

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「LangChainを格段に使いやすくするtips」を再編集したものです。
LangChainの用意しているプロンプトやラッパーは英語以外を意識していないことが多く、特に検索系のtoolがUSのサイトを引っ張ってくるということが多々ある。
こういったケースはtoken数に制限のあるChatGPT APIにとっては大きな問題になってくる。USのサイトが検索上位にかかってくることで得られる情報が減る上に、これを解消するために検索数を増やせばそれだけtoken数を消費するためである。当然だがtoken数の上限を超えればエラーを吐いて異常終了する。
こういった問題の多くは、LangChainのライブラリが用意しているクラスをそのまま使うことによって発生している。
またLangChainはagentの定義を行うだけで簡単に基本的な機能が使えてしまうため、agentがどのようなロジックで動いているのか理解しにくい。
本記事はLangChainを少しだけ掘り下げて、これらの問題を解決するためのtipsを紹介する。
tool呼び出しはBaseToolクラスを使う
先ほども触れたが、LangChainが用意しているtoolやwrapperは現状だと柔軟性に乏しい。
APIのwrapperの場合、呼び出し元のAPIが本来扱えるはずのパラメータが扱えなくなってしまうことが多々ある。
例えばBingSearchAPIWrapperであれば、本来'mkt'でサイトの地域を、'setLang'でUIに使用する言語を指定できるがこの引数がLangChainのwrapperには存在していない。
こういった問題は自分でtoolを作ってしまうのが手っ取り早い。
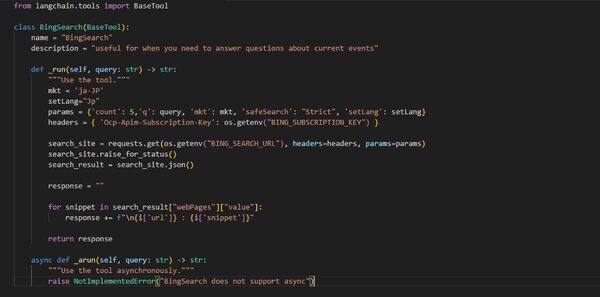
というわけで検索のtoolを自分で作った(BingSearchAPIを使用)。
難しいことをしているわけではないのでさっくりとしたものだが、言語の指定を行い、返り値を'name'と'snippet'に絞っている。
言語の設定は情報の確実さや鮮度、視点に大きくかかわってくる。一概に日本を指定することが良いこととは言わないが、特に鮮度、リアルタイム性という点では設定するべき項目だと思う。またtoken制限を意識して返り値をなるべく小さくする工夫も重要である。
BaseToolクラスのドキュメント(Python):
Defining Custom Tools | 🦜️🔗 Langchain
AgentTypeは使わない
AgentTypeにはそれぞれプロンプトが用意されており、initialize_agentでAgentTypeを指定すると用意されたプロンプトをそのまま使用することになる。
agentのプロンプトはデフォルトで以下のようになっている。
ZERO_SHOT_REACT_DESCRIPTION
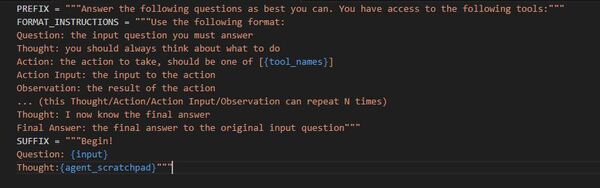
CHAT_ZERO_SHOT_REACT_DESCRIPTION
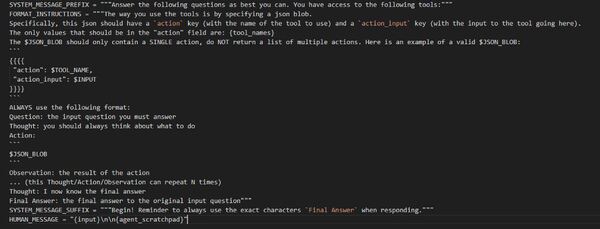
これだけ見ても分かりにくいのでAgentTypeが宣言されているクラスのコードを見るといいのだが、今はPREFIXの後にtoolの一覧とそのtoolの説明が入ると考えればいい。
重要なのはFORMAT_INSTRUCTIONSで、ここがagentの挙動の根幹を担っている。
そして、AgentTypeを宣言しているクラスのcreate_promptメソッドでプロンプトを変更することができる。
というわけで実際にZERO_SHOT_REACT_DESCRIPTIONのプロンプトを変えてみる。
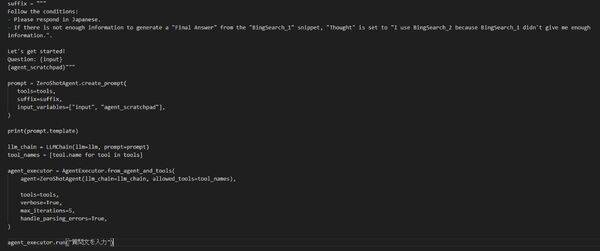
文末を少しだけ変えただけだが、これで日本語応答してくれるようになる。
また、toolの呼び出しにある程度干渉できる。
これでtool(上記コードの場合BingSearch_2)のdescriptionを "Thoughtで明示されたときのみ使用します" のようにすると特定条件でしか呼び出されないtoolが完成する。
便利な機能としてagentを定義する時にmax_iterationsを指定することでchainの最大繰り返し回数を指定できる。またhandle_parsing_errors=Trueとすればparserエラーを無視できるので、parserエラーが頻発する場合は指定するといいだろう(これはinitialize_agentでも使用できる)
プロンプトはtemplateメソッドで取得できるので必要な場合は記述しておくといい。
ZERO_SHOT_REACT_DESCRIPTION(ZeroShotAgentクラス):
langchain/libs/langchain/langchain/agents/mrkl/base.py at bd2e298468447845d4d8de3b5d2f6772e862973e · langchain-ai/langchain (github.com)
CHAT_ZERO_SHOT_REACT_DESCRIPTION(chatAgentクラス):
langchain/libs/langchain/langchain/agents/chat/base.py at bd2e298468447845d4d8de3b5d2f6772e862973e · langchain-ai/langchain (github.com)
ZERO_SHOT_REACT_DESCRIPTIONのプロンプトテンプレート:
langchain/libs/langchain/langchain/agents/mrkl/prompt.py at e83250cc5f4dc5edd1ae8fb0a41c40454d13fb9d · langchain-ai/langchain (github.com)
CHAT_ZERO_SHOT_REACT_DESCRIPTIONのプロンプトテンプレート:
langchain/libs/langchain/langchain/agents/chat/prompt.py at e83250cc5f4dc5edd1ae8fb0a41c40454d13fb9d · langchain-ai/langchain (github.com)
ログを取る
agentを走らせれば標準出力で大抵の情報が可視化されるが、これを変数として取得したい場合も多かったのでその方法である。
以下のようにagentの定義時にreturn_intermediate_steps=Trueを指定すれば良い、またrunメソッドは使用せずAgentExecutorにinputを直接渡すような形になる(intialize_agentでも可能)
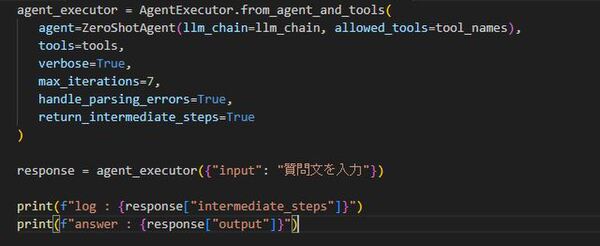
Access intermediate stepsのドキュメント(Python):
Access intermediate steps | 🦜️🔗 Langchain
おわりに
LangChainは便利なライブラリだが、まだ公開されてから日が浅いこともあり孫の手が欲しくなる場面が非常に多い。
また、公式のドキュメントもそこまで低いレイヤーの情報を提供していないので、GitHubのコードを見て理解していくしかないという場面も多い。
本記事が少しでも多くの人の役に立てば幸いである。
内藤楽晴/FIXER
2023年度に新卒で入社しました。 まだまだ学ぶことの多い時期ですが、いろんなことを吸収して自分の思うエンジニアに近づければと思います。 ちなみに名前の読みは「もとはる」です
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
自治体業務でどう使う? 生成AIアイデアソンに自治体職員が挑戦 -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 -
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) -
TECH
“GPT-10”が登場するころ、プロンプトエンジニアはどうなっているか? -
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう -
TECH
BPEの動作原理を学び、自作トークナイザーを実装してみた -
TECH
エンジニアとプロンプトエンジニアの違い、「伝える」がなぜ重要なのか -
TECH
システムエンジニア目線で見たプロンプトエンジニアリングのコツ -
TECH
学生向けの生成AI講義で人気があったプロンプト演習3つ(+α) -
TECH
ユースケースが見つけやすい! 便利な「Microsoft 365 Copilot 活用ベストプラクティス集」を入手しよう -
TECH
Gemini CLIのここがすごい! Go+Vue3のアプリを作らせてみた - この連載の一覧へ




