ロードマップでわかる!当世プロセッサー事情 第701回
性能が8倍に向上したデータセンター向けAPU「Instinct MI300」 AMD CPUロードマップ
2023年01月09日 12時00分更新

Instinct MI300のAI性能はMI250Xの8倍
次が性能の話である。今回Instinct MI300が「AI性能で」MI250Xの8倍になる、という説明があった。これをもう少し考察してみたい。MI250の内部構造は連載644回で説明したように、1つのダイに14×8=112XCUという計算であった。これが2ダイ構成なので合計224XCUである。ただ実際には2XCUは無効化して110XCUとして利用しているので、2ダイで220XCUである。
一方MI300は1つのタイルあたり4×10×4で160XCUとなる。これが6タイルなので無効XCUがないと仮定すると合計で960XCU。仮にXCUの性能そのものが変わらないとしても、これだけで4.37倍ほどの性能向上が実現する計算になる。
XCUは通常のベクトル演算以外に、FP16およびBF16のマトリックス演算をサポートしており、AI性能ということはおそらくこのマトリックス演算の性能と思われる。MI200の数字が下の画像であるが、通常のベクトル演算の8倍のスループットが実現できる。
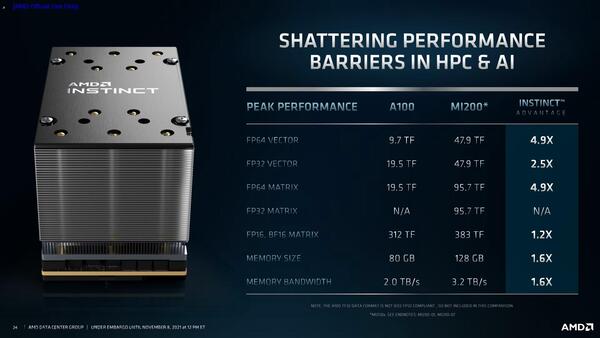
MI200の性能
さてMI300であるが、連載672回のスライドで、“New Math Formats”と言及されている。連載672回でも書いたが、これはFP16/BF16をFP8に変更した、という話である。
FP8のフォーマットは連載661回で説明しているが、仮数部は2bitないし3bitで、FP16の10bitやBF16の7bitに比べると大幅に桁数が少ない。したがって同じ演算回路規模なら2倍の性能向上が実現することになる。
先の4.37倍とこの2倍を掛け合わせると8.74倍という計算になり、8倍が簡単に実現してしまった形だ。実際には動作周波数が違う(おそらくMI200シリーズより下げないと間に合わない)だろうし、無効XCUなどもあるだろうから、もう少し性能比は縮まり、おおむね8倍程度になるのだろうと想像される。
つまりベクトル演算に限って言えば言えば4倍程度になるということだ。ちなみに計算の簡単化のために、ここにはZen 4コアの計算能力は加えていない。もしZen 4の分まで計算に入れると4倍を下回る可能性もある。ただAIで言えば、CDNA3はFP8で計算を行えるのに対し、Zen 4のAVX512に実装されているVNNIはINT8なりBF16なりでFP8には未対応である。なので恐らくZen 4の性能は加味されていないと思われる。
ところで性能が8倍になるのに消費電力効率は5倍、ということは絶対的な消費電力はMI200シリーズの1.6倍に跳ね上がることになる。MI250の場合は液冷で560W、空冷で500Wというスペックだったが、MI300ではそれぞれ896W/800Wになる計算だ。このクラスで空冷は非現実的なので、おそらくは液冷で900Wということになる。
OAM(OCP Accelerator Module)の最新スペック(v1.5)でも確認したが、P48V(48V電源ライン)の最大供給能力は700Wに限られており、「大丈夫なのか?」とやや気になる部分ではある。
とはいえ、MI300はこれ1つでFP64 Vectorが最大192TFlopsを実現する。El Capitanは1ノードにEPYC×1+Instinct MI300×4の構成である。このEPYC×1はおそらくネットワーク制御のみに使われるもので、計算処理はInstinct MI300で行なわれると思われる。
ということでノードあたりのFP64の性能は768TFlopsに達しており、2 EFlopsを実現するのに2605ノードあれば足りる計算になる。ノードあたりの消費電力は、MI300の消費電力を仮に900Wと仮定すると4KWほど。2605ノード分で10MW強に収まる計算だ。

ローレンス・リバモア国立研究所の「El Capitan」
実際にはEl Capitanの構築にはHPEも絡んでいるのでSlingshotでネットワークを構成するだろうし、計算ノード以外に管理ノードやストレージの分もあるだろうから10MWでは足りないだろうが、20MWには達しない程度で収まる計算になる。
Frontierの場合と同じく動作周波数をもう少し下げ、その分ノード数を増やして性能/消費電力比を向上させるかもしれない。ただFrontierが9248ノードと数が多く、その結果として絶対性能はともかく効率が低いという話は連載670回で触れたとおり。El Capitanはノード数が大幅に減っているので、この効率向上にも貢献しそうだ。
もともとAMDのリリースでは、El Caputanは2023年初頭に稼働という話であったが、実際にはやや後ろにズレた格好ではある。といってもすでにローレンス・リバモア国立研究所にはMilan+Instinct MI250X構成のパイロットシステムであるrzVernal/Tioga/Tenayaという3つのシステムが稼働中であり、2022年6月にはこの3つがすべてTOP500の200位以内に入っているというあたり、この程度の遅延は問題にならないのだろう。
というわけでCPUタイル周りは謎のままであるが、Instinct MI300がわりと現実的に出荷に向けて進んでいることが明らかになった発表であった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













