




AD103をわざわざ製造したのは
600mm2のダイに使うのはコスト的に割に合わないから
Ada Lovelaceの場合、トップエンドのGeForce RTX 4090がAD102なのは従来と同じだが、続くGeForce RTX 4080向けに新たにAD103をわざわざ製造し、これを充てているのが従来と大きく異なる部分だ。そしてキャンセルされた結果として、GeForce RTX 4070あたりにリブランドして出てくると思われるGeForce RTX 4080 12GBは、AD104を使うことになっている。
なぜこんなことに? に関する公式な表明はもちろんないので筆者による推定なのだが、Ada Lovelaceのホワイトペーパー表を見るとなんとなくわかる。AD102は、TSMCの4Nプロセス(*1)であり、基本的なジオメトリやトランジスタ密度はTSMC N5と大きく違わない(*2)と考えられる。
(*1) これはTSMC N4をベースにしたNVIDIAカスタム版プロセスとされるが、基本的にはTSMC N4と同等と考えていいだろう
(*2) N4の改良型であるN4PはN5比で6%トランジスタ密度が向上したとしているが、N4のトランジスタ密度は明確に言及がない
それでいて608.5mm2というダイサイズは、もうGPUというよりはAIのそれも学習向けプロセッサーに比肩しうる規模である。AIの学習向けプロセッサーが最低でも数十万、通常は百万円台の値段付けがされていることを考えると、いかにNVIDIAといってもこのAD102のカットダウン版などを使ってGeForce RTX 4080を作るのはコスト的に割に合わないと判断したものと思われる。
もともとAD102は12GPCの構成になっているにも関わらずGeForce RTX 4090は1GPCを無効化した11GPC構成で発売されている。
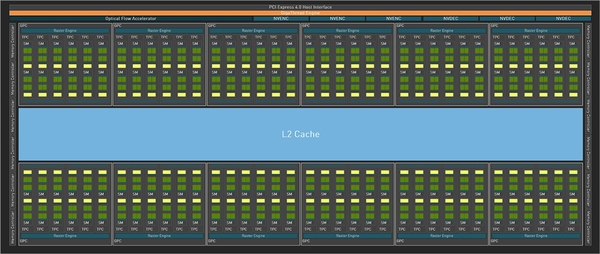
GeForce RTX 4090は1GPCを無効化した11GPC構成になっている
これは将来、12GPC構成となるGeForce RTX 4090 Tiなどを出荷するためのヘッドルームになるが、その一方ですでに欠陥があるダイであってもGeForce RTX 4090で救えるわけで、ここでさらにGPC構成を絞ったGeForce RTX 4080を投入したところで、その数は需要を十分に満たせるほどにはないだろう。
なにしろ600mm2のダイということは、1枚のウェハーから取れる個数は100個前後でしかない。TSMCのN5プロセスの場合、おおよそのウェハー1枚のコストは1万7000ドルほどで、つまり歩留まりが100%だとしてもダイ1つあたりの製造原価は170ドル。実際には200ドル近いと考えていい。
これにGDDR6X、基板、電源周りのパーツ、それに実装コストなどを考えると、定価1599ドルのGeForce RTX 4090はともかく、1199ドルのGeForce RTX 4080に使うと、赤字にはならないもののかなり利幅は薄いものになるだろう。将来の競合製品の投入の際の値下げの余地などを考えると、到底600mm2のダイではわりに合わないと判断したとしても無理もない。
ここまでは理解できるのだが、今ひとつ理解できないのが、AD103とAD104である。現状AD103とAD104のダイそのものの構成(製品構成ではない)は公開されていないが、普通に考えるとどちらもフル構成ではなく、歩留まり向上のために無効化しているGPCがあると考えるべきだろう。
つまりAD103は本来8GPC、AD104は6GPC構成で、ここから1GPC無効化してそれぞれ製品化する予定と考えられる。この構成の話は後述するとして、8GPCと6GPCはスペック的に近くないだろうか? ということだ。これはダイサイズにも反映されている。
AD102は12GPCで763億トランジスタ、608.5mm2。対してAD103は8GPCで459億トランジスタ、378.6mm2。AD103を基準に考えるとAD102はトランジスタ数が1.66倍、ダイサイズが1.60倍といったあたり。GPCの数が1.5倍なのを考えれば、おおむね納得できる寸法比とトランジスタ比である。
同様にAD103とAD104についても、AD104を基準に考えるとダイサイズが1.28倍、トランジスタ数が1.29倍ということで、これも8GPC vs 6GPCの比を考えれば比較的納得しやすい。ただ演算性能などの数字を見るとわかるが、そんなに大きな違いではない。
実際NVIDIAが当初はAD104をGeForce RTX 4080 12GB版として売ろうとした理由も理解できる。GeForce RTX 4070とするにはやや性能が近すぎるからだ。もちろんAda Lovelaceのホワイトペーパーにある数字は理論上のピーク性能であり、また描画性能そのものではないので、実際のゲームなどでは主にメモリー帯域の違いでもう少し性能差が出てくる可能性がある。
過去のコアのSM数(製品別ではなく、コアに本来実装されているSM数である)を比較したのが下表であるが、Ada Lovelaceの構成はTuringに近いのがわかる。
| SM数を比較したもの | ||||||
|---|---|---|---|---|---|---|
| Codename | Ada Lovelace(AD) | Ampere(GA) | Turing(TU) | Pascal(GP) | ||
| 102 | 144 | 84 | 72 | 30 | ||
| 103 | 96 | |||||
| 104 | 72 | 48 | 48 | 20 | ||
| 106 | 28 | 36 | 10 | |||
| 107 | 6 | |||||
| 108 | 3 | |||||
AD102はそのままTU102として、AD103をTU104、AD104をTU106に相当すると考えると、SM数の比率そのままである。そう考えると、AD103を使ったGeForce RTX 4080のコア構成は、TU104を使ったGeForce RTX 2080のSM数を倍増したような構成になると考えられるし、実際冒頭のホワイトペーパーで示したGeForce RTX 4080とGeForce RTX 2080の構成の比率はかなり近い。
(GeForce RTX 4070になるであろう)GeForce RTX 4080 12GB版の構成がわりとAD103に近いのは、グレード別に明確に差をつけるというよりはむしろ性能を隣接させることでGeForce RTX 4080 12GB版のお買い得感を高めて、こちらの売上を増やしたかったのではないか、と想像する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























