





メタは8月2日(現地時間)、テキストからサウンドを生成するための3つの生成AIモデルをバンドルした「AudioCraft」をオープンソースでリリースした。
3つのモデルで構成
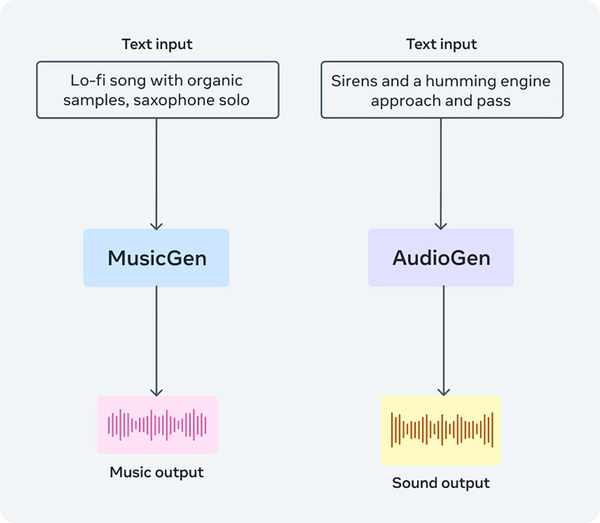
AudioCraftは、メタが権利を所有する音楽およびライセンスされた音楽で学習され、テキストから音楽を生成する「MusicGen」、公開されている効果音で学習され、テキストから効果音などのサウンドを生成する「AudioGen」、そして改良され、よりノイズが減った音声圧縮デコーダー「EnCodec」の3つのモデルで構成されており、すべてのモデルのウェイトとソースコードがオープンソースで公開されている。
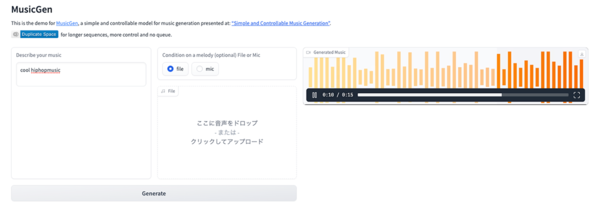
MusicGenのデモ
MusicGenはHugging Faceにてデモが公開されている。試しに「Cool Hiphop Music」というプロンプトで試してみるとたしかにそれっぽい音楽が生成された。
ただし、NVIDIA A10G Tensor Core GPUを使用した環境でも生成に80秒強かかったため、かなり重い処理をおこなっていると思われる。
メタは、テキストや画像を生成するジェネレーティブAIが盛り上がっている一方で、オーディオ生成に関する研究は少し遅れていると認識している。
忠実度の高いオーディオを生成するには、さまざまなスケールで複雑な信号やパターンをモデリングする必要があるのがその理由だ。「オーディオの中でも特に音楽は、一組の音符から複数の楽器を含む大域的な音楽構造まで、局所的かつ長距離的なパターンで構成されているため、間違いなく生成するのが最も難しいタイプのオーディオです」としている。
メタがオープンソースで公開する理由
メタは本ツールをオープンソースでリリースした理由として、オーディオ生成AIの研究が遅れているのは、研究内容が複雑でオープンでないため、研究者以外は気軽に試すことができないことをあげている。
これらのモデルをオープンソース化し、研究者や一般ユーザーが独自のデータセットを使ってこのモデルをトレーニングできるようにすることでさらに性能が向上し、生成AIによる音楽生成の発展に貢献していくのが目的だとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















