FIXER cloud.config Tech Blog
100台くらいスケールする“Kubernetesもどき”を自作してみた!
2023年02月10日 10時00分更新


本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「Kubernetesもどき、作ってみた!」を再編集したものです。
この記事はFIXER Advent Calendar 2022 技術編 23日目の記事です
こんにちは、毛利です。この記事では、最近趣味で自作し始めてしまったコンテナオーケストレーションシステム(+分散Key Value Store)の話をします。つまるところKubernetesのようなものを自作し始めた話です。
背景
要約:素のKubernetesは料金が高くなりそうだったので、趣味用に安く済むKubernetes環境が欲しかった。あと自作対象として興味がちょうどよかった。
みなさんは趣味用のサーバー等ありますでしょうか? 自分は学生時代からConoHa VPS(コンビニ支払いできるのが学生にやさしい)、最近はAzureも使っています。管理方法ですが、最初のころはサービスをホストに直置き、途中からdocker-composeを使うようになり、しばらくそれで管理していました。最近は業務でKubernetesを触ることもあり、Kubernetes系を使いたいなぁとなり、Azure Kubernetes Serviceだったりmicrok8sを使ってみたりしていました。
というわけで、趣味でもKubernetesを動かしたいわけですが、趣味用でそんなにお金を吹き飛ばせないので、料金はできるだけ抑えたいわけです。トレードオフの引き方としては、クラスタ運用の経験値が積めればよくて、「いつ何時落ちても吹き飛んでも文句なし!」、で引くことにしました。そうするとAzureでは全VMにSpot VMを使って、最大90%オフの恩恵を受けたいとなります。Azure Kubernetes ServiceではシステムノードプールをスポットVMのみで構成できないので、Spot VMのみにするにはVMを普通に借りて良い感じに構築する必要があります。手軽に構築できるものとしては、minikubeやmicrok8sがあります。どれを選んでも良かったのですが、ubuntuにログインするたびに布教されるmicrok8sを選んで、しばらくSpot VM上で動かしていました。snapで入りますしかなり手軽に使えた印象です。
microk8sをしばらく使っているといくつか問題が発生しました。一番大きいのはdqlite(一般的なk8sの構成においてはetcd相当)のディスクアクセスが多いことです。初めはStandard SSDを使っていたのですが、ディスクの料金が予定より多くて調べたところ、ディスクアクセス分の料金がそこそこかかっていました。Azureのメトリックとiotopで調べたところ、dqliteのアクセスが多いことがわかりました。この問題はStandard HDDにしてアクセスあたりの料金をおよそ1/4にして緩和できましたが、それでも容量代ぐらいはアクセスに料金がかかりました。今までディスクアクセス代をきちんと意識したことがあまりなかったので、気にする良いきっかけになりました(そもそもetcd相当はレイテンシーの低さが重要なのでローカルディスクを使うべきというのはそう)。
さて、ディスクアクセス代の問題ですが、「いつ何時落ちても吹き飛んでも文句なし!」でいくならディスクに保存する必要はなくて、完全オンメモリーでいいわけです。というわけでetcd相当はオンメモリー運用にしようと思いました。このあたりからもう全部自作してしまえば良くない? となり、Kubernetesもどきを作ろうと考え始めました。また、以前から分散アルゴリズムをなんか一度実装してみたいなぁとも思っており、etcd相当の分散KVSから作ることにしました。
少し別の話として、僕は趣味で競技プログラミングをやっているのですが、ヒューリスティック系のコンテストで多数のテストケースでの実行結果を得たい場面があります。少ないテストケースで判断すると、ある改善の効果がある・効果がないの判断や考察を間違えやすいためです。また、もっと大規模にスコアの自動調整などをしてみたい気持ちもあります。計算リソースが多ければ強くなるというものでもないですが、まぁなんかかっこいいので、お財布が壊れない程度にマシンを借りて計算させたいなぁと思うわけです。それこそ短期間の用途なので、AKSなりAzure Batchなりで良い気もしますが、どうせならそういう用途でも使いたいという要求があります。というわけで、常時借りたいわけではないですが、少なくとも100台ぐらいまではスケールものが作れるといいなと思っています。
いろいろ書きましたが、ここまでまとめると、以下のようなシステムを作りたいとなります。
・Spot VM onlyで動く
・etcd相当の分散KVSはオンメモリー
・100台ぐらいまではスケール可能であってほしい
調査
Borg
まずはKubernetesの元になっているらしいGoogle Borgの論文(その1、その2)をちょっと読みます。以下面白かった点です。
1. 生存確認は監視側から送る(その1 3.3節)
最初Kubernetesのliveness probeの概念を知ったとき、Pod側から生存確認信号みたいなのを送る方式ではないのが不思議でした。状態情報の収集をPodから見て受動的にしておくと、Master側から見て一気にいっぱいリクエストが飛んでくるのを防げたり、レート調整できるってメリットがあるんですね(ちゃんと読めてれば)。疑問がひとつ解消しました。
2. PodごとにIPアドレスを振っていない(その1 8.1節)
BorgではPod(相当)ごとにIPアドレスを振らず、ホストのIPとポートを使っているようです。Kubernetesに慣れた身からすると意外でした。この仕様はつらかったらしく、KubernetesではPodごとにIPを振れるようにしたみたいです。
KubernetesでPodごとにIP振るときのIPv4のときのVXLAN(主にflannel)とかBGP(主にcalico)分の負荷ってどれぐらいなんでしょうね。IPv6でやるなら負荷少なそうな気がします。
Raft
Masterノードが何台か落ちても大丈夫なように、Masterノード間でレプリケーションしてKey Value Store等を持つわけですが、適当にやるとノードが落ちたり一瞬疎通しなくなったり復活したりしたときに整合性が取れなくなります。そのへんを良い感じに整合性をとるためのアルゴリズムとしてはRaftやPaxosがあります。BorgではPaxosを使っているようですが、RaftのほうがシンプルらしいのでRaftにしました。etcdもRaftなのでいいでしょう。heartbeat関連のパラメーターの適切な調整が少し面倒そうですけれども(今もわからん)。
Raftのざっくりとした方針としては、KVSの操作履歴(ログ)をノード間で整合性が取れるように複製する、という方針です。操作履歴の結果としてKVSが実現される感じですね。
わかりやすかった資料は以下です。
分散アルゴリズムを実装するモチベーションですが、Azure Cosmos DBの整合性レベルのドキュメントに突如出てくることで知られる(?)TLA+をそのうちちゃんと勉強したいなぁと思っていて、分散アルゴリズムを実装してみてバグらせまくって、TLA+等による検証の重要性がわかるといいなぁみたいな気持ちがありました。まぁ人生で一度ぐらい分散KVS作っても損はしないでしょう、一度実装したら一度では済まない気はしますが。
KubernetesのController
その他にはKubernetesのControllerの動きについても調べました。当初ディスクに書き込まなくも損害があまりなさそうなデータを見極めようとしていて(結局すべて諦めた)、etcdが何の情報持ってるかを知りたかったのがきっかけです。雰囲気の理解は下記動画が良かったです。
・その48 Kubernetesのコントローラのプログラミングモデル - YouTube
どうあるべきかが記述されるみたいな概念がControllerの実装レベルでもそうなっているのが面白かったです。KVSの負荷が高そうな気はしますが。
あとはKubernetesのControllerのドキュメントが完全に制御工学よりで(Controllerなんだし冷静に考えればそれはそう)、そういう視点で今まで捉えられてなかったので少し感動しました。もはやコンテナオーケストレーションはControllerで実現される機能の1つぐらいの意味合いなのかなぁと思いました。
構成
リソースは以下の通りです。
・3台 * Spot VM E2as v5(Standard HDD)Master兼Worker
・Cosmos DB(Free Tierの1000RU/sを割り当て)
・Key Vault
・Automation(Spot VM起こし用)
Master兼Workerが3台です。Masterの台数を5台にしようか悩みましたが、費用的に5台にするなら2リージョン計6台でマルチクラスタのほうが楽しそうなのでとりあえず3台にしました。ただアップデートを考えると5台の方が安全そうだなぁとなっています。3台の場合、1台更新中にもう1台が落ちると過半数取れなくてクラスタが落ちてしまうので、更新時の余裕を持たせるなら5台は欲しいなぁと思いました(実際それで1度落としました)。計算リソースを増やしたいときはWorkerだけのノードを増やして対応予定です。
VMのパブリックIPアドレスですが、パブリックIPv4はひとつあたり400~500円程度掛かるので、料金がかからないIPv6のみにしています。IPv6 onlyにして詰まった部分がいくつかありますが、このあたりは別記事で書きました(リンク)。
Master間のレイテンシーを下げるために、Masterの3台には近接配置グループを使っています。近接配置グループが有効な場面が自分は初めてだったので、使えて良かったです。
メトリック用のログを入れる場所にはとりあえずCosmos DBを使っています。長期的にはBlob Storageあたりに整理して入れるバッチ処理を入れたいなぁと思っています。当初は分散KVSに入っている消えてほしくないデータをCosmosに入れておくことを考えていたのですが、GitOps的な発想にするならリポジトリから復元できるはずなので、今は何も入れていないです。アプリケーションが乗ってきたら使っていきたいと思っています。
各種シークレットについてはAzure Key Vaultを使いました。Masterが入っているサブネットだけアクセスできるようにして、Workerからは直接取りに行けないようにしました(とはいってもMaster兼Workerになってるので取りに行けてしまうが。。。)。
スポットで止まっちゃったVMを起こすのはAutomationを使っています。それぞれ時間をずらして1時間ごとに発火させてます。
Masterの機能としては、以下の機能がメインです。
・分散KVSの管理
・CLIからのPod作成要求受け取り
・PodのNodeへの割り当て
・Nodeの状態監視
・ダッシュボード用ログの作成
Workerの機能としては、以下の機能がメインです。
・Podの起動・監視
・Masterから飛んでくるheartbeatへの応答(+ Pod状態応答)
ノード内のコンテナ管理はdockerにおまかせします。最初はruncを直接使おうとしたんですが、別ノードのnetnsまでの疎通がubuntuでわからなくて、やめました。でも一通りnetnsとか仮想NICとか触れたので面白かったです。気が向いたらそのうちruncかcontainerd、もしくはsingularity(そういえば名前変わる話どうなったんだろう)、もしくはRustと相性良さそうなのでWASI系の何かを使おうかなぁなどと妄想しています。
Pod間通信ですが、ホストのIPを使うことにしました。calicoみたくbirdでも使ってBGPの練習でもしようかと思ったのですが、とりあえず動かす分にはやりすぎ感があったのでやめました。netns周りで手元がArch LinuxでVMがUbuntuで微妙に同じようにできない部分があったのも理由です。これに伴いDNS相当の何か(IPアドレスだけでなくPort番号も引ける必要がある)が必要になるわけですが、まぁほとんどKVSだしどうにかなるかなと思っています(未実装)。(ところでBGPどうやって実際に動かす勉強しようね…)
費用ですが、3台常時構成で全体で 6 vCPU, メモリー48GB で およそ5000円/月になりました。特にメモリーのコスパはかなり高いのではないかなと思います。まぁ趣味人件費? が大変なことになってる気はしますが。
実装
実装はRust言語で実装します。趣味コードは基本的に全部Rustで書いているので。
RustでAzureのリソースを使うのにはAzure SDK for Rustを使いました。まだUnofficialですが、このSDKを使ったリクエストが増えたりするとOfficialになるかもとのことなので、使えるだけ使っていきます。まだ発展途上なので、バグってるときはプルリクチャンスです。ちなみに初めてのOSSのCode Contributionをこれで達成しました、やったね(いままでドキュメントのfix typoしか経験なかった)。
RPCの仕組みをいい感じにする
Master間やMaster-Worker間、Pod間など、サービス間の通信が多いので、まずはRPCの仕組みをどうにかします。どうせ全部Rustで実装するので、gRPC等は使わずにRustだけで良い感じにしたいと思いました。Rustだけで書けるRPC用のライブラリとしてはtarpcなどがあります。traitの形でRPCを定義できて、とても良いなぁと思いました。これもせっかくなのでtarpcを参考に雑に自作しました。引数・返り値をjsonにして、各関数ごとにエンドポイントを用意するmacroを作成しました。Procedural Macrosとasyncの扱い(本来traitにasyncを使えない… と思っていたら最近nightlyで使えるようになった)で頭が爆発しそうでしたが楽しかったです。
Raft Consensusを使ったKeyValueストアを実装
Raftを使うKey Value Storeを実装していきます。
Raftは素直にはログを全部持つため、素直には保持するデータサイズがどんどん増えていきます。データサイズを削減させるために、本来はログのコンパクションとかをするようです。ただコンパクションの実装をバグらせる気しかしなかったので、あるキーに対して最後の更新のLog Indexを保持しておいて、commitされたログの範囲で新しく更新が入ったときに前のログを消す、というのを考えて実装したのですが、delete時にデータサイズを減らせない(たぶん)ことに実装してから気づいたので、後々コンパクションの実装をちゃんとやろうと思います。
実装を通してどれぐらいバグらせたかですが、ものすごくバグらせました。バグらせて理解できていない部分を理解して直すみたいなのを繰り返していました。一番ひどかったのはappend_entryの実装でログを書き込むのとcommitを進めるのの順番を間違えていて、みんなバラバラのログを持ち始めて頭を抱えたりしてました。
デバッグ方法ですが、まずバグってることに気付きづらいというのがあるので、どうやってバグってることに気づくかというのが重要な気がします。気づき方ですが、自分の経験ではそれぞれのノードのTermとIndexをログに流しておくと(できれば折れ線グラフで可視化しておくと)バグに気づきやすいと思います。数件のデータではバグらなくてもデータ操作数が多いとバグる、みたいなのも多かったです。この調子でバグをつぶしていくのは大変すぎるので、やはりTLA+等をちゃんと使ったほうが良いなぁと思いました。とはいえちょっとまだ精神的ハードルが高いなぁともなっています(モデル検査器自作のほうがやる気でるんじゃ…) とはいえ業務でTLA+を使えるところがあったら取り入れたいですね、Cosmos DB大好き人間としても。
GrafanaのJSON APIの実装
システムの画面の見た目がかっこいいのは正義なので、とりあえずGrafanaのダッシュボードを作りたいと思いました。主にスパコンの富岳のGrafanaの影響です(無限に見てられる、いつの間にか消費電力の欄が増えた?)。
メトリック用のログはCosmosDBにとりあえず放り込むことにしました。そうするとCosmosDB上のデータをGrafanaで可視化させる仕組みが必要になります。いろいろ調べた結果JSON APIをdatasourceにするのが良さそうだったので、それを使うことにしました。JSON API datasourceに関しては次の記事が分かりやすかったです。参考にした資料は以下です。
・GrafanaのデータソースにDynamoDBを利用できるようにしてみた | DevelopersIO (classmethod.jp)
でいろいろやると最終的にこんな感じになりました。かなり良い。
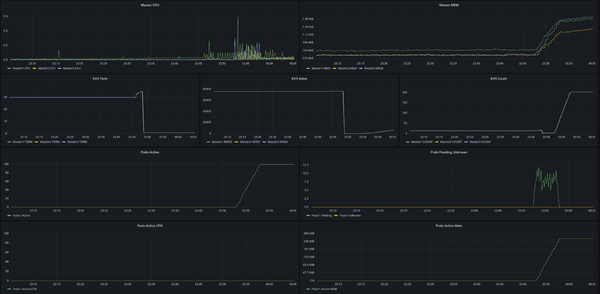
MasterのCPU・メモリー使用状況、KVSのRaftのTerm・Index・データ数、Podの状態(配置待ち数・不明〘疎通失敗〙、有効数、総CPU使用量、総メモリー使用量)です。KVS関連のメトリックは上でも述べたデバッグ用です。もし線が明らかにばらばらになっていたら、バグっていることが分かります。
dockerの各コンテナの状態取得
docker psやdocker statsには--formatオプションがあり(psのdoc、statsのdoc)、それを使うと任意のフォーマットで出力させることができます。ノード内の各コンテナの状態取得にはこの方法を使いました。
罠だった点としては、docker psに対して {{json .}} ですべての情報を持ってくると、ディスク使用量の情報を含む(.Size)のですが、この処理はものすごく時間がかかります。仕方ないので、formatをひとつずつばらして、.Sizeだけ取得しないことで対応しました。
その他
あとは各ノードのコンテナ管理サービス(kubelet相当)なりなんなりを気合で作ります。終わり。
実装はコアの部分で2000行ぐらい、他の趣味開発から使いまわしている部分が1000行ぐらいで3000行ぐらいでした。最低限であれば思ったより行数は少なくて作れるなぁと思いました。ただ実装の重さは(自分の感覚で)自作コンパイラより重かったです。Raftの実装に慣れてきたらもうちょっと軽く感じるんだろうか。
実験
nginxを100Podほど立ててみます。
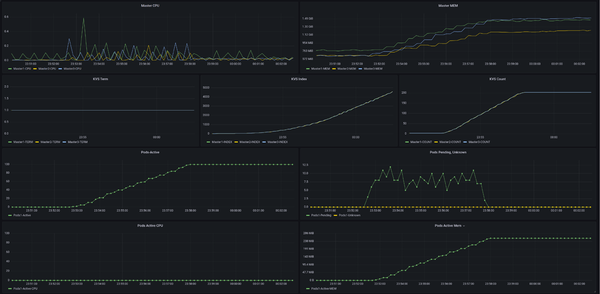
3秒ごとに1Podで、100Pod作成しました。ダッシュボードのPods-Activeが100になっていて成功です。Master CPUがギザギザしているのはdocker runが走っている影響、Pods Pendingが出ているのはdocker run待ちのPodです。他のメトリックもちゃんと動いていそうです。Podのノードへの割り当ては現状ただのランダムにしていて、ノードそれぞれに32、27、41Podずつ立っていました。
というわけでとりあえず一通り動きました、やったね。
感想と今後
一番思うところがあるのはControllerの部分でしょうか。先ほども似たようなことを書きましたが、分散KVS+Controllerのセットがカバーできる範囲がめちゃめちゃ広い気がしています。下手しなくてもコンテナオーケストレーションじゃなくてControllerが本体なのではという気持ちになっています。
Podの配置方法は結構いろんなアルゴリズムが考えられそうですね。まぁただ個人利用レベルだとそんなにひねらなくてもいいような気はします。
他に見方が増えた話としては、分散KVSの部分のレイテンシーが相当ボトルネックになりそうだなぁと感じました。大規模になればなるほどクラスタは(シングルマスターの場合)データセンター内リソースなんだなぁというのを改めて気づかされました(内部がどうなってるか知らないですが)。AKSのSLAが少し低めに感じるのはこのあたりの都合なのかなと思いました。裏を返せば数千台とかまでいかなければMasterがデータセンター越えをしても十分動作させれるんでしょうかね。
自作コンテナオーケストレーションとか言ってる人(自作コンパイラ比)あまり見当たらないなぁと思いました(どっちかというと自作コンパイラ界隈がめっちゃ盛り上がってる?)。作ってみよう的な資料があるとだいぶ変わるんでしょうかね。
今後ですが、とりあえずPodを削除できるようにしたいですね、現状Pod作成は実装したけど削除はまだ実装していなくて、Podを削除するには†クラスタをリセット†しないと消せないので。そのあとはReplicaSet、Deployment相当あたりでしょうか、この辺ができてくるとだいぶKubernetesっぽくなってくるんじゃないかなぁと妄想しています。
ある程度揃ったらVM100台ほど借りてなんか計算させたいですね。VM100台借りるのが効率いいかと言われるとものすごく微妙な気がしますが(HB120rs v2のSpot数台とかのほうがたぶんコスパいい)。あとは長期間運用しての統計情報収集とかでしょうか。まぁこの辺は乗せるやつをいろいろ書きながらやっていきたいですね。
僕は経験則的に3000行あれば作りたいものが一応形になると思っているんですが、今回も3000行ぐらいでちょっとびっくりしました。3000行ぐらいが僕の設計・コーディングの限界説が無きにしもあらずですが、組み合わせで作っていくならひとまとまりは3000行もあれば十分なのかもとも思います。
おわりに
意外とそれっぽいものは作れてしまいました。キーボードを叩くのと計算機ぶん回すのは楽しいですね(自分の興味対象がよくわからなくて、共通点を探すとキーボードを叩くことと計算機をぶん回すことになる)。
システム系の自作だとあとはバージョン管理システムの自作もしたいですね。作り始めて放置してるんですが、GoogleのPiper/CitCを参考に作ろうとしたらFUSE(Filesystem in Userspace)周りがファイルシステムすぎて、ファイルシステムを作ってるのかバージョン管理システムを作ってるのかわからなくなったんですよね、今度は良い感じにしたいところです。
毛利 真士/FIXER
三重県出身の毛利真士です
趣味は競プロ、Rust、サーバー周り、自作言語・コンパイラなどなどです
[転載元]
Kubernetesもどき、作ってみた!
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
アプリ開発の手戻りを防ぐ 「入力チェック(バリデーション)」の設計方法 -
TECH
WSL2でのGitHubの認証をできる限り簡単に行う方法 -
TECH
MacでGitHub CLIの認証を行う方法 -
TECH
ゆるく理解する自作シェル実装1:そもそもシェルってどんなもの? -
TECH
プロンプトエンジニアリングのコツは「5W1Hを忘れずに」 -
TECH
GitHubの 超・超・超 基本的な使い方まとめ -
TECH
業務で使えるExcel関数テクニック − 関数を使った動的な範囲指定のコツ -
TECH
zshの初期設定がダサい…。表示内容を自分好みにカスタマイズしていく -
TECH
Proxmox VE+OpenMediaVaultで自宅用NASを作ってみた -
TECH
Chrome拡張はVue.jsで作るのがおすすめ -
TECH
gitコマンド、長いしだるいしMMS(マジ・短く・したい) - この連載の一覧へ




