ロードマップでわかる!当世プロセッサー事情 第672回
Navi 3を2022年末、Instinct MI300を2023年に投入 AMD GPUロードマップ
2022年06月20日 12時00分更新

CPUからも自由にアクセスできるUnified Memory
RDNA 3を搭載するMI300の最大の特徴は、次に説明するUnified Memoryである。これはHBM Memoryを、MI300コアからだけでなく、CPUからも自由にアクセスできるというものだ。
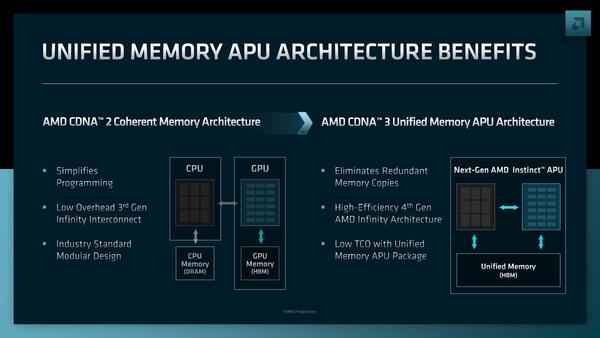
Unified Memoryの利点はCPUからも自由にアクセスできること。ただし、ホストCPUからHBMへのアクセスはPCIe Gen5経由なのでHBMのフルスピードではない
こちら明言はされていないが、Instinct MI300とほぼ同時期に投入されるGenoaコアのEPYCがCXL 2.0に対応しており、しかもメモリー拡張機能を持っていると明言されている。この結果として、CPUとGPUの協業が非常に容易になった。

そういえば前回はEPYCの話をするのを忘れていた。PCIe Gen5に加え、Sapphire Rapidsでは実装されていないと噂のCXL.memoryプロトコルにも対応。CXLメモリーを利用できる
非CXL環境では以下の手順だった。
- (1)CPUからデータをHost側メモリに書き込む
- (2)データをDMAでホスト側メモリーからアクセラレーター側メモリー(今回ならHBM)に書き込む
- (3)書き込まれたデータを利用してアクセラレーター(今回ならMI300)が処理する
- (4)処理結果(これもアクセラレーター側メモリー:今回ならHBM)をホスト側にDMA転送する
- (5)CPUがメモリーから結果を取り出す
これが以下のようになる。
- (1)CPUからデータをCXL経由でアクセラレーター側メモリー(今回ならHBM)に書き込む
- (2)書き込まれたデータを利用してアクセラレーター(今回ならMI300)が処理する
- (3)CPUが処理結果(これもアクセラレーター側メモリー:今回ならHBM)をCXL経由で取り込む
もちろんホストとアクセラレーター間の同期を取る作業はどちらでも必要になるが、これについてもCXL.ioで簡単に取れるので、処理そのものが非常に簡単になる。CXLの制限で、アクセラレーター(つまりMI300)が、直接ホストのメモリーに触ることはできないが、これはInstinct MI300の使い方を考えれば別にデメリットにはならないだろう。
CPUから見ると、Instinct MI300のHBMメモリーが、物理メモリーアドレスのどこかにマッピングされる形になっている。これは仮想記憶の対象ではないので、プログラムから使うためにはHBMの物理メモリーアドレスを自分の仮想メモリーアドレスにマッピングする必要があるが、このあたりは将来投入されるROCm 5でカバーされることになると思われる。
ちなみにこの機能が使えるのは、CXL 2.0のメモリープロトコルに対応したホストCPUのみである。当面はGenoaベース(つまりZen 4ベース)のEPYCのみ。Zen 4cベースのBergamoでもサポートされるかどうかは現時点ではっきりしない。
Bergamoはクラウドサーバー向けのEPYCなので、将来的にはCXLのアタッチドメモリーへの対応は必須だろうが、Instinct MI300を組み合わせるという使い方はされないであろうことを考えると、CXL 2.0をフルサポートするかどうかは不明である。
このInstinct MI300は2023年に市場投入とされる。

Instinct MI300は2023年に投入される。こちらではAI Training Performanceが8倍とある。内訳は、FP8のサポートで性能4倍、XCUの増加で1.5倍、Infinity Cacheの搭載などによる効率向上が1.3倍というあたりであろう
最初のターゲットとなるのは、ローレンス・リバモア国立研究所に導入されるスーパーコンピューターEl Capitanであろう。Frontierの構成のままノード数を増やしても2EFlopsの実現はそう難しくはないだろうが、やはりノード数が増えると実行効率が下がりがちなのは連載670回でも説明した通りだし、消費電力もシステム全体で30MW近くなる。おそらくEl Capitanでは、ノードあたりの性能を引き上げることで、ノード数そのものはFrontierと同等かむしろ少ないくらいで、2EFlopsを目指す構成になるのではないかと想像する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













