関連機能)の改良などがあった。
Windows 11でのボイス機能はどうなっている?
Windows 10までは、ボイス機能の中心はWSRだったが、Windows 11になってクラウド上のAzure Speech serviceを使う「音声タイプ」(Voice Typing)機能が提供されるようになった。
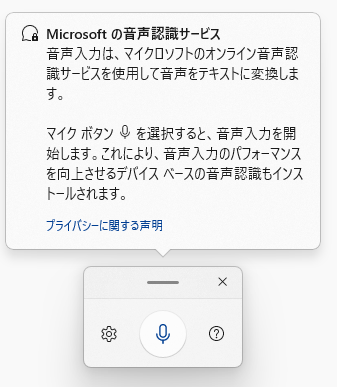
Windows 11 Ver.21H2(初版)には、Azure Speech serviceを使う「Windows音声入力」が搭載された。こちらは最初から日本語対応していた
この機能に関しては、Windows 11 21H2(ビルド22000)のプレビュー段階、Windows Insider ProgramのDev Channelで配布されたビルド21301で日本語対応されており、Windows 11は、最初から日本語の音声入力が可能だ。
そもそもAzureのAI音声機能は、クラウド側サーバーで実行されるAI技術利用した音声技術をローカルで利用するためのサービスで、TTS、STT、話者認識などに加え、音声翻訳などの機能を提供する。
しかし、Windows 11 22H2では、従来のWSRに代わるボイス機能としてWindows音声アクセスが別途提供されることになった。なぜ、このような状態になったのかについての説明はないが、Windows音声アクセスの英語以外の言語への展開に時間がかかることを想定して、音声入力だけはAzureの機能を使って他言語に対応させたかったのかもしれない。
ただし、クラウドの利用では、プライバシーへの懸念やセンシティブな内容に関して、組織外に情報が出ることへの懸念などから、消極的になるユーザーも少なくない。このためか、音声アクセスは、ローカルでの実行であることを強調している。
音声認識などのボイス関連技術も、画像認識などと同じくAIの大きな恩恵をうけた分野の1つだ。音声認識のためのニューラルネットワークの学習には、膨大なデータと高い計算力を持ったシステムが必要だが、学習が完了したネットワークは適切な後処理で、推論計算処理を簡略化でき、PC程度のCPU性能があれば、音声のリアルタイム認識程度の推論処理は難しくなくなってきた。また、Windowsも推論ハードウェアの搭載を推奨している。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第520回
PC
WindowsターミナルのPreview版 v1.25では「操作」設定に専用エディタが導入 -
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する -
第510回
PC
PowerShellの「共通パラメーター」を理解する - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























