
本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「Rust言語で書ける機械学習ライブラリcandleを使って自作言語の言語モデルを自作してみた話」を再編集したものです。
こんにちは、毛利です。
最近はChatGPTやLLMが盛り上がっていますね。趣味の一つに自作プログラミング言語・コンパイラがあるのですが、LLMと組み合わせてなんかできないかなぁと妄想しています。この記事ではcandleというライブラリを使って自作言語の言語モデルを自作(学習)してみた話について書きます。
TL;DR
1. candleというHuggingFaceが作っているRust言語で書けるライブラリについて一通り書いています
2. 学習させるのは自然言語ではなく、LLM向きに設計した言語を学習させることにしました。手始めに、数字の順番を逆に記述した2進数の加算の式を言語としてみました。例えば、111 + 1 = 0001. のようなものです
3. candleを使った言語モデルの実装を行いました。実装はすべて記事中に記載しています
4. 結果として、今回の実験の設定では数字の順番を逆にすると少ない学習量でも精度がでる言語モデルが作れることがわかりました
Rustについて
初めにcandleが使っているRust言語の話をします。
公式サイトによれば、Rust言語はパフォーマンス、信頼性、生産性に重きを置いているようです。
パフォーマンスに関しては、エネルギー効率がかなり高い(実質パフォーマンス)、といった話であったり、GitHubのコード検索にRustが使われ始めたり、GCがないメリットからdiscordで使われていたり、といった話があります。実際書いていてもC++と同じぐらいか早いぐらいの速度がでる印象です。
信頼性に関しては、所有権という仕組みによって、GCなしでもメモリ管理が適切に行われつつ、怪しい操作はコンパイル時に落としてくれるようになっています。最近感じているメリットは、並列で走るタイプのコードを書いているときに、スレッドセーフなものを使う/使わないを気にしなくていいことです。だめなときはコンパイル時に落としてくれるので、実はスレッドセーフな構造体を使わないといけなかった、みたいなところに脳を割かなくていいのがうれしいです。
生産性に関しては、rustupによるRustのバージョン管理や、cargoによる依存関係管理・ビルドが非常に楽です。フォーマッタ(cargo fmt)やlinter(clippy)も公式で存在します。また、Rust界隈は公式ドキュメントがとても丁寧なことが多く、基本的に公式ドキュメント(docs.rs)とリポジトリのexamplesを見に行くと大抵の調べたいことがわかります。
自分はRustを書き始めた5年前ぐらいから、趣味のプログラミングはほぼすべてRustで書いています。派閥がありそうなところでいうと、フロントエンドはyew(+trunk), バックエンドはactix-webを使うことが多いです。さてRustばかり書いていた結果、大抵の場合Pythonが使われる機械学習系の実装はほぼほぼノータッチになっていたのですが、最近のLLMブームで気になっていたところ、Rustで書けるcandleというライブラリが出ていたのでついに手を出してみました。
candleについて
さて、Rustで書けるcandleという機械学習ライブラリが出ていました。これについて書きます。candleのリポジトリのURLは https://github.com/huggingface/candleです。
URLからわかる通り、candleを作っているのはなんとHuggingFaceです。HuggingFaceがここにリソースを割くってのが自分は少しびっくりしましたが、Pythonのつらいポイントは業務でめちゃくちゃ感じてるので、そういうモチベーションがあっても不思議ではないかぁとも思います。
他の機械学習フレームワークに対してcandleはどういったところが良いのか?といったところですが、これはREADMEに書いてあります。
https://github.com/huggingface/candle#why-should-i-use-candle
適当に訳すと、
1. サーバーレスな推論ができるように。PyTorchのようなフレームワークはでかすぎるのでバイナリを軽くしたい
2. 運用ワークロードからPythonを取り除きたい。特にパフォーマンスやGIL(Global Interpriter Lock)の観点から
3. Rustは素晴らしい〜〜〜 ちなみにHuggingFaceのエコシステムの多くはRustのcrate(ライブラリ)がすでにある
といったところでしょうか。coolの訳難しいですね...
1. は最近悩んでいる部分を考えるとたしかになぁと思うところがあって、例えば、HuggingFaceの各モデルのページにあるHosted inference APIのComputeボタンがありますが、こういったものをシステムとして提供しようとすると、Imageはでかい、リソースの要求量はでかい、GPUもほしい、でほぼほぼKubernetesの常時起動一択みたいになってちょっとつらい、というのはありますよね(遠い目)。
2. は...まぁこれもちょっとわかりますね。
Global Interpriter Lockは最近業務でPythonを書いていて知りました。出会ったのは並列(特にマルチスレッド)化しようとしたときで、CPUバウンドな処理のマルチスレッドが性能でない、とのことでつらくなりました。まぁ抽象機械使うタイプの言語を実装してねといわれたらとりあえずそうする気はするので、そういうもんかなぁという気もします。一応Python側でGIL解消に向けての動きはあるようですね。PEP 703 – Making the Global Interpreter Lock Optional in CPython | peps.python.org
ここで型が挙げられてないのは少し不思議ですが、Tensor型が実質Objectみたいな使い方になるので機械学習本体としては型はあんまりメリットにならない、より正確にはメリットになる型の使い方をできていない、といったところでしょうか。
3. はまぁそうですね、少なくとも趣味レベルでは論理に先行してRustを使いたいです。。
ちなみにcandleは普通にGPU(正確にはNVIDIA GPU)が使えます。後に書くコードでもGPUを使った学習を行いました。
何を学習させるか?
さて、何かを学習させるコードを書くわけですが、最近激アツの言語モデルを作りたいと思います。
言語モデルということでなんらかの言語を学習させるわけですが、趣味レベルでは自然言語にそんなに興味はなく、「言語モデル向きの言語を作り、個人でも学習できるサイズの言語モデルを学習し、それをしゃべらせて何らかのシステムを構築する」ことに興味があります。特に、思考に関する部分について、LLMが使う言語は自然言語でなくていいと思っており、例えば、Chain of Thought なり ReAct なりを人工言語で動かすといった感じです。
というわけで手始めに二進数の足し算ができる言語モデルを作ることにしました。
さて、ここで一つ試したいと思っていたことを試したいと思います。
自作プログラミング言語を考えていたときにどうしようか迷った、というか今も迷ってる仕様があり、それは数を書くときの数字の順番を逆にするというものです。例えば、123は321と書く、といった感じですね。
メリットとしては、足し算などをするときに、記述順に計算していけるというのがあります。
例えば、456 + 789は6+9から計算しますが、これは普通の日本語の順だと後ろの方から計算していく形になります。一方、逆順に書いた場合は、654 + 987 = 5421となり、前から順に繰り上がりの計算ができます。
これはGPT系統の言語モデル向きでもあると思っていて、前から書かないといけない言語モデルにおいて、加・減?・乗算を計算順に出力できる点が向いているのではと思っています。普通の順番の場合、繰り上がりをエスパーして先に上位の桁から出力するみたいな芸当が要求されるわけで、そりゃ精度でないでしょうと思っています。
逆順にするのは慣れてないので違和感はありますが、例えばアラビア語だと普通の文が右から左に書くのに対して数字の順番は下の位から(つまり日本語と見た目は同じ順)みたいなので、ありだとは思うんですよね。慣れれれば。...慣れれればがネックで、自作プログラミング言語に入れるか迷っている最大の理由ではあります。流暢に認識できるかというとたぶん大変だよなぁと。
まぁいろいろ思うところはありますが、一回やってみたかったので、数字順反転の式を学習させてみました。
candleの基本構造体
Tensor
docs: Tensor in candle_core - Rust (docs.rs)
基本的にcandleを使った計算はほぼほぼTensor型になります。
「機械学習でよく使う操作が使える多次元配列であり、(backprop用に)どう計算されたかの情報も持っている」、ぐらいの認識でいいと思います。
Device
docs: Device in candle_core - Rust (docs.rs)
機械学習ではCPUだけでなくGPUを使うことが多いです。基本的にはCPU/GPUでメモリ空間が別れているので、各Tensor型の値に関して、どこでデータを持つか?という部分を指定する必要があります。これに使われるのが`Device`です。
基本的には、`Device::cuda_if_available` を使っておけば十分だと思います。この関数は、CUDAが使えるならGPUになり、使えない場合はCPUのメモリを使ってくれます。
VarMap, VarBuilder
docs: VarMap in candle_nn::var_map - Rust (docs.rs), VarBuilder in candle_nn::var_builder - Rust (docs.rs)
多層のニューラルネットワークにおいて、例えば層ごとになど、パラメータの塊が複数存在することになります。それらをまとめて管理する仕組みが`VarMap`, `VarBuilder`です。パラメータのファイル保存・読み込みに関してもVarMapを使うことで実現できます。基本的には以下のようにテンプレ的に使えば十分だと思います。

`VarMap`,`VarBuilder`は階層化されており、例えば、`layer1/weight`, `layer1/bias`のようにパスのようなKeyに対してパラメータの塊を持ちます。`VarBulider`に`pp`という関数があり、`var_builder.pp("layer1")`は、`layer1/`下にパラメータを入れていける`VarBuilder`となります。
実装
注:この節は長いので実装にあまり興味がない場合は実行結果まで飛ぶことをおすすめします
GPT的なDecoderの構成で作りました。Masked Multi-Head Attention + Feed Forwardの多層構成でPre-Normです
Transformerについては下記記事・動画がわかりやすかったです。
・How does GPT-3 spend its 175B parameters? — LessWrong
・とりあえずパラメータ群の使われ方を知るのに
元論文は下記です
[1706.03762] Attention Is All You Need (arxiv.org)
[2002.04745] On Layer Normalization in the Transformer Architecture (arxiv.org)
実装にはcandleのexamplesのBERTの実装を参考にしました。
実装は全体で400行ぐらいとなりました。推論をさぼってますが学習だけなら基本的なAttentionはそんなに実装量多くないですね。
一点注意点があり、PyTorch-likeに作られているのですが、自分がPyTorchに詳しくない、というか一般的な機械学習系のライブラリの使い方をろくに知らないので、いろいろ調べながら書いています。もしかしたらいたるところもうちょっといい書き方があるかもしれません。
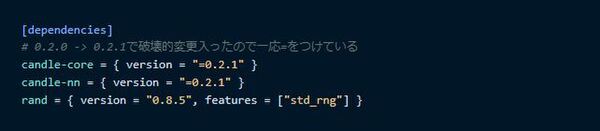
Cargo.toml(依存関係)
Cargo.tomlのdependencyです。`candle-core`に`Tensor`や`Device`などがあり、ニューラルネットを組むのに便利な構造体等は`candle-nn`にあります。
use
まずは使う構造体なり関数群のuseです。

Vocabulary
今回は7種類のTOKENとします。`_`が`<PAD>`相当、

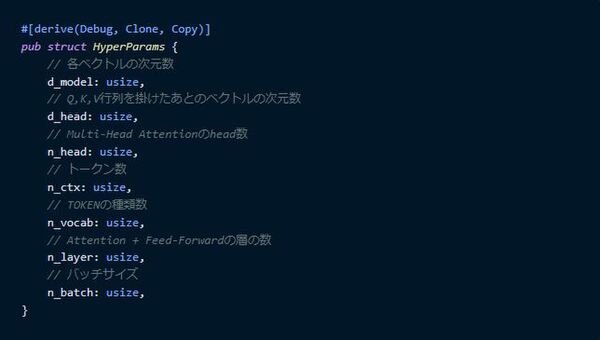
ハイパーパラメータ
次はハイパーパラメータ用の構造体を作ります。
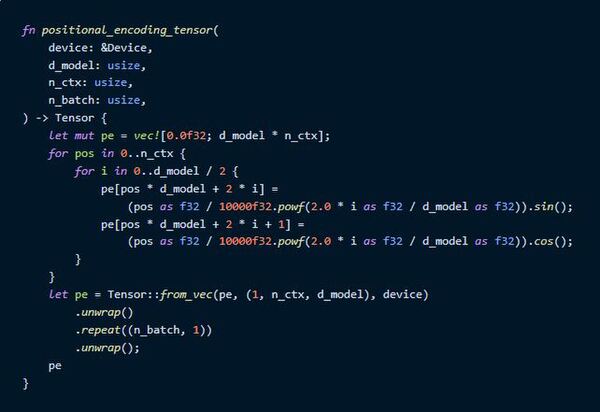
Positional Encoding
次はPositional Encodingの実装です。普通のAttention層自体には位置情報の要素がないので、先に位置情報を表すベクトルを入力に足しておく、というものですね。それぞれのトークン位置に対して、d_model次元のベクトルを作成します。
計算したそれぞれの値を使って`Tensor`型にするには、`Vec<T>`型に一列に入れておいて`Tensor::from_vec`を使うと作れます。
計算式はよく使われている三角関数の式を使いました。
Multi-Head Attention
次はMulti-Head Attentionです。まず構造体を作っておきます。
maskは後ろのトークン(ベクトル)を見れなくするための行列、qs,ks,vsはQuery,Key,Valueを作る層をHeadの数分、oはそれぞれのヘッドについてQuery,Key,Valueを使った計算をしたあとに、d_model次元のベクトルに戻す部分です。
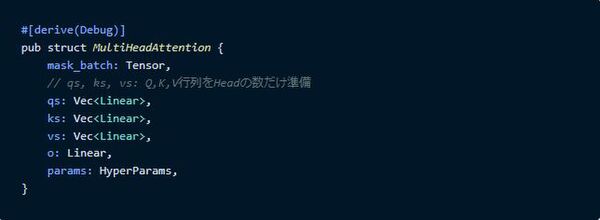
次は初期化のコードになります。
線形層のLinearは`candle_nn::linear`を使って作れます。
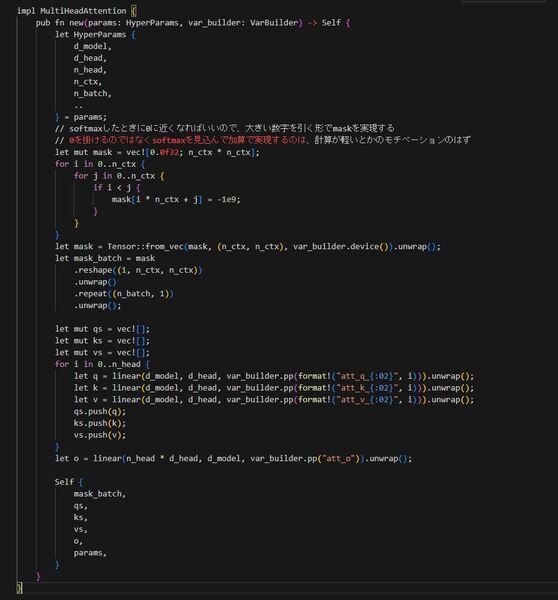
次はforward(前向きに計算する処理)の記述です。
`Tensor::reshape`は全体として同じ要素数の別の形のTensorに変える関数です。
`Tensor::transpose`は転置する関数です。0-indexedで指定した2つの番目の次元を転置します。
`Tensor::repeat`はTensorを繰り返して並べたTensorを作る関数です。
`Tensor::softmax`は指定した次元の列でsoftmaxをします。Pythonの[-1]アクセス相当の、後ろから数えて次元指定することもできます。
`Tensor::matmul`は行列積です。
...本当はこれ`Vec<Tensor>`じゃなくて一つの`Tensor`にできる気がしますが、とりあえずこれで書きました。
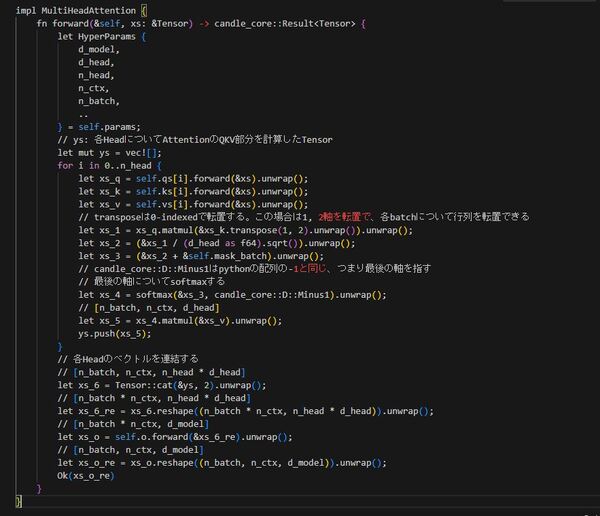
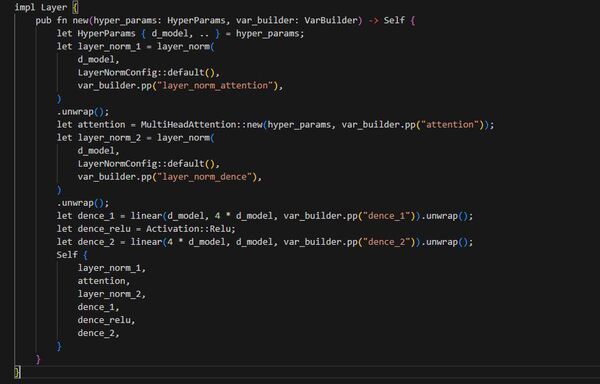
Layer
MultiHeadAttention層は書けたので、これを使ってTransformerの一層分を作っていきます。
同じく構造体をまず準備します。
`LayerNorm`はLayer Normalizationを行う層で、candle側で準備されているものがあるのでそれを使います。これは`layer_norm`関数で作れます。
`dence_1`, `dence_2`はFeed Forward層用の層です。Reluのような活性化関数は`Activation`型を使うと実現できます。
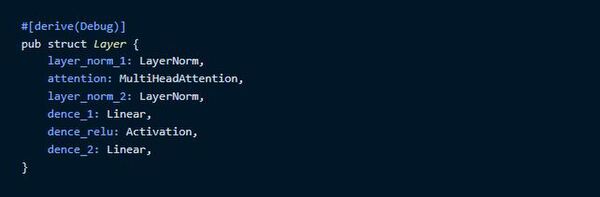
次に初期化の処理を記述します。
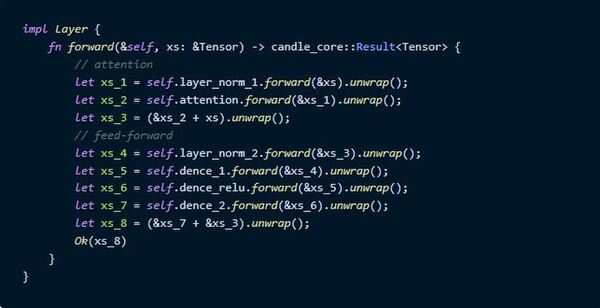
次にforwardの処理を記述します。こっちは一直線でシンプルですね。
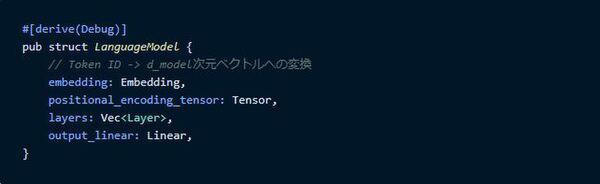
言語モデル全体
最後に言語モデル全体を表す構造体を作ります。
次に初期化の実装です。
indexに対応してベクトルを持つ仕組みは`Embedding`構造体を使うと実現でき、これは`embedding`関数で作れます。
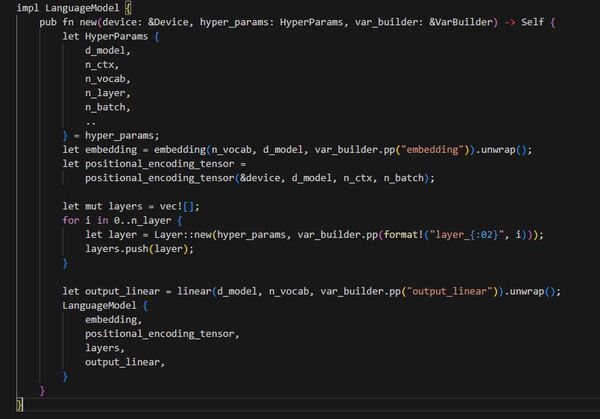
次にforwardの実装です。
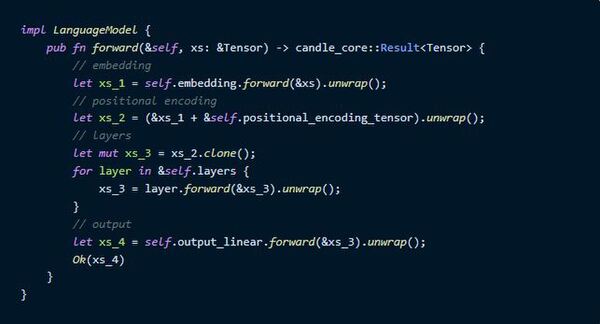
これでとりあえずパーツはそろいました。
学習データ作成
学習データ用の数字順反転の足し算の式を作っていきます。
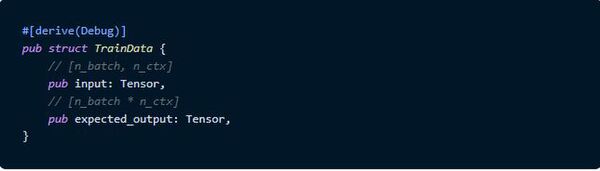
まずは学習データ用構造体を作ります。それぞれのTensorの要素はVocabularyのIndexです。
次に逆順の式を作ってそれで学習データを作る関数を作ります。
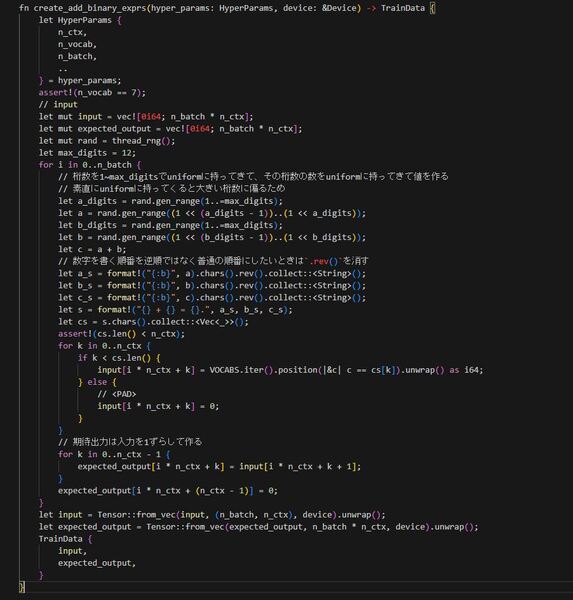
全体作成
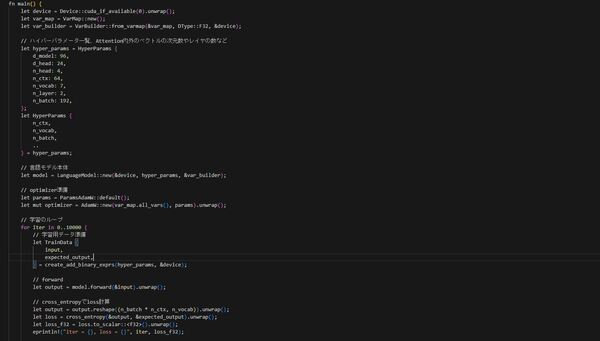
最後に学習データを使って計算してパラメータ更新を行うコードです。
Lossの計算には`cross_entropy`関数を使っています。
学習ですが、以下2ステップでできます
1. パラメータ調整手法のAdamを使う`AdamW`というのがあり、その値を作成
2. lossまでforwardしたら`loss.backward().unwrap()`でback propagationを計算して、`backward_step`でパラメータの更新を行う
実行方法
実行は以下のコマンドでできます。
CUDAがない場合は--features candle-nn/cudaなしで実行してください。

featuresについてですが、Cargo.tomlに書いてもいいのですが、CUDAを使えない環境のCIが通らなくなるので、自分はCargo.tomlには書かない形を取りました。
実験結果
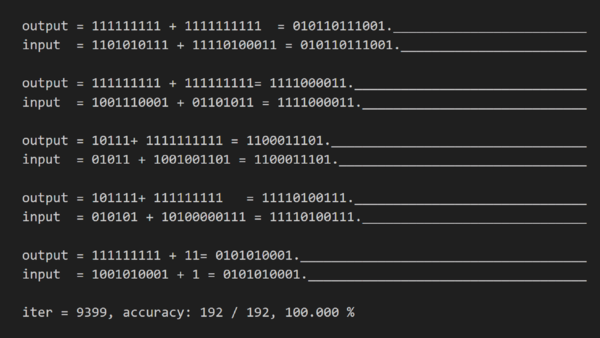
1batchあたり192文で、7000バッチぐらいでほぼ確実に正解するようになりました。実行時間としては 10000batchで RTX3060 12GB を使って30分ぐらいとなりました。
手始めにやるにはちょうどいい問題になったかなと思います。
正解の様子は以下の図のようになりました。情報が揃う=以降が推測できていることがわかります。
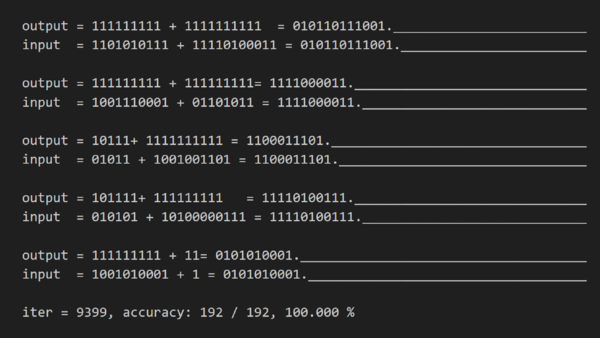
forward時の推測結果
正解率の変動は以下の図のようになりました。数値の記述において、数字の順番を逆順にしたほうが正解率が上がるのが早いことがわかりました。ときどき正解率が極端に下がる場面があるのは謎です。
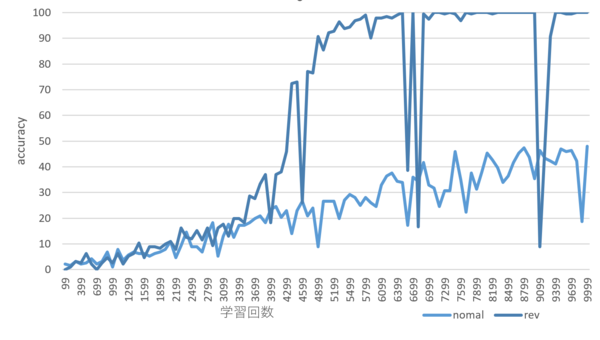
数字の順番が通常順(normal)の場合と逆順(rev)の場合のaccuracyの推移
というわけで想像以上に良い感じに動きました。やったね。
感想
Rustで機械学習系のコードを書けるのがめちゃくちゃうれしい
うれしい。
例えば趣味で動かしてるフロント/バックRust製のStatic Web AppsのFunctionsで動くバックエンド部分にちょっとした機械学習系のコードを使うこともできそうです。わくわく。
自作言語にTensorを言語の機能としていれたいと思った
さてTensor型とかいう概念に初めてちゃんと触れましたが、結構面白かったです。
ちょっと思ったのは、これってプログラミング言語側でサポートしてもいいのでは?と思いました。実質基本型みたいなメソッドの数してますし。
ちょっと表現が難しいのですが、おそらくdefine-by-run的な部分に由来すると思うのですが、forwardとしては計算であり、backwardに使われるという意味では計算の記述でもある、みたいなコードが面白いなぁと思いました。もうちょっと言い換えるとHaskellのthunkみたいな遅延評価っぽい計算木をコード上で操作できるみたいな印象を持ちました。両方の性質を持ってるコードにあまり心当たりがないので、こういうプログラムの記述があるんだなぁというか面白いなぁと思いました。
また、素の配列よりは抽象度が低いので、最適化に使える情報量が多くなっていいんじゃないかなぁとも思いました。
追加できるといいなと思う部分としては、次元の時点で間違っている計算についてはコンパイル時に教えられるといいですね、broadcastの扱いがちょっと大変そうなのと、依存型が必要そうな気はしますが。
まぁというわけでそのうち自作言語にTensor相当を言語機能として入れようかなと思います。どのみちGPUその他もろもろを自作言語でもぶん回したいですし。...いつできあがるのかわかりませんが。
LLM向け言語の設計しがいがありそうとわかった
数字の順番を逆順に、がここまで効くと思ってなかったので、LLM向け言語の価値あるかなぁとか思っていましたが、実際やってみると結構効いてそうなので、普通に発想としてありだなぁと思いました。
次は減算ですかね、たぶん符号を後ろに持ってこればどうにか...なるか?
おわりに
Rustはいいぞ
毛利真士/FIXER
三重県出身の毛利真士です
趣味は競プロ、Rust、サーバ周り、自作言語・コンパイラなどなどです
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
BPEの動作原理を学び、自作トークナイザーを実装してみた -
TECH
「AIに頼んだけど、なんか違う」を卒業しよう。再現性を生むプロンプト設計のコツ -
TECH
GoogleのAIエージェント開発ツール「ADK」とは 簡単エージェントの作り方 -
TECH
AIの使いこなしに必要な「始動する力、試行力、感情を抑制する力」 AOAI Dev Dayレポート -
TECH
AI時代の「良いAPI」とは? APIとMCPの関係は? Azure OpenAI Service Dev Dayレポート -
TECH
新登場の「ChatGPT agent」は何ができる? どうすごい? -
TECH
Gemini CLIのここがすごい! Go+Vue3のアプリを作らせてみた -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 -
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) -
TECH
“GPT-10”が登場するころ、プロンプトエンジニアはどうなっているか? -
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう - この連載の一覧へ